Command Palette
Search for a command to run...
Multi-LLM Thematic Analysis with Dual Reliability Metrics: Combining Cohen's Kappa and Semantic Similarity for Qualitative Research Validation
Multi-LLM Thematic Analysis with Dual Reliability Metrics: Combining Cohen's Kappa and Semantic Similarity for Qualitative Research Validation
Nilesh Jain Seyi Adeyinka Leor Roseman Aza Allsop
Abstract
Qualitative research faces a critical reliability challenge: traditional inter-rater agreement methods require multiple human coders, are time-intensive, and often yield moderate consistency. We present a multi-perspective validation framework for LLM-based thematic analysis that combines ensemble validation with dual reliability metrics: Cohen's Kappa (κ) for inter-rater agreement and cosine similarity for semantic consistency. Our framework enables configurable analysis parameters (1-6 seeds, temperature 0.0-2.0), supports custom prompt structures with variable substitution, and provides consensus theme extraction across any JSON format. As proof-of-concept, we evaluate three leading LLMs (Gemini 2.5 Pro, GPT-4o, Claude 3.5 Sonnet) on a psychedelic art therapy interview transcript, conducting six independent runs per model. Results demonstrate Gemini achieves highest reliability (κ= 0.907, cosine=95.3%), followed by GPT-4o (κ= 0.853, cosine=92.6%) and Claude (κ= 0.842, cosine=92.1%). All three models achieve a high agreement (κ> 0.80), validating the multi-run ensemble approach. The framework successfully extracts consensus themes across runs, with Gemini identifying 6 consensus themes (50-83% consistency), GPT-4o identifying 5 themes, and Claude 4 themes. Our open-source implementation provides researchers with transparent reliability metrics, flexible configuration, and structure-agnostic consensus extraction, establishing methodological foundations for reliable AI-assisted qualitative research.
One-sentence Summary
Yale School of Medicine, University of Exeter, and Center for Collective Healing researchers introduce a multi-perspective LLM validation framework for thematic analysis that replaces traditional human coding with configurable ensemble runs and dual reliability metrics (Cohen's Kappa/cosine similarity). Validated on psychedelic art therapy transcripts, it achieves high inter-rater agreement (κ>0.80) across Gemini 2.5 Pro (κ=0.907), GPT-4o, and Claude 3.5 Sonnet, enabling transparent consensus theme extraction through structure-agnostic parameter customization.
Key Contributions
- Traditional qualitative research suffers from unreliable inter-rater agreement due to time-intensive human coding and moderate consistency, but this work introduces a multi-perspective LLM validation framework using ensemble runs with dual reliability metrics: Cohen's Kappa for categorical agreement and cosine similarity for semantic consistency.
- The framework enables configurable analysis through adjustable seeds (1-6) and temperature (0.0-2.0), supports custom prompts with variable substitution, and extracts consensus themes across any JSON structure via an adaptive algorithm requiring ≥50% run consistency.
- Evaluated on psychedelic art therapy transcripts with six runs per model, all three LLMs (Gemini 2.5 Pro, GPT-4o, Claude 3.5 Sonnet) achieved high reliability (κ > 0.80), with Gemini showing strongest results (κ = 0.907, cosine = 95.3%) and extracting six consensus themes at 50-83% consistency, validated through open-source implementation.
Introduction
Qualitative research increasingly adopts LLMs for thematic analysis to scale labor-intensive coding, but validation remains challenging as traditional metrics like Cohen's Kappa require exact categorical matches and ignore semantic equivalence, often yielding only moderate human coder agreement. Prior LLM approaches either focus narrowly on topic extraction, lack systematic reliability indicators, or show inconsistent performance across models without robust validation frameworks—highlighting gaps in capturing latent themes and quantifying analytical trustworthiness. The authors address this by introducing a dual-metric validation framework that combines Cohen's Kappa with semantic similarity scores across multiple LLM runs to quantify thematic consensus and reliability.
Method
The authors leverage a client-side, ensemble-based validation framework designed to ensure statistical robustness and semantic consistency in thematic analysis conducted via large language models. The system operates entirely in the browser using Next.js 14 and React, ensuring that raw transcripts remain on the researcher’s device until analysis initiation, thereby preserving data privacy. All preprocessing, embedding computation, and consensus extraction are performed locally using Transformers.js, with no external API calls required for semantic similarity calculations.
At the core of the framework is an ensemble validation mechanism that executes six independent analytical runs using fixed random seeds (42, 123, 456, 789, 1011, 1213). This design is statistically grounded: six runs yield 15 pairwise comparisons, computed as:
Comparisons=2n(n−1)=26×5=15This provides sufficient data points to detect meaningful agreement patterns while avoiding excessive computational cost. The standard error improvement from three to six runs is approximately 41%, calculated as:
SEkSE3=36=2≈1.41Each run produces theme outputs in JSON format, which are parsed robustly through a multi-stage pipeline that strips markdown fences, validates structure, and retries failed API calls with exponential backoff. For custom prompts, the system accepts any valid JSON object; for default prompts, it enforces required fields such as majorEmotionalThemes and emotionalPatterns.
To extract consensus themes across runs, the authors implement a structure-agnostic algorithm that dynamically detects common array fields (e.g., core_themes, client_experiences) and identifies theme name and supporting quote fields within them. Themes are then grouped using cosine similarity computed over 384-dimensional embeddings generated by the all-MiniLM-L6-v2 model. The similarity between two themes ti and tj is defined as:
where vi,vj∈R384 are the embedding vectors. Themes with similarity above 0.70 are clustered into equivalence classes. Consensus is determined by retaining themes appearing in at least 50% of runs, with per-theme consistency percentages (e.g., 5/6 = 83%) computed to distinguish high-confidence (5–6/6 runs) from moderate-confidence (3–4/6 runs) themes.
The framework supports nine LLM providers—including Google Gemini, Anthropic Claude, OpenAI GPT, and OpenRouter-accessed models—via a unified API interface. Each provider implements standardized request formatting, response normalization, error handling, and CORS configuration. API keys are provided at runtime and never stored or transmitted beyond the respective provider endpoints.
To enable methodological flexibility, the system exposes configurable parameters: researchers may adjust the number of seeds (1–6), temperature (T∈[0.0,2.0]), and custom prompts with variable substitution (e.g., {seed}, {text_chunk}). Temperature controls output randomness, with lower values favoring deterministic outputs and higher values encouraging exploratory interpretation.
Performance is optimized for browser execution: embedding computation is limited to 10 themes per run, lightweight string comparison is used for large theme sets, and pairwise comparisons are sampled if exceeding 10 pairs. The UI remains responsive via setTimeout(0) yielding and progressive status updates during intensive operations.
Refer to the framework diagram for a visual overview of the end-to-end workflow, from client-side preprocessing through ensemble runs, semantic clustering, and consensus extraction.
Experiment
- Evaluated three LLMs (Gemini 2.5 Pro, GPT-4o, Claude 3.5 Sonnet) on a ketamine art therapy interview transcript using six independent runs per model, validating the ensemble framework's reliability through dual metrics.
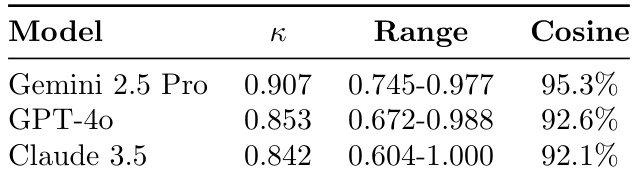
- All models achieved "almost perfect" inter-rater agreement (Cohen's Kappa > 0.80): Gemini κ=0.907 (cosine=95.3%), GPT-4o κ=0.853 (cosine=92.6%), Claude κ=0.842 (cosine=92.1%), confirming the ensemble approach's robustness.
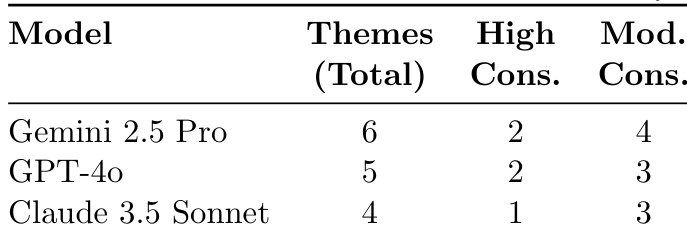
- Extracted consensus themes across runs: Gemini identified 6 themes (50-83% consistency), GPT-4o 5 themes, and Claude 4 themes, with high-confidence themes (e.g., "Overcoming Creative Blocks" at 83% consistency) validated through cross-model semantic similarity (e.g., 0.88 for "IFS Integration").
- Demonstrated framework superiority over existing methods by achieving higher inter-run consistency (92-95% cosine similarity) than prior human-AI comparisons (0.76 similarity) while enabling structure-agnostic consensus extraction.
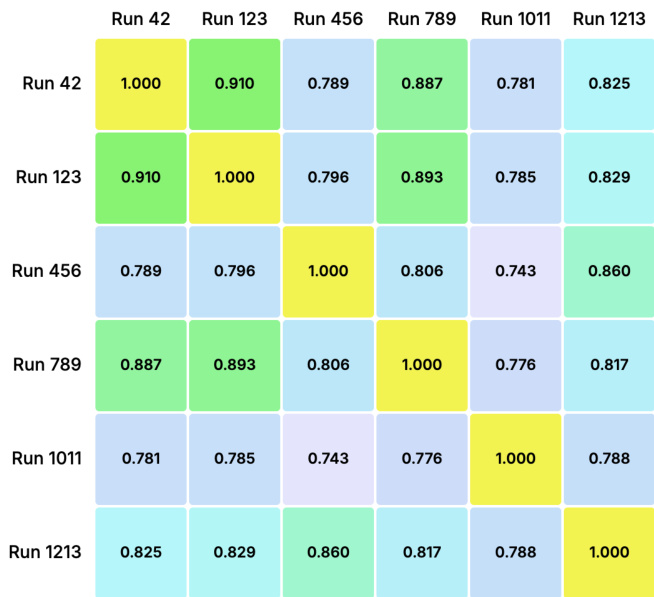
The authors use a multi-run ensemble approach with fixed seeds to evaluate thematic consistency across six independent runs of Gemini 2.5 Pro, computing pairwise cosine similarity to measure semantic agreement. Results show strong inter-run consistency, with similarity scores ranging from 0.743 to 0.910 and most values above 0.78, indicating robust thematic stability. The diagonal values of 1.000 reflect perfect self-similarity, while the high off-diagonal scores validate the model’s reliability in producing consistent thematic outputs across varied runs.
The authors use a multi-run ensemble approach to evaluate thematic consistency across three LLMs on a ketamine art therapy transcript, identifying total themes and categorizing them by consensus level. Gemini 2.5 Pro extracts the most themes overall (6), with 2 high-consensus and 4 moderate-consensus themes, while GPT-4o identifies 5 themes (2 high, 3 moderate) and Claude 3.5 Sonnet identifies 4 themes (1 high, 3 moderate). Results show Gemini achieves the highest thematic stability, followed by GPT-4o and then Claude, aligning with their respective reliability scores.
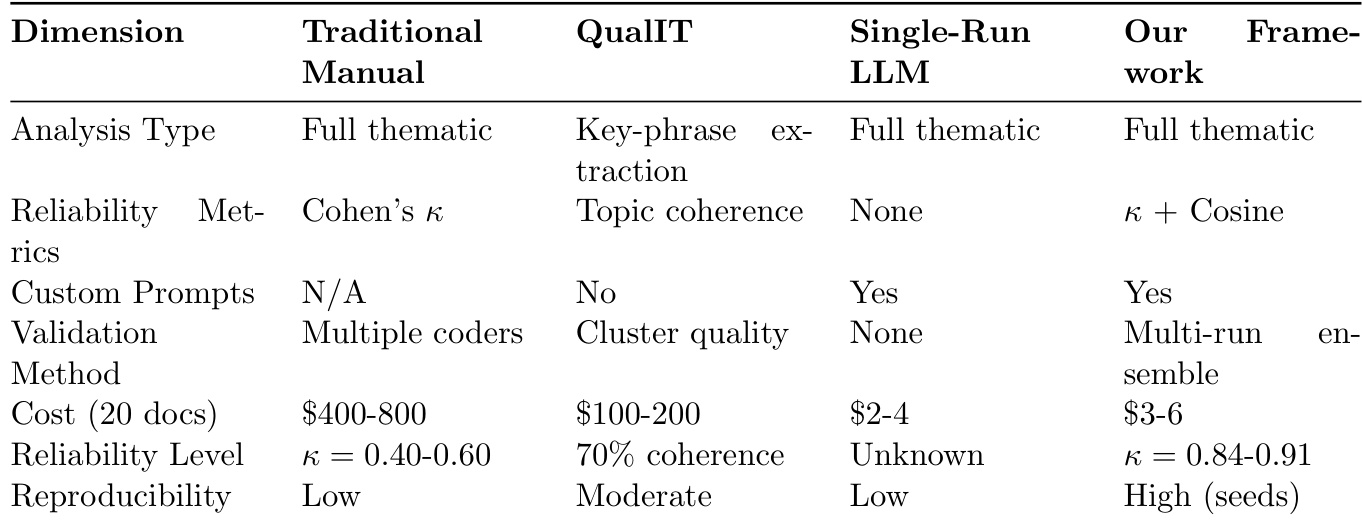
The authors compare their multi-run ensemble framework against traditional manual, QualIT, and single-run LLM approaches, showing it delivers full thematic analysis with dual reliability metrics (Cohen’s Kappa and cosine similarity), custom prompt support, and high reproducibility via seed-based runs. Their method achieves higher reliability (κ = 0.84–0.91) at substantially lower cost (3–6for20documents)thanmanualcoding(400–800), while offering structured validation absent in single-run LLM methods. Results confirm the framework’s ability to balance computational efficiency with rigorous qualitative standards through ensemble consistency.
The authors evaluate three LLMs using dual reliability metrics across six runs each, finding Gemini 2.5 Pro achieves the highest Cohen’s Kappa (0.907) and cosine similarity (95.3%), with the narrowest kappa range indicating stable performance. GPT-4o and Claude 3.5 also show strong agreement (κ > 0.84), though Claude exhibits the widest kappa range, suggesting greater variability between runs. Results validate the ensemble approach for achieving high inter-run consistency in thematic analysis.