Command Palette
Search for a command to run...
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Abstract
The landscape of high-performance image generation models is currently dominated by proprietary systems, such as Nano Banana Pro and Seedream 4.0. Leading open-source alternatives, including Qwen-Image, Hunyuan-Image-3.0 and FLUX.2, are characterized by massive parameter counts (20B to 80B), making them impractical for inference, and fine-tuning on consumer-grade hardware. To address this gap, we propose Z-Image, an efficient 6B-parameter foundation generative model built upon a Scalable Single-Stream Diffusion Transformer (S3-DiT) architecture that challenges the "scale-at-all-costs" paradigm. By systematically optimizing the entire model lifecycle -- from a curated data infrastructure to a streamlined training curriculum -- we complete the full training workflow in just 314K H800 GPU hours (approx. $630K). Our few-step distillation scheme with reward post-training further yields Z-Image-Turbo, offering both sub-second inference latency on an enterprise-grade H800 GPU and compatibility with consumer-grade hardware (<16GB VRAM). Additionally, our omni-pre-training paradigm also enables efficient training of Z-Image-Edit, an editing model with impressive instruction-following capabilities. Both qualitative and quantitative experiments demonstrate that our model achieves performance comparable to or surpassing that of leading competitors across various dimensions. Most notably, Z-Image exhibits exceptional capabilities in photorealistic image generation and bilingual text rendering, delivering results that rival top-tier commercial models, thereby demonstrating that state-of-the-art results are achievable with significantly reduced computational overhead. We publicly release our code, weights, and online demo to foster the development of accessible, budget-friendly, yet state-of-the-art generative models.
One-sentence Summary
The Z-Image Team at Alibaba Group proposes a 6B-parameter generative model, Z-Image, built on a Scalable Single-Stream Diffusion Transformer (S3-DiT) architecture that achieves state-of-the-art performance in photorealistic image generation and bilingual text rendering with significantly reduced computational cost. By optimizing the full training lifecycle and introducing a few-step distillation scheme, Z-Image-Turbo enables sub-second inference on enterprise GPUs and runs on consumer hardware (<16GB VRAM), challenging the scale-at-all-costs paradigm. The omni-pre-training approach further supports Z-Image-Edit, a versatile editing model with strong instruction-following ability. The model demonstrates competitive or superior results to leading proprietary and open-source systems, with publicly released code, weights, and demos to advance accessible, high-performance generative AI.
Key Contributions
-
The paper addresses the challenge of high computational cost and hardware inaccessibility in state-of-the-art image generation models, proposing Z-Image, a 6B-parameter foundation model built on a Scalable Single-Stream Diffusion Transformer (S3-DiT) architecture that breaks the "scale-at-all-costs" paradigm by enabling efficient training and inference on consumer-grade hardware.
-
The authors introduce a comprehensive optimization pipeline spanning data curation, training efficiency, and a few-step distillation with reward post-training, resulting in Z-Image-Turbo, which achieves sub-second inference latency on enterprise GPUs and runs on devices with under 16GB VRAM, while maintaining high-quality outputs.
-
Extensive evaluations demonstrate that Z-Image matches or exceeds leading models in photorealistic generation and bilingual text rendering, with strong instruction-following capabilities in Z-Image-Edit, validated through human preference and quantitative benchmarks across diverse tasks.
Introduction
The landscape of text-to-image generation is dominated by large, proprietary models with limited transparency and open-source alternatives that rely on massive parameter counts (20B–80B), making them impractical for inference and fine-tuning on consumer hardware. Prior work often compounds this issue by distilling synthetic data from closed models, risking data homogenization and limiting innovation. To address these challenges, the authors introduce Z-Image, a 6B-parameter foundation model built on a Scalable Single-Stream Diffusion Transformer (S3-DiT) architecture that enables efficient, end-to-end training and inference without relying on distillation. By optimizing the full model lifecycle—from a curated data infrastructure with active curation and world knowledge graphs to a progressive training curriculum and few-step distillation with reinforcement learning—the authors achieve state-of-the-art performance with only 314K H800 GPU hours (~$630K). The resulting Z-Image-Turbo delivers sub-second inference on enterprise GPUs and runs on consumer hardware (<16GB VRAM), while Z-Image-Edit excels in instruction-following image editing. The model demonstrates superior photorealism and bilingual text rendering, proving that high performance is achievable with significantly reduced computational overhead.
Dataset
- The dataset is constructed from a large-scale, uncurated internal collection of copyrighted image-text pairs, processed through a multi-stage Data Profiling Engine to ensure high quality and diversity.
- Key subsets are derived from diverse sources including web-crawled media, internal media pools, and video frames, with filtering applied via source-specific heuristics to balance representation and mitigate bias.
- Each image-text pair undergoes comprehensive profiling across multiple dimensions:
- Image Metadata: Resolution, file size, and perceptual hash (pHash) are computed for efficient deduplication and resolution-based filtering.
- Technical Quality Assessment: Images are filtered based on compression artifacts (via file size vs. ideal size ratio), visual degradation (using an in-house quality model scoring blur, color cast, noise, and watermarks), and low information entropy (via border pixel variance and JPEG re-encoding BPP).
- Semantic and Aesthetic Content: Aesthetic quality is scored using a model trained on professional annotations; AI-generated content is detected and filtered using a dedicated classifier; high-level semantic tags are generated via a Vision-Language Model (VLM), including object categories, human attributes, and culturally specific concepts (especially Chinese cultural elements), with NSFW scoring for safety filtering.
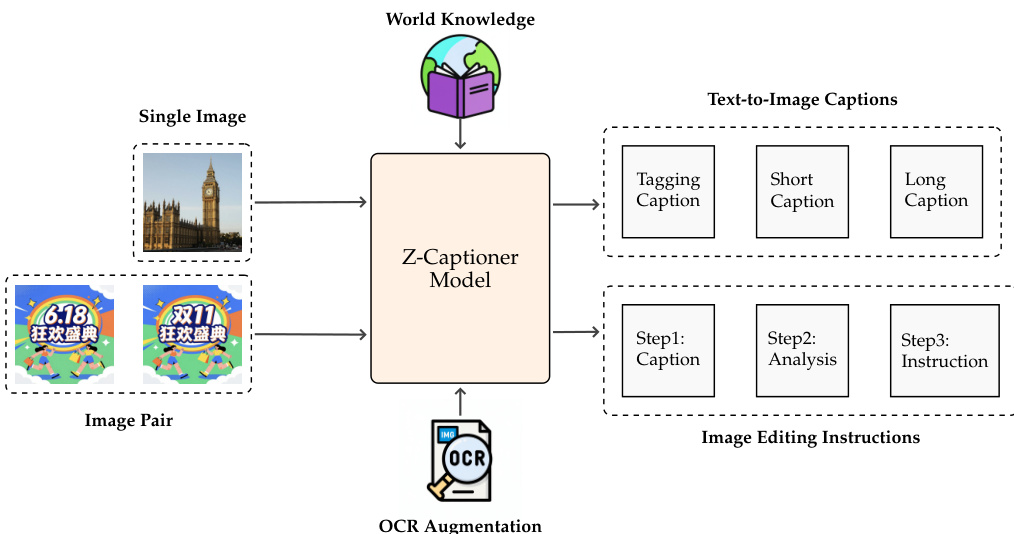
- Cross-Modal Consistency: Image-caption alignment is evaluated using CN-CLIP; low-correlation pairs are discarded. Captions are generated at multiple levels—tags, short phrases, and long-form descriptions—using the same VLM, which also extracts visible text and watermarks directly from images, eliminating the need for separate OCR or watermark detection modules.
- The dataset is used in training with a carefully balanced mixture of data subsets, guided by a World Knowledge Topological Graph that maps semantic tags to hierarchical concepts. Sampling weights are computed using BM25 scores and parent-child relationships in the graph, enabling fine-grained control over training distribution.
- A multi-level captioning strategy is employed: long captions include dense factual details (objects, location, OCR, background), while short captions and simulated user prompts mimic real-world, often incomplete, user queries to improve model adaptability.
- For image editing tasks, training pairs are constructed using three scalable strategies:
- Mixed Editing with Expert Models: Task-specific models generate diverse editing actions, which are combined into composite pairs to improve training efficiency.
- Efficient Graphical Representation: From one input image and N edited versions, up to 2(2N+1) pairs are generated via arbitrary permutation, enabling mixed-editing and inverse pairs (real → distorted) at no additional cost.
- Paired Images from Videos: Video frames are grouped by inherent visual relationships, and high-similarity pairs are selected using CN-CLIP embeddings, yielding diverse, multi-edit, and naturally coupled image pairs.
- Controllable Text Rendering: A text rendering system generates paired images with precise control over text content, font, color, size, and position, enabling high-quality, annotated data for text editing.
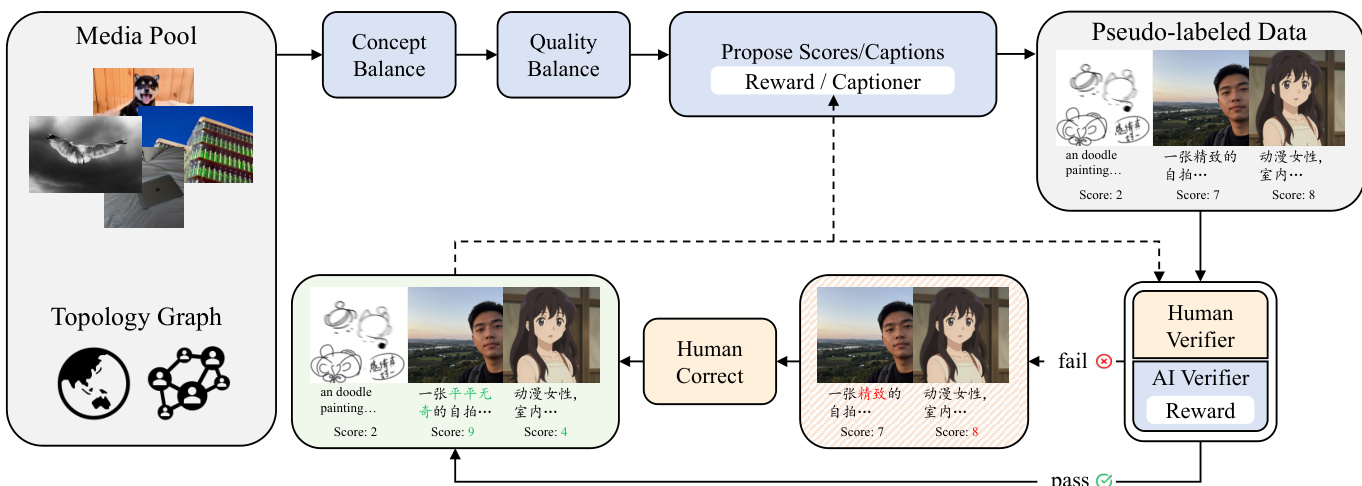
- The Active Curation Engine employs a human-in-the-loop cycle: pseudo-labeled data is verified by both AI and human experts; rejected samples trigger manual correction, and refined data is used to retrain the captioner and reward model, creating a feedback loop that continuously improves data quality and coverage.
- A feedback mechanism using the Z-Image model identifies long-tail concept deficiencies (e.g., “Squirrel Fish” dish), prompting targeted retrieval and augmentation to strengthen underrepresented knowledge areas.
Method
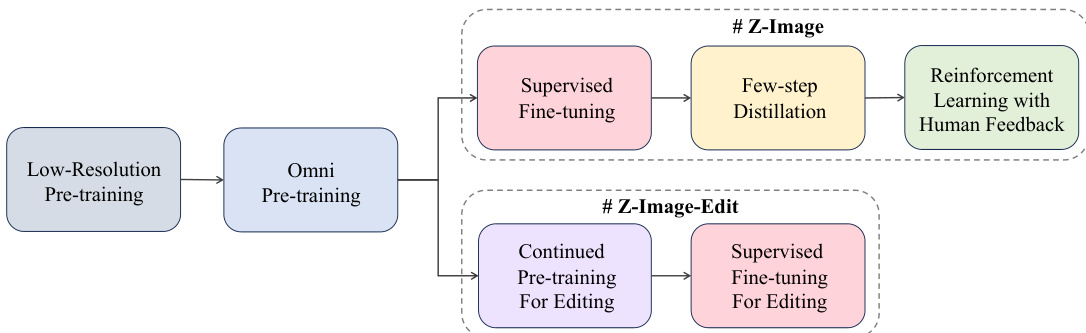
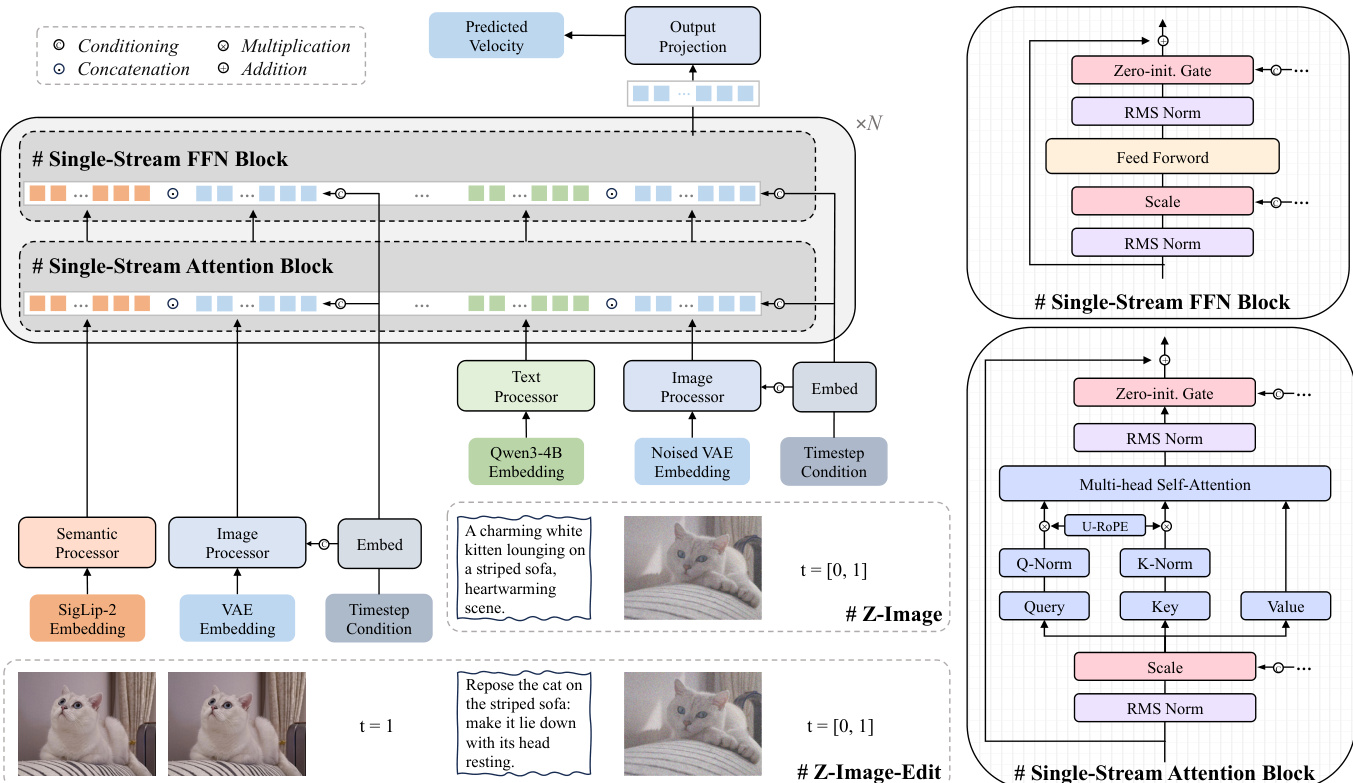
The authors present a comprehensive training pipeline for the Z-Image series, centered on a scalable single-stream diffusion transformer (S3-DiT) architecture designed for efficiency and stability. The overall framework, as illustrated in Figure 5, begins with a multi-stage training process that first establishes a robust foundation through pre-training, followed by refinement stages to enhance quality, efficiency, and alignment with human preferences. The pipeline is bifurcated to train both the base text-to-image model, Z-Image, and its specialized editing counterpart, Z-Image-Edit, with the latter leveraging the former's capabilities through continued pre-training.
The core of the model architecture is the S3-DiT, which is detailed in Figure 4. This architecture employs a single-stream paradigm, where text, visual semantic, and VAE image tokens are concatenated into a unified sequence, maximizing parameter efficiency compared to dual-stream approaches. The model is built upon lightweight modality-specific processors—Qwen3-4B for text and Flux VAE for image tokenization—which first align the inputs before they are fed into the unified backbone. This backbone consists of a series of single-stream attention and feed-forward network (FFN) blocks. To ensure training stability, the authors implement QK-Norm to regulate attention activations and Sandwich-Norm to constrain signal amplitudes at the input and output of each block. Conditional information, such as text and image embeddings, is injected via a low-rank projection mechanism that generates scale and gate parameters to modulate the normalized inputs and outputs of the attention and FFN layers. The entire architecture is built upon a foundation of RMSNorm for all normalization operations.
The training process is structured into several distinct phases. It commences with a low-resolution pre-training stage at 2562 resolution, which focuses on efficient cross-modal alignment and knowledge injection. This is followed by an omni-pre-training phase, which introduces three key innovations: arbitrary-resolution training, joint text-to-image and image-to-image training, and multi-level, bilingual caption training. This phase enables the model to learn cross-scale visual information and provides a strong initialization for downstream tasks like image editing. The model is then refined through supervised fine-tuning (SFT), where the distribution is narrowed towards a high-fidelity sub-manifold using highly curated data and a dynamic resampling strategy guided by a world knowledge topological graph to prevent catastrophic forgetting. To achieve real-time inference, a few-step distillation stage is employed, which teaches a student model to mimic the teacher's denoising dynamics across fewer timesteps. This process is enhanced by two key technical advancements: Decoupled DMD, which resolves detail and color degradation by decoupling the renoising schedules for the primary distillation engine and the regularizer, and DMDR, which combines reinforcement learning with the distribution matching regularizer to unlock the student model's capacity while preventing reward hacking. Finally, the model undergoes reinforcement learning with human feedback (RLHF), which uses a multi-dimensional reward model to optimize for instruction-following, aesthetic quality, and AI-content detection perception, further refining the model's alignment with nuanced human preferences.
Experiment
- Multi-faceted training efficiency optimizations, including hybrid parallelization (DP for VAE and Text Encoder, FSDP2 for DiT), gradient checkpointing, torch.compile, and sequence length-aware dynamic batching, significantly reduce memory usage and improve throughput across varying resolutions.
- Decoupled DMD and DMDR distillation enables 8-step inference with Z-Image-Turbo that matches or surpasses 100-step teacher performance in visual quality and aesthetic appeal, resolving the speed-fidelity trade-off.
- Online reinforcement learning with GRPO enhances photorealism, aesthetic quality, and instruction-following by leveraging a composite reward function, achieving superior balance across multiple quality dimensions.
- Prompt Enhancer with reasoning chain improves Z-Image’s world knowledge and complex reasoning, enabling accurate scene inference from coordinates and step-by-step planning for tasks like tea brewing, significantly enhancing prompt understanding.
- On CVTG-2K, Z-Image achieves 0.8671 Word Accuracy, outperforming GPT-Image-1 (0.8569) and Qwen-Image (0.8288), with consistent performance across 2–5 text regions; Z-Image-Turbo attains 0.8048 CLIP Score and 0.8585 Word Accuracy.
- On LongText-Bench, Z-Image scores 0.935 (EN) and 0.936 (ZH), ranking third and second respectively; Z-Image-Turbo scores 0.917 (EN) and 0.926 (ZH), demonstrating strong bilingual efficiency.
- On OneIG, Z-Image achieves 0.987 (EN) and 0.988 (ZH) text accuracy, setting new SOTA in reliability, and ranks second on Chinese track (0.535).
- On GenEval, Z-Image scores 0.84 (tied for second), with Z-Image-Turbo at 0.82, showing strong object-centric generation.
- On DPG-Bench, Z-Image scores 88.14 (third), with 93.16 in Attribute dimension, outperforming Qwen-Image (92.02) and Seedream 3.0 (91.36).
- On TIIF, Z-Image and Z-Image-Turbo rank 4th and 5th, demonstrating strong instruction-following across diverse categories.
- On PRISM-Bench, Z-Image-Turbo ranks 3rd (77.4) on English track and 2nd (75.3) on Chinese track, excelling in Text Rendering (83.4) and Composition (88.6).
- On ImgEdit, Z-Image-Edit shows competitive performance, particularly in object addition and extraction, with strong overall editing capability.
- On GEdit-Bench, Z-Image-Edit achieves 3rd rank, demonstrating robust bilingual editing in visual naturalness and instruction following.
- Qualitative results show superior photorealism in close-ups, scene authenticity, and aesthetic layout, with Z-Image-Turbo outperforming open- and closed-source models in skin texture, expression, and environmental realism.
- Z-Image-Turbo achieves state-of-the-art bilingual text rendering in posters and complex typography, accurately rendering both Chinese and English text with high aesthetic fidelity.
- Z-Image-Edit demonstrates precise control in composite editing tasks, including background changes, object insertion/removal, and text editing with spatial constraints, while preserving identity.
- Z-Image exhibits emerging multi-lingual and multi-cultural understanding, accurately generating culturally relevant scenes and landmarks from multilingual prompts.
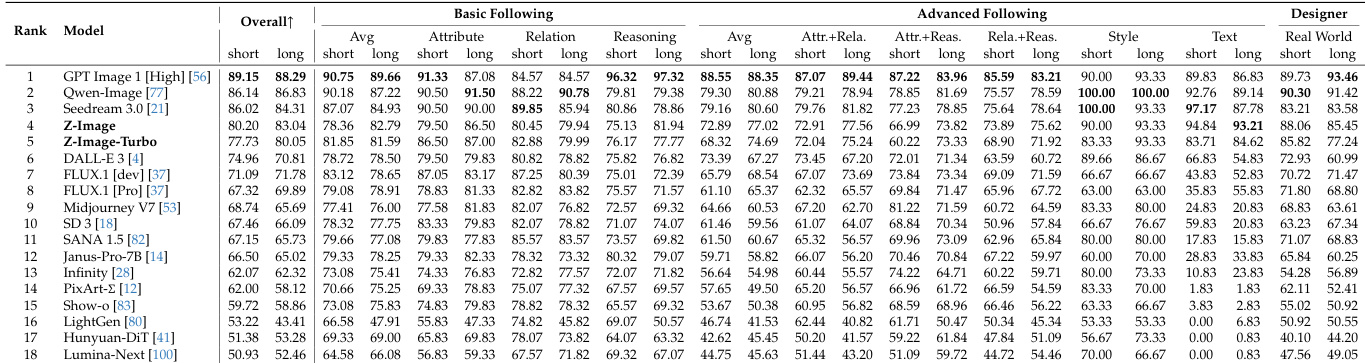
The authors evaluate Z-Image-Turbo on the TIIF benchmark, where it achieves the 4th rank among all models. Results show that Z-Image-Turbo demonstrates strong instruction-following capabilities, performing competitively with leading models despite its smaller size.
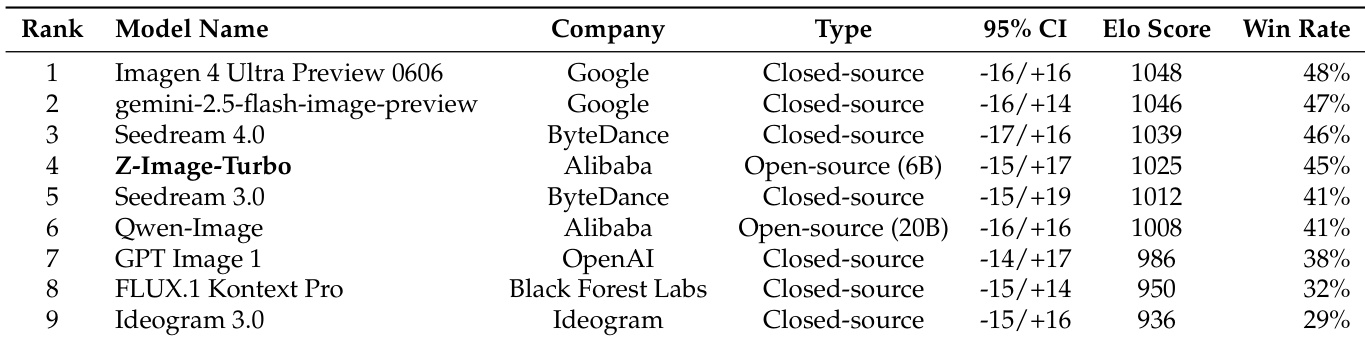
Results show that Z-Image-Edit achieves the highest overall score of 4.30 on the ImgEdit benchmark, outperforming all other models in the comparison. It demonstrates particularly strong performance in object addition, adjustment, and extraction tasks, with top rankings in several individual editing categories.
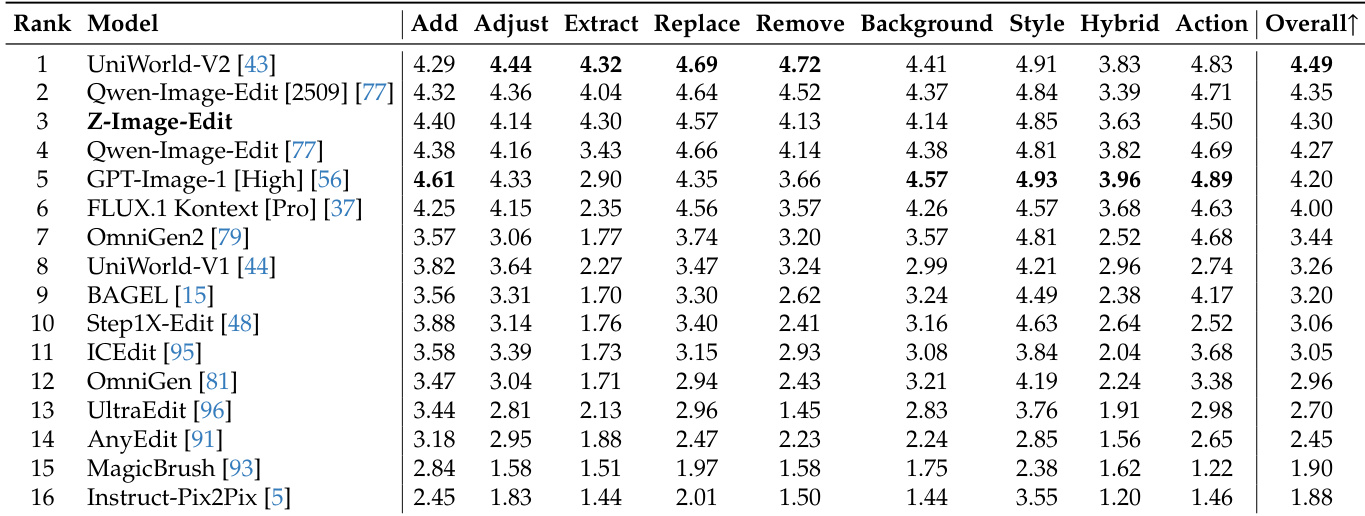
Results show that Z-Image-Edit achieves a G Rate of 46.4%, an S Rate of 41.0%, and a B Rate of 12.6%, with a combined G+S Rate of 87.4% on the GEdit-Bench, indicating strong performance in both visual naturalness and bilingual instruction following.

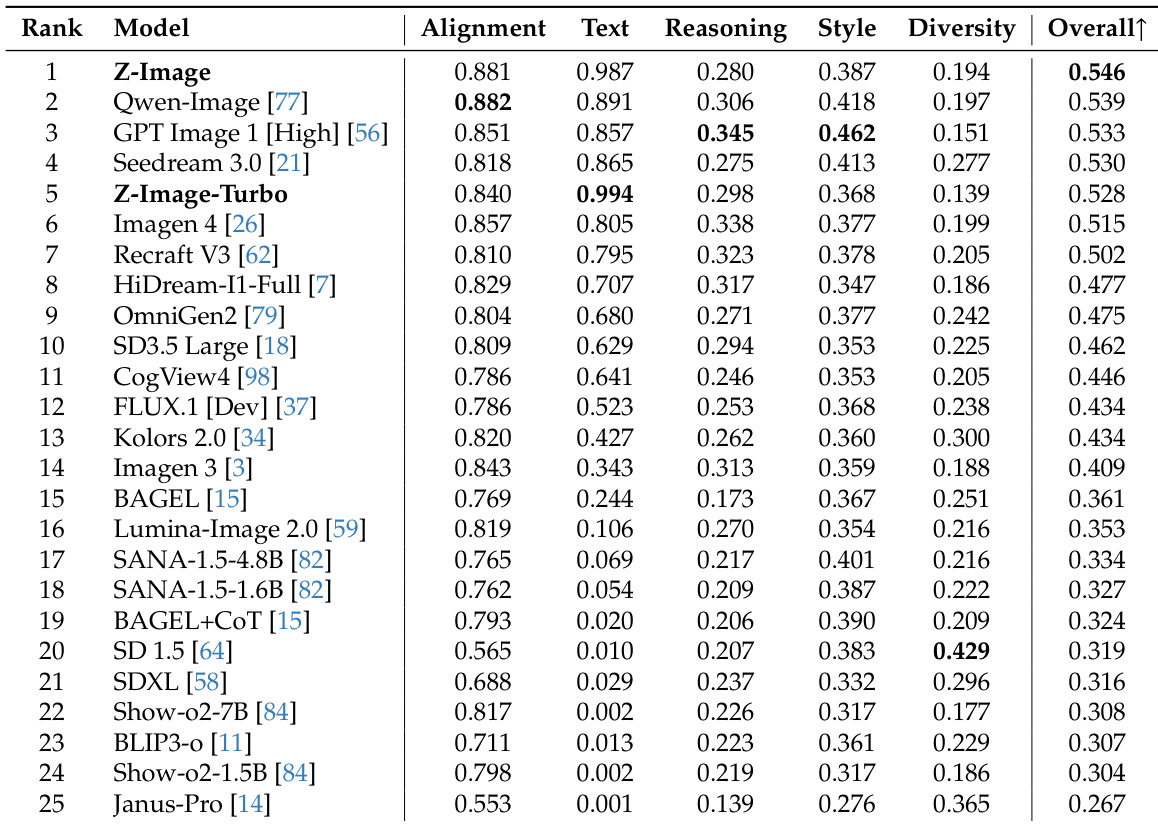
Results show that Z-Image achieves the highest overall score of 0.546 on the PRISM-Bench evaluation, outperforming all other models across multiple dimensions including alignment, text rendering, and style. Z-Image-Turbo, the distilled variant, ranks fifth with an overall score of 0.528, demonstrating strong performance while maintaining high inference efficiency.
Results show that Z-Image achieves the highest overall score of 80.20 on the TIIF benchmark, ranking fourth among all evaluated models, while Z-Image-Turbo secures fifth place with a score of 79.88, demonstrating strong instruction-following capabilities in both base and distilled versions.