Command Palette
Search for a command to run...
DeepSeek-OCR: Contexts Optical Compression
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei Yaofeng Sun Yukun Li
Abstract
We present DeepSeek-OCR as an initial investigation into the feasibility of compressing long contexts via optical 2D mapping. DeepSeek-OCR consists of two components: DeepEncoder and DeepSeek3B-MoE-A570M as the decoder. Specifically, DeepEncoder serves as the core engine, designed to maintain low activations under high-resolution input while achieving high compression ratios to ensure an optimal and manageable number of vision tokens. Experiments show that when the number of text tokens is within 10 times that of vision tokens (i.e., a compression ratio < 10x), the model can achieve decoding (OCR) precision of 97%. Even at a compression ratio of 20x, the OCR accuracy still remains at about 60%. This shows considerable promise for research areas such as historical long-context compression and memory forgetting mechanisms in LLMs. Beyond this, DeepSeek-OCR also demonstrates high practical value. On OmniDocBench, it surpasses GOT-OCR2.0 (256 tokens/page) using only 100 vision tokens, and outperforms MinerU2.0 (6000+ tokens per page on average) while utilizing fewer than 800 vision tokens. In production, DeepSeek-OCR can generate training data for LLMs/VLMs at a scale of 200k+ pages per day (a single A100-40G). Codes and model weights are publicly accessible at http://github.com/deepseek-ai/DeepSeek-OCR.
One-sentence Summary
The authors propose DeepSeek-OCR, a novel end-to-end OCR system leveraging DeepEncoder for efficient 2D optical mapping to compress long documents, achieving state-of-the-art performance on OmniDocBench with only 100 vision tokens—surpassing GOT-OCR2.0 and MinerU2.0 while enabling scalable training data generation at 200k+ pages per day using a single A100-40G.
Key Contributions
-
This work investigates optical 2D mapping as a method for compressing long textual contexts into a compact visual representation, demonstrating that DeepSeek-OCR achieves 97% OCR precision at a compression ratio below 10× and maintains ~60% accuracy at 20×, validating the feasibility of vision-based text compression for long-context LLMs.
-
DeepEncoder, the core component, employs a novel architecture combining window attention, global attention, and a 16× convolutional token compressor to maintain low activation memory and minimize vision tokens even under high-resolution inputs, enabling efficient processing of dense document layouts.
-
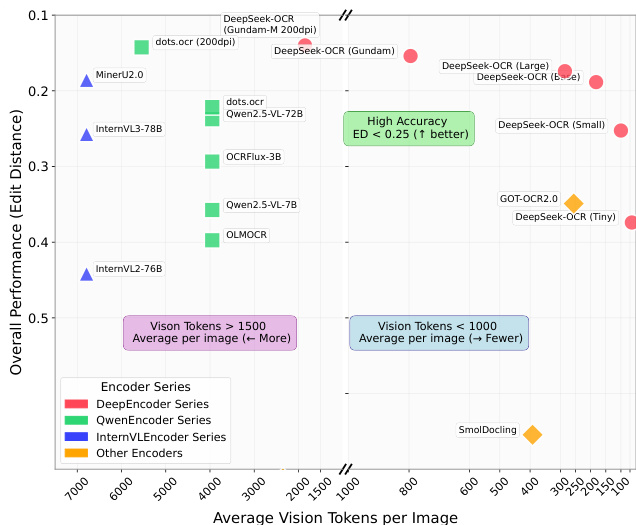
On OmniDocBench, DeepSeek-OCR outperforms state-of-the-art end-to-end models like GOT-OCR2.0 and MinerU2.0 while using significantly fewer vision tokens (under 800), and it scales to generate over 200k pages of training data per day on a single A100-40G GPU, showcasing strong practical utility for large-scale pretraining.
Introduction
The authors leverage vision-language models (VLMs) to explore optical compression of textual content, addressing the quadratic computational cost of long-context processing in large language models (LLMs). By treating visual representations as a compressed medium for text, they propose DeepSeek-OCR as a proof-of-concept system that achieves 9–12× text compression with over 90% OCR accuracy, demonstrating that vision tokens can efficiently encode dense textual information. Prior end-to-end OCR models, while effective, lack systematic analysis of minimal vision token requirements and struggle with high-resolution inputs due to memory and token explosion in standard vision encoders. The authors introduce DeepEncoder, a novel architecture that combines window attention, global attention, and a 16× convolutional compressor to maintain low activation memory and drastically reduce vision tokens, enabling efficient processing of high-resolution documents. Built on DeepSeek-3B-MoE, DeepSeek-OCR achieves state-of-the-art performance on OmniDocBench with minimal vision tokens and supports practical tasks like chart and formula parsing, enabling large-scale data generation at 33 million pages per day using 20 nodes. This work establishes a foundation for vision-text compression as a viable strategy to enhance LLM efficiency, with implications for long-context modeling and multimodal pretraining.
Dataset
-
The dataset for DeepSeek-OCR is composed of three main components: OCR 1.0 data (document and scene OCR), OCR 2.0 data (chart, chemical formula, and plane geometry parsing), general vision data, and text-only data, with a total training mix of 70% OCR data, 20% general vision data, and 10% text-only data.
-
OCR 1.0 data includes 30 million pages of multilingual PDFs (25M in Chinese and English, 5M in other languages), processed with coarse annotations from fitz for general text recognition and fine annotations for 2M pages each of Chinese and English using advanced layout (PP-DocLayout) and OCR models (MinuerU, GOT-OCR2.0). For minority languages, a model flywheel approach combines fitz-based patch labeling with a trained GOT-OCR2.0 to generate 600K samples. Additionally, 3M high-quality Word documents are used to support formula and table understanding, with no layout structure.
-
Natural scene OCR data consists of 10M Chinese and 10M English images from LAION and Wukong, labeled with PaddleOCR. These samples support both detection and recognition outputs, controlled via prompts.
-
OCR 2.0 data includes 10M chart images rendered via pyecharts and matplotlib, with labels in HTML table format to reduce token usage; 5M chemical formula images generated from PubChem SMILES using RDKit; and 1M plane geometry images created using Slow Perception with geometric translation-invariant augmentation to enhance diversity.
-
General vision data (20% of total) is derived from DeepSeek-VL2, covering captioning, detection, and grounding tasks, designed to preserve general vision capabilities without making DeepSeek-OCR a general-purpose VLM.
-
Text-only data (10% of total) consists of in-house pretraining data, all tokenized to 8192 tokens to match the model’s sequence length, ensuring strong language modeling.
-
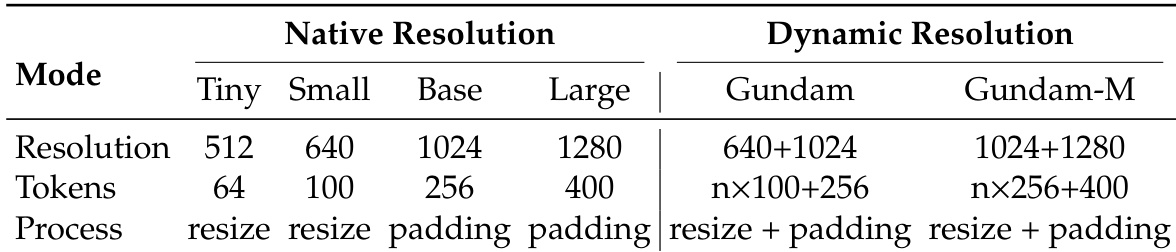
The model is trained using multiple resolution modes: four native resolutions (Tiny: 512×512, Small: 640×640, Base: 1024×1024, Large: 1280×1280) with dynamic interpolation of positional encodings. For Base and Large modes, images are padded to maintain aspect ratio, with valid vision tokens calculated based on original image dimensions. Tiny and Small modes use direct resizing.
-
Dynamic resolution mode, such as Gundam mode, combines local 640×640 tiles (n tiles) with a 1024×1024 global view, producing n×100 + 256 vision tokens. When input size is below 640×640, the mode defaults to Base. Gundam mode is trained alongside native modes, with Gundam-master (1024×1024 local + 1280×1280 global) introduced via continued training for load balancing.
-
All data is processed with normalized coordinates (1000 bins), and fine annotations are formatted as interleaved layout and text sequences. Ground truth for complex layouts and parsing tasks is structured for efficient decoding and model training.
Method
The authors leverage a unified end-to-end vision-language model (VLM) architecture for optical character recognition (OCR), composed of a specialized vision encoder and a decoder. The framework, as illustrated in the diagram below, consists of two primary components: DeepEncoder, which processes the input image, and the DeepSeek-3B-MoE decoder, which generates the textual output based on the compressed visual representation and any provided prompt. This architecture is designed to achieve high compression ratios while maintaining low activation memory, particularly for high-resolution inputs.

DeepEncoder, the core vision encoder, is a novel design tailored to address the limitations of existing vision encoders. It is composed of two main components: a visual perception feature extraction module and a visual knowledge feature extraction module. The first module, dominated by window attention, is based on a 80M SAM-base model with a patch size of 16. The second module, which handles dense global attention, is built upon a 300M CLIP-large model. These two components are connected in series. To reduce the number of vision tokens and control activation memory, a 2-layer convolutional module is employed between them, performing a 16× downsampling of the vision tokens. This compression step is crucial for managing the computational load, as it reduces the token count from 4096 (for a 1024×1024 image) to 256, resulting in low activation memory.
The decoder is a 3B Mixture-of-Experts (MoE) model, specifically DeepSeek-3B-MoE, which activates approximately 570M parameters during inference. This architecture allows the model to achieve the expressive power of a 3B model while maintaining the inference efficiency of a smaller model. The decoder's function is to reconstruct the original text representation from the compressed latent vision tokens produced by DeepEncoder. This is formalized as a non-linear mapping fdec:Rn×dlatent→RN×dtext, where Z∈Rn×dlatent represents the compressed vision tokens and X^∈RN×dtext is the reconstructed text output.
The training process for DeepSeek-OCR is conducted in two stages. First, the DeepEncoder is trained independently using a next token prediction framework. This stage utilizes a diverse dataset, including OCR 1.0 and 2.0 data, as well as 100 million general images sampled from the LAION dataset. The training is performed for 2 epochs with a batch size of 1280, using the AdamW optimizer with a cosine annealing scheduler and a learning rate of 5e-5. The sequence length for training is set to 4096. In the second stage, the entire DeepSeek-OCR model, including the pre-trained DeepEncoder and the decoder, is trained jointly. This two-stage approach allows for the efficient and effective training of the model.
Experiment
- Trained DeepSeek-OCR on HAI-LLM using pipeline parallelism across 20 nodes (8 A100-40G GPUs each), achieving 90B tokens/day for text-only and 70B tokens/day for multimodal data, with AdamW optimizer and initial learning rate of 3e-5.
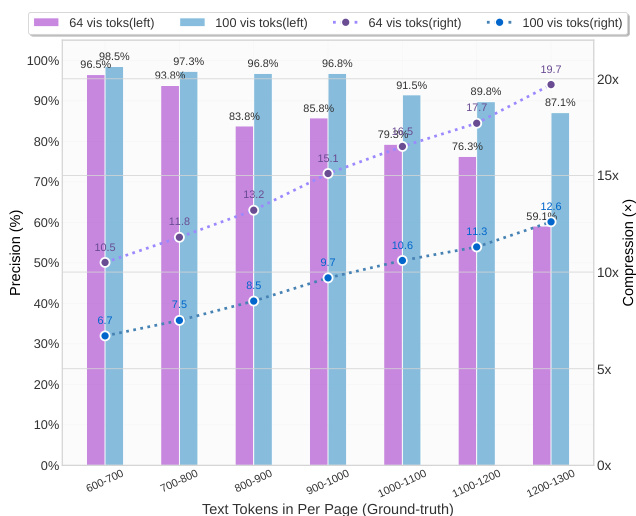
- On Fox benchmark, DeepSeek-OCR achieves ~97% decoding precision at 10× vision-text compression ratio, with performance dropping beyond 10× due to layout complexity and text blurring at fixed resolutions; at 20× compression, precision remains around 60%, indicating strong potential for lossless and near-lossless optical context compression.
- On OmniDocBench, DeepSeek-OCR surpasses GOT-OCR2.0 using only 100 vision tokens (640×640) and matches state-of-the-art performance with 400 tokens (1280×1280), outperforming MinerU2.0 which requires ~7,000 tokens, demonstrating high practical efficiency.
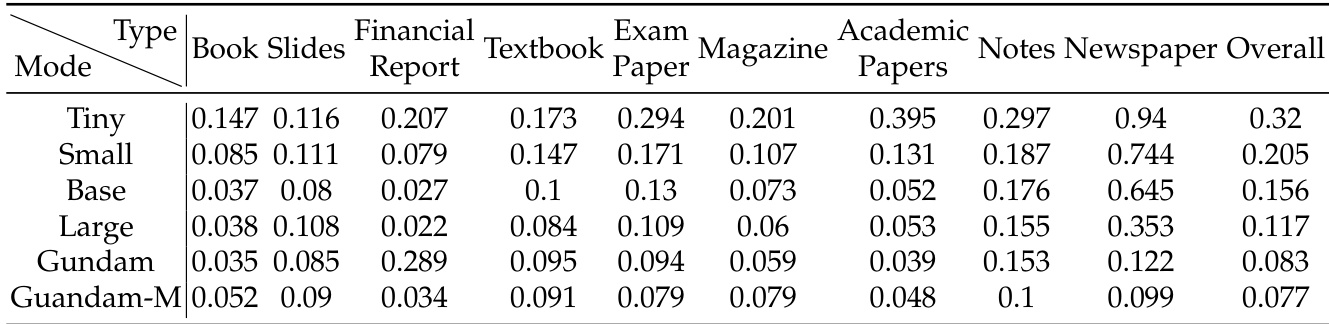
- For document categories, slides require only 64 vision tokens, books and reports perform well with 100 tokens, while newspapers need Gundam or Gundam-master mode due to high text density (4,000–5,000 tokens), highlighting compression boundaries tied to document complexity.
- DeepSeek-OCR retains general vision understanding (image description, object detection, grounding) and language capabilities without SFT, enabling context-aware processing and supporting future applications in scalable long-context modeling.
- The vision-text compression approach simulates human-like forgetting mechanisms by progressively downsizing rendered historical text images, enabling multi-level compression that reduces token count and blurs older content, offering a biologically inspired path toward efficient, scalable long-context architectures.
The authors use DeepSeek-OCR to study vision-text compression, testing its ability to decode text from compressed visual representations. Results show that the model achieves approximately 97% decoding precision at a 10× compression ratio, with performance declining beyond this point, though it still maintains around 60% accuracy at nearly 20× compression.

Results show that DeepSeek-OCR achieves varying levels of performance across different document types, with smaller modes like Tiny and Small performing well on documents such as slides and books, while more complex documents like newspapers require higher modes such as Gundam or Gundam-M to achieve acceptable edit distances. The model demonstrates strong practical OCR capabilities, surpassing state-of-the-art methods with significantly fewer vision tokens, indicating efficient vision-text compression.
Results show that DeepSeek-OCR achieves high accuracy with fewer vision tokens compared to other models, particularly in the Tiny and Small modes, where it outperforms models like GOT-OCR2.0 and MinerU2.0 while using significantly fewer tokens. The model demonstrates strong performance across different document types, with some categories like slides requiring only 64 vision tokens, while more complex documents like newspapers need higher token counts, indicating a trade-off between compression ratio and accuracy.
The authors use DeepSeek-OCR to test vision-text compression ratios on English documents from the Fox benchmark, evaluating performance across different modes defined by resolution and token count. Results show that with 64 or 100 vision tokens, the model achieves high decoding precision, reaching approximately 97% at a 10× compression ratio, while performance declines beyond this point due to increased layout complexity and text blurring at lower resolutions.
Results show that DeepSeek-OCR achieves high precision in vision-text compression, with decoding accuracy above 96% for text-rich documents containing 600–700 tokens when using 64 or 100 vision tokens. As the number of text tokens per page increases beyond 1,000, precision declines, particularly at higher compression ratios, indicating limitations in preserving fine-grained text details at lower vision token counts.