Command Palette
Search for a command to run...
Vector Prism: Animating Vector Graphics by Stratifying Semantic Structure
Vector Prism: Animating Vector Graphics by Stratifying Semantic Structure
Jooyeol Yun Jaegul Choo
Abstract
Scalable Vector Graphics (SVG) are central to modern web design, and the demand to animate them continues to grow as web environments become increasingly dynamic. Yet automating the animation of vector graphics remains challenging for vision-language models (VLMs) despite recent progress in code generation and motion planning. VLMs routinely mis-handle SVGs, since visually coherent parts are often fragmented into low-level shapes that offer little guidance of which elements should move together. In this paper, we introduce a framework that recovers the semantic structure required for reliable SVG animation and reveals the missing layer that current VLM systems overlook. This is achieved through a statistical aggregation of multiple weak part predictions, allowing the system to stably infer semantics from noisy predictions. By reorganizing SVGs into semantic groups, our approach enables VLMs to produce animations with far greater coherence. Our experiments demonstrate substantial gains over existing approaches, suggesting that semantic recovery is the key step that unlocks robust SVG animation and supports more interpretable interactions between VLMs and vector graphics.
One-sentence Summary
Jooyeol Yun and Jaegul Choo (KAIST AI) introduce Vector Prism, a framework that recovers semantic structure in Scalable Vector Graphics through statistical aggregation of weak part predictions, enabling vision-language models to generate coherent animations by grouping fragmented shapes—addressing prior systems' failure to interpret SVG elements as unified semantic units and significantly improving web animation reliability.
Key Contributions
- SVG animation automation fails with vision-language models because coherent visual elements are fragmented into low-level shapes, offering no guidance on which parts should move together during motion planning.
- The framework recovers missing semantic structure through statistical aggregation of multiple weak part predictions, enabling reliable reorganization of SVGs into meaningful groups that guide coherent animation generation.
- Experiments show substantial gains over existing approaches by demonstrating that this semantic recovery step unlocks robust animation capabilities without requiring model fine-tuning.
Introduction
SVG animation is critical for dynamic web experiences, yet vision-language models (VLMs) struggle to automate it because real-world SVGs fragment coherent visual elements into low-level shapes, obscuring which parts should animate together. Prior approaches either optimize vector parameters via diffusion models—which resist meaningful motion due to appearance-focused rasterization—or fine-tune LLMs directly, requiring massive datasets to compensate for poor geometric understanding and failing on complex, unstructured SVGs. The authors introduce a framework that statistically aggregates noisy part predictions to recover semantic structure in SVGs, enabling VLMs to reliably group elements and generate coherent animations without model fine-tuning. This semantic recovery step bridges the gap between raw vector data and motion planning, significantly improving animation quality and interpretability.
Dataset
The authors use a test dataset of 114 hand-crafted animation instruction-SVG pairs, designed exclusively for evaluation. Key details:
-
Composition and sources:
Built from 57 unique SVG files sourced from SVGRepo, each paired with two distinct animation scenarios. SVG subjects span animals, logos, buildings, and natural elements (fire, clouds, water). -
Subset details:
- Thematic coverage: 31.6% Nature/Environment, 26.3% Objects/Miscellaneous, plus tech logos and UI elements.
- Interaction patterns: 28.1% Appearance/Reveal animations, 13.2% State Transitions, 12.3% Organic/Natural Movement, and 8.8% Rotational Movement.
All examples simulate real-world web animation needs, from loading indicators to interactive storytelling.
-
Usage and processing:
The dataset is strictly for testing—not training—with no mixture ratios applied. Instructions underwent manual curation to ensure diversity in techniques (simple movements to 3D rotations) and relevance to contemporary web use cases. No additional preprocessing, cropping, or metadata construction is described.
Method
The authors leverage a three-stage pipeline to bridge the semantic-syntactic gap inherent in animating SVGs using vision-language models (VLMs). The process begins with animation planning, proceeds through a novel restructuring module called Vector Prism, and concludes with animation generation. The core innovation lies in Vector Prism, which transforms noisy, weak semantic predictions from a VLM into reliable, structured SVG code that enables precise, instruction-following animations.
As shown in the figure below, the overall pipeline takes an SVG file and a natural language instruction as input and outputs an animated SVG file. The first stage, semantic understanding, employs a VLM to interpret the visual content of the rendered SVG and generate a high-level animation plan. This plan identifies which semantic components should move and how they relate to one another—for instance, interpreting “make the sun rise” as upward motion of a circular yellow region and gradual brightening of the background. Since VLMs lack knowledge of SVG syntax, they cannot directly implement these plans. This is where Vector Prism intervenes, converting the unstructured SVG into a semantically coherent representation that preserves visual appearance while enabling syntactic manipulation.
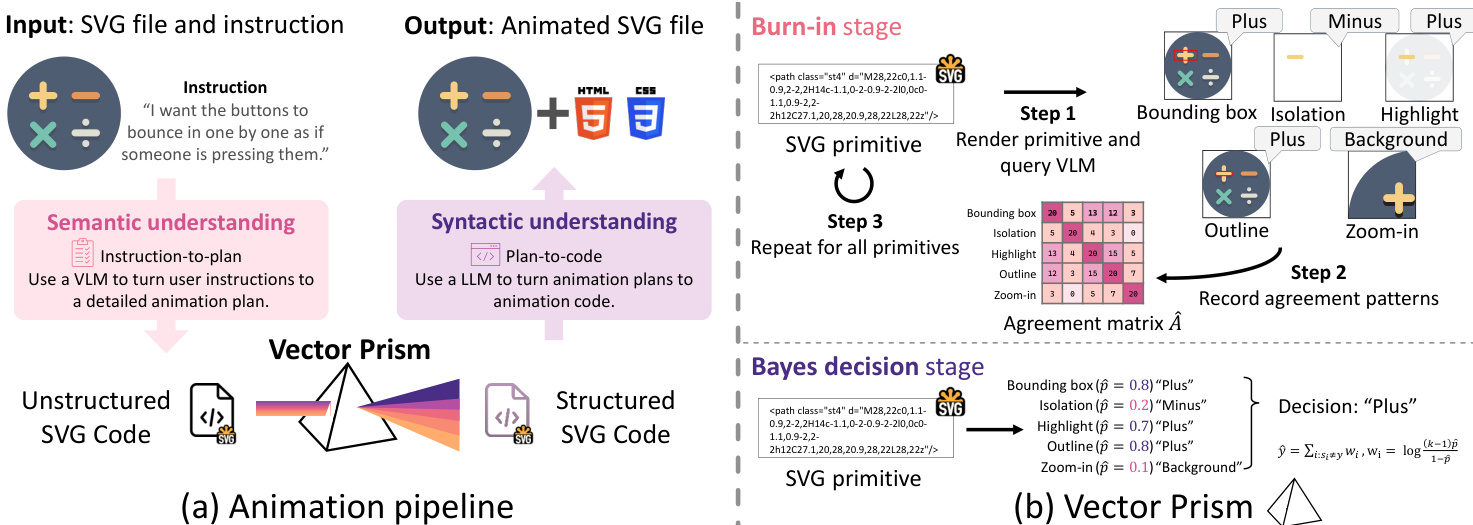
Vector Prism operates by statistically inferring semantic labels for each SVG primitive—basic shapes such as , , or —using multiple rendering views to elicit weak labels from the VLM. Each primitive is rendered using M different methods (e.g., bounding box overlay, isolation on white background, zoom-in, highlight, or outline), and the VLM assigns a label to each view. These views provide complementary signals, allowing the system to collect multiple noisy predictions per primitive. The authors model each rendering method as a Dawid-Skene classifier with unknown accuracy pi, where the probability of a correct label is pi and incorrect labels are chosen uniformly from the remaining k−1 categories.
To estimate the reliability pi of each rendering method, the system performs a burn-in pass over all primitives to construct an empirical agreement matrix A^ij, which records the fraction of primitives for which methods i and j agree. Under the Dawid-Skene model, the expected agreement between two methods is Aij=pipj+k−1(1−pi)(1−pj). By centering this matrix—subtracting the chance agreement term 1/k—the authors derive a rank-one matrix E[B]=k−1kδδ⊤, where δi=pi−k1. The top eigenvector of the empirical centered matrix B^ is then used to recover δ^, and thus p^i, enabling the system to quantify the reliability of each rendering method.
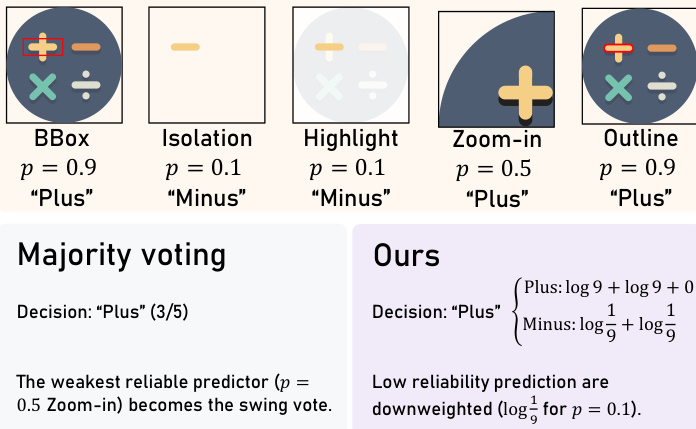
With estimated reliabilities in hand, Vector Prism assigns a final semantic label to each primitive using a Bayes decision rule with uniform prior. The log-likelihood of a candidate label y is computed as logP(y∣s)=const+∑i:si=ylogp^i+∑i:si=ylogk−11−p^i. This is equivalent to a weighted vote, where the weight for method i is wi=log1−p^i(k−1)p^i. As illustrated in the figure below, this approach downweights unreliable predictions—for example, a method with p=0.1 contributes a negative weight log91—whereas majority voting would treat all votes equally, potentially allowing a low-reliability method to swing the outcome.
Once semantic labels are assigned, the SVG is restructured to reflect these semantics without altering its visual appearance. The authors flatten the original hierarchy, bake inherited properties into primitives, and regroup primitives by label while preserving the original paint order. A barrier test ensures that merging primitives with the same label does not introduce rendering conflicts with intervening elements of different labels. The resulting SVG is visually identical to the input but semantically organized, with each group annotated with metadata such as bounding box and geometric center, which are later used to drive animation.
Finally, in the animation generation stage, an LLM is instructed to generate CSS animation code for each semantic group based on the plan produced in the first stage. To handle long outputs, the system generates animations iteratively per group, retaining previously generated CSS in context to ensure consistency and avoid conflicts. The LLM uses a “lanes” convention, expressing each motion component (translation, rotation, etc.) via typed CSS custom properties, which are then composed into final keyframes. This modular approach ensures that animations for different semantic groups can be generated independently and composed reliably.

Experiment
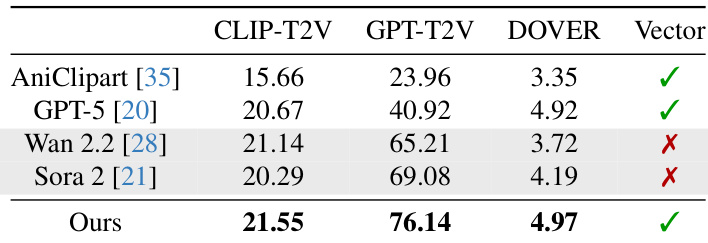
- Vector Prism validated on SVG animation tasks, achieving best scores across CLIP-T2V, GPT-T2V, and DOVER metrics, surpassing AniClipart, GPT-5, Wan 2.2, and Sora 2 in instruction following and perceptual quality
- User study with 760 pairwise comparisons showed 83.4% human preference alignment with GPT-T2V scores, confirming consistent favorability toward Vector Prism over all baselines including Sora 2
- Achieved ×54 smaller file sizes than Sora 2 while maintaining animation fidelity, demonstrating superior encoding efficiency for web-based vector graphics
- Semantic clustering via Vector Prism attained Davies-Bouldin Index of 0.82, significantly outperforming raw SVG groupings (33.8) and majority voting (12.6)
- GPT-T2V evaluation showed 83.4% agreement with human preferences, substantially exceeding CLIP-T2V's 53.4% alignment in instruction-following assessment
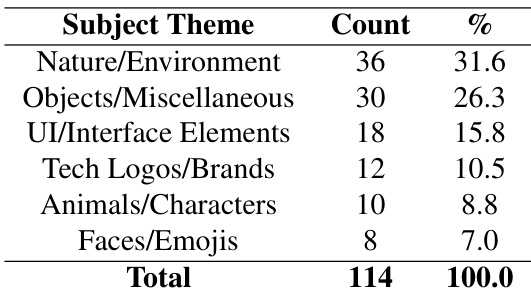
The authors analyze 114 animation instructions categorized by subject theme, with Nature/Environment accounting for the largest share at 31.6%, followed by Objects/Miscellaneous at 26.3%. UI/Interface Elements, Tech Logos/Brands, Animals/Characters, and Faces/Emojis make up the remaining 36.3%, reflecting a diverse but skewed distribution toward natural and general object themes.
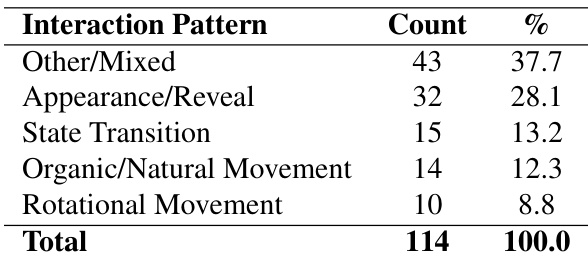
The authors analyze interaction patterns in generated animations, finding that “Other/Mixed” behaviors occur most frequently at 37.7%, followed by “Appearance/Reveal” at 28.1%. Results show that state transitions, organic movement, and rotational motion are less common, accounting for 13.2%, 12.3%, and 8.8% respectively, indicating a preference for composite or non-specific motion types in the evaluated dataset.
The authors evaluate their method against baselines using CLIP-T2V, GPT-T2V, and DOVER metrics, showing that their approach achieves the highest scores across all three, indicating superior instruction following and perceptual quality. While video generation models like Wan 2.2 and Sora 2 score higher on GPT-T2V, they fail to produce vector output and are marked with a red X, whereas the proposed method succeeds in generating valid vector animations. Results confirm that their method outperforms both optimization-based and LLM-based baselines while maintaining compatibility with vector formats.