Command Palette
Search for a command to run...
SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity
SoulX-Podcast: Towards Realistic Long-form Podcasts with Dialectal and Paralinguistic Diversity
Abstract
Recent advances in text-to-speech (TTS) synthesis have significantly improved speech expressiveness and naturalness. However, most existing systems are tailored for single-speaker synthesis and fall short in generating coherent multi-speaker conversational speech. This technical report presents SoulX-Podcast, a system designed for podcast-style multi-turn, multi-speaker dialogic speech generation, while also achieving state-of-the-art performance in conventional TTS tasks. To meet the higher naturalness demands of multi-turn spoken dialogue, SoulX-Podcast integrates a range of paralinguistic controls and supports both Mandarin and English, as well as several Chinese dialects, including Sichuanese, Henanese, and Cantonese, enabling more personalized podcast-style speech generation. Experimental results demonstrate that SoulX-Podcast can continuously produce over 90 minutes of conversation with stable speaker timbre and smooth speaker transitions. Moreover, speakers exhibit contextually adaptive prosody, reflecting natural rhythm and intonation changes as dialogues progress. Across multiple evaluation metrics, SoulX-Podcast achieves state-of-the-art performance in both monologue TTS and multi-turn conversational speech synthesis.
One-sentence Summary
The authors from Northwestern Polytechnical University, Soul AI Lab, and Shanghai Jiao Tong University propose SoulX-Podcast, a novel multi-speaker conversational TTS system that enables natural, context-aware, and long-form podcast-style speech generation with support for Mandarin, English, and multiple Chinese dialects, leveraging advanced paralinguistic controls and speaker consistency mechanisms to achieve state-of-the-art performance in both monologue and multi-turn dialogue synthesis.
Key Contributions
- SoulX-Podcast addresses the challenge of generating natural, long-form multi-speaker conversational speech by introducing a large language model-driven framework that models interleaved text-speech sequences with speaker labels, enabling coherent, context-aware dialogue synthesis across multiple turns.
- The system supports a diverse range of languages and dialects—including Mandarin, English, Sichuanese, Henanese, and Cantonese—and enables cross-dialectal zero-shot voice cloning, allowing a single audio prompt to generate speech in any supported dialect with consistent speaker identity.
- Experimental results show that SoulX-Podcast can generate over 90 minutes of stable, high-quality conversational speech with smooth speaker transitions and contextually adaptive prosody, achieving state-of-the-art performance in both multi-turn dialogue synthesis and conventional text-to-speech tasks.
Introduction
The authors leverage large language models (LLMs) and discrete speech tokenization to advance text-to-speech (TTS) synthesis, addressing a key gap in multi-speaker, long-form conversational speech generation. While prior TTS systems excel in single-speaker, monologue synthesis, they struggle with maintaining natural prosody, speaker consistency, and coherence across extended dialogues—especially in diverse linguistic contexts. Existing approaches for multi-speaker dialogue either lack fine-grained paralinguistic control or fail to support dialectal variation, limiting realism and personalization. To overcome these limitations, the authors introduce SoulX-Podcast, a unified framework that enables long-form, multi-turn podcast-style speech synthesis with support for Mandarin, English, and multiple Chinese dialects—including Sichuanese, Henanese, and Cantonese—while enabling cross-dialectal zero-shot voice cloning. The system models interleaved text-speech sequences with speaker labels and paralinguistic controls, ensuring stable speaker identity, context-aware prosody, and smooth transitions. It achieves state-of-the-art performance in both conversational synthesis and conventional TTS tasks, demonstrating robustness and versatility in generating over 90 minutes of natural, coherent dialogue.
Dataset
- The dataset comprises approximately 0.3 million hours of natural conversational speech and about 1.0 million hours of monologue data, totaling roughly 1.3 million hours of high-quality speech for training.
- Conversational data is sourced from public podcast recordings and in-the-wild speech, with dialectal and paralinguistic annotations added through a two-stage process.
- For paralinguistic annotation, the authors first use language-specific ASR models—Beats for Mandarin and Whisperd for English—to perform coarse detection of nonverbal cues like laughter and sighs.
- In the second stage, the Gemini-2.5-Pro API is used to verify and refine these detections, generating precise, time-aligned paralinguistic labels with fine-grained categorization.
- This process results in approximately 1,000 hours of speech with detailed paralinguistic annotations.
- Dialectal data is collected via two methods: direct acquisition of public recordings in Sichuanese, Cantonese, and Henanese, and dialect identification using a trained model to extract dialectal utterances from broader datasets.
- Transcriptions for dialectal speech are generated using the Seed-ASR API due to the limitations of standard ASR pipelines, yielding approximately 2,000 hours of Sichuanese, 1,000 hours of Cantonese, and 500 hours of Henanese speech.
- The dataset is used to train the SoulX-Podcast model, with the conversational and monologue subsets combined in a mixture ratio optimized for expressive, context-aware dialogue synthesis.
- No explicit cropping is mentioned, but the data undergoes careful filtering and alignment during annotation to ensure high fidelity and temporal precision.
- Metadata for dialect and paralinguistic cues is constructed during the annotation process, enabling fine-grained control over speech output during synthesis.
Method
The authors leverage a two-stage generative framework for long-form, multi-speaker, and multi-dialect conversational speech synthesis, as illustrated in the architecture diagram. This framework, named SoulX-Podcast, begins with a large language model (LLM) that predicts semantic tokens, which are then converted into acoustic features via flow matching and finally synthesized into waveform audio using a vocoder. The LLM backbone is derived from the pre-trained Qwen3-1.7B model, with its text codebook extended to include speech tokens and special tokens for encoding paralinguistic and dialectal attributes.
Refer to the framework diagram 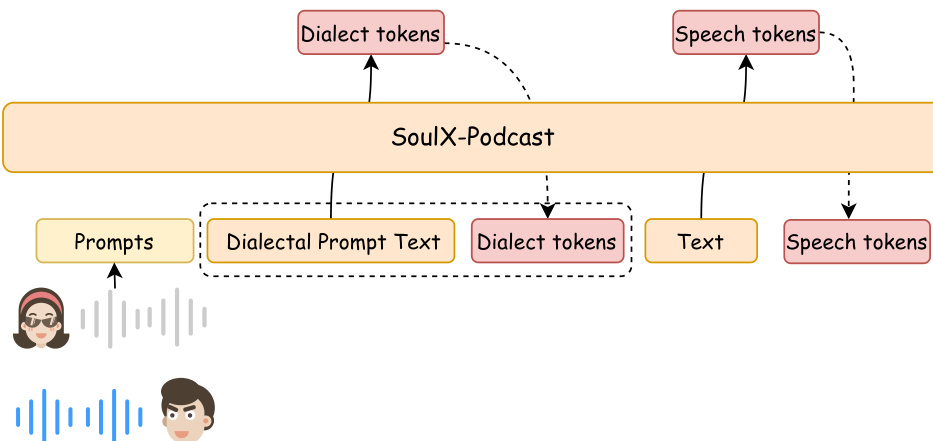 .
.
The model employs an interleaved text-speech token organization to enable flexible, multi-turn dialogue generation. Each utterance in the sequence begins with a speaker token to indicate identity, followed by a dialect-specific token for dialect control, and then the text tokens. Paralinguistic cues are treated as textual tokens and placed at their corresponding positions within the sequence. This structure allows for the synthesis of speech with consistent speaker identity, dialectal characteristics, and paralinguistic expressions in a coherent, turn-by-turn manner.
The training process follows a curriculum learning strategy to effectively leverage heterogeneous data patterns. Initially, the LLM backbone is trained on a mixture of monologue and dialogue data to establish fundamental text-to-speech capabilities. Subsequently, the model is further trained on multi-speaker dialogue data in both Chinese and English, incorporating dialectal and paralinguistic elements. To address the scarcity of Chinese dialect data, additional fine-tuning is performed specifically on dialectal data to enhance the model's dialectal generation capability. To manage the challenges of long-form audio generation, a context regularization mechanism is introduced, which progressively drops historical speech tokens while retaining their textual context. This encourages the model to rely on semantic continuity rather than low-level acoustic memory, improving coherence and stability in extended conversational synthesis.
As shown in the figure below:  .
.
During inference, the model follows the same token organization established during training, autoregressively generating speech tokens in an interleaved manner with text tokens from multiple speakers. For cross-dialectal voice cloning, the authors propose a Dialect-Guided Prompting (DGP) strategy to address the weak control signal when generating a target dialect from a Mandarin prompt. This involves prepending a short, dialect-typical sentence to the input text, which effectively guides the model to produce speech with the desired dialectal characteristics in subsequent generations.
Experiment
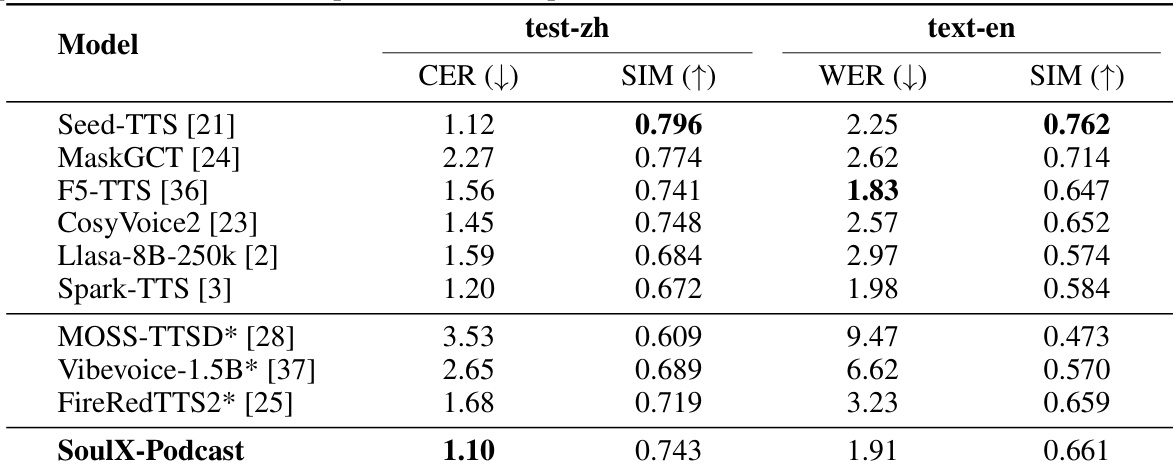
- Evaluated SoulX-Podcast on monologue speech synthesis: achieved lowest CER on Chinese test set and second-best WER on English test set in zero-shot TTS, with high speaker similarity ranking just behind Seed-TTS and MaskGCT on both languages.
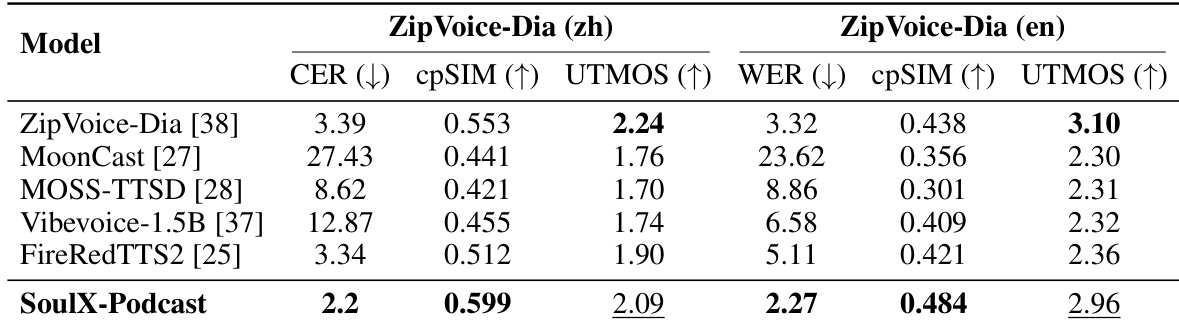
- Demonstrated superior performance in multi-turn, multi-speaker podcast generation: achieved the lowest WER/CER and highest cross-speaker similarity (cpSIM) on the ZipVoice-Dia test set, with competitive UTMOS scores.
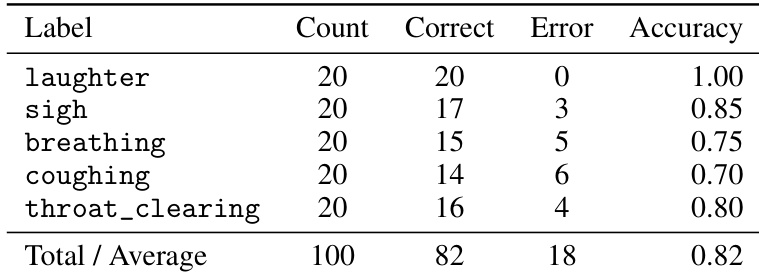
- Validated paralinguistic control: achieved 82% overall recognition accuracy for five paralinguistic events, with near-perfect control for and high fidelity for and <throat_clearing>, though lower accuracy for subtle events like (75%) and (70%).
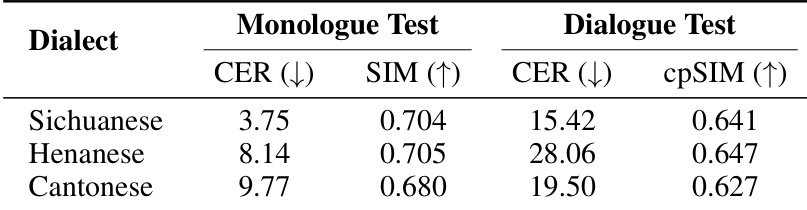
- Showed strong dialectal capability across Sichuanese, Henanese, and Cantonese: maintained consistent speaker similarity comparable to Mandarin and English, with high CER values likely due to ASR system limitations.
Results show that SoulX-Podcast achieves strong control over paralinguistic events, with an overall recognition accuracy of 0.82 across five labels. The model performs near-perfectly on laughter and demonstrates high fidelity for sigh and throat clearing, though accuracy is lower for more subtle events like breathing and coughing.
Results show that SoulX-Podcast outperforms existing multi-speaker TTS systems on the ZipVoice-Dia benchmark, achieving the lowest CER and WER while maintaining the highest cross-speaker consistency (cpSIM) and competitive UTMOS scores in both Chinese and English. This indicates superior performance in multi-turn dialogue generation with strong speaker coherence and high perceptual quality.
The authors evaluate SoulX-Podcast's performance on three Chinese dialects—Sichuanese, Henanese, and Cantonese—in both monologue and dialogue settings. Results show consistent speaker similarity across all dialects, with CER values indicating varying levels of intelligibility, where Sichuanese achieves the lowest CER in monologue synthesis and Cantonese shows the highest in dialogue synthesis.
Results show that SoulX-Podcast achieves the lowest CER on the Chinese test set and ranks second in the English test set, demonstrating strong performance in zero-shot monologue speech synthesis. It also achieves high speaker similarity, ranking just behind Seed-TTS and MaskGCT in both language evaluations.