Command Palette
Search for a command to run...
Step-DeepResearch Technical Report
Step-DeepResearch Technical Report
Abstract
As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
One-sentence Summary
StepFun researchers propose Step-DeepResearch, a cost-effective 32B-parameter agent model for open-ended deep research tasks, introducing a novel Atomic Capabilities-based data synthesis strategy and progressive training with a checklist-style reward system. It achieves expert-level performance on RESEARCHRUBRICS (61.42) and a new Chinese-language benchmark, rivaling proprietary services like OpenAI DeepResearch while significantly reducing deployment costs.
Key Contributions
- Existing Deep Research evaluations like BrowseComp focus on academic multi-hop search with ground truth, failing to address real-world open-ended research demands requiring latent intent recognition, long-horizon decision-making, and cross-source verification. This gap limits agent usability despite industrial progress in systems like OpenAI DeepResearch.
- The authors introduce Step-DeepResearch, a 32B-parameter agent trained via a novel Data Synthesis Strategy Based on Atomic Capabilities (targeting planning, information seeking, reflection, and report writing) and a progressive pipeline from agentic mid-training to supervised fine-tuning and reinforcement learning with a Checklist-style Judger reward.
- Evaluated on the new Chinese ADR-Bench benchmark covering commercial, policy, and software engineering scenarios, Step-DeepResearch achieves a 61.42 score on RESEARCHRUBRICS and surpasses open-source models while rivaling OpenAI DeepResearch and Gemini DeepResearch in expert Elo ratings, demonstrating cost-effective expert-level performance.
Introduction
The authors recognize that real-world Deep Research—addressing open-ended, complex information-seeking tasks—demands capabilities beyond academic multi-hop question answering, including latent intent recognition, long-horizon planning, cross-source verification, and structured synthesis. Prior agent systems either over-optimized for retrieval accuracy in constrained benchmarks like BrowseComp, producing fragmented "web crawlers" rather than coherent researchers, or relied on complex multi-agent orchestration that increased deployment costs and reduced robustness in practical scenarios. To bridge this gap, the authors introduce Step-DeepResearch, a 32B-parameter model trained via a novel atomic capability data synthesis strategy that decomposes research into trainable skills (planning, reflection, verification) and a progressive training pipeline from mid-training to reinforcement learning. This end-to-end approach internalizes expert-like cognitive loops within a single agent, enabling cost-effective, high-quality research performance that rivals larger proprietary systems while addressing real-world usability gaps.
Dataset
The authors construct a synthetic training dataset through three primary methods to address gaps in existing research benchmarks:
-
Dataset composition and sources
The core training data is synthetically generated from high-quality sources including open-access technical reports, academic surveys, financial research documents, Wikidata5m, and CN-DBpedia knowledge graphs. This approach ensures coverage of real-world research complexity where public benchmarks lack depth. -
Key subset details
- Planning & Task Decomposition data: Reverse-engineered from report titles/abstracts using LLMs to create complex queries and feasible plans. Filtered via trajectory consistency checks to retain only paths aligning with preset plans.
- Reasoning data: Built via graph-based synthesis (10-40 node subgraphs from Wikidata5m/CN-DBpedia) and multi-document walks (using Wiki-doc hyperlinks). Queries undergo difficulty filtering using QwQ-32b to exclude solvable "simple problems."
- Reflection & Verification data: Generated through closed-loop pipelines for self-correction and fact-checking, incorporating structured noise (e.g., tool errors with recovery steps).
- Report data: Mid-training uses 〈Query, Report〉 pairs from screened human reports (e.g., financial analyses), with queries reverse-engineered from document content.
-
Usage in model training
- Mid-training: Focuses on atomic capabilities (planning, retrieval) using domain-style 〈Query, Report〉 pairs and reasoning subsets.
- SFT stage: Combines two trajectory types at optimized ratios:
- Deep Search: Ground-truth answer tasks prioritizing "correct and shortest" trajectories for efficiency.
- Deep Research: Open-ended tasks covering full pipelines (planning to citation-rich reporting), constituting the majority for end-to-end logic reinforcement.
Mixture ratios emphasize Deep Research data to align with real-scenario demands.
-
Processing and quality controls
- Trajectory efficiency filtering retains only minimal-step successful paths.
- Strict N-gram deduplication removes repetitive reasoning loops.
- Citation formatting (\cite{}) is enforced in reports for factual grounding.
- Controlled noise injection (e.g., 5-10% tool errors) builds robustness to real-world instability.
Evaluation uses ADR-Bench with 90 real-user queries across nine domains (20 professional-law/finance, 70 general), rigorously validated by domain experts.
Method
The authors leverage a ReAct-inspired single-agent architecture to structure the Step-DeepResearch system, enabling dynamic, iterative reasoning through alternating phases of thought generation and tool interaction. As shown in the figure below, the agent receives a user query and initiates a multi-turn loop in which it alternates between internal reasoning (enclosed in <tool_call> tags) and external tool invocation (via <toolcall>), with each tool response fed back into the next reasoning step. This cycle continues until the agent produces a final report, marked by an <answer> tag, which is then delivered as a structured document.
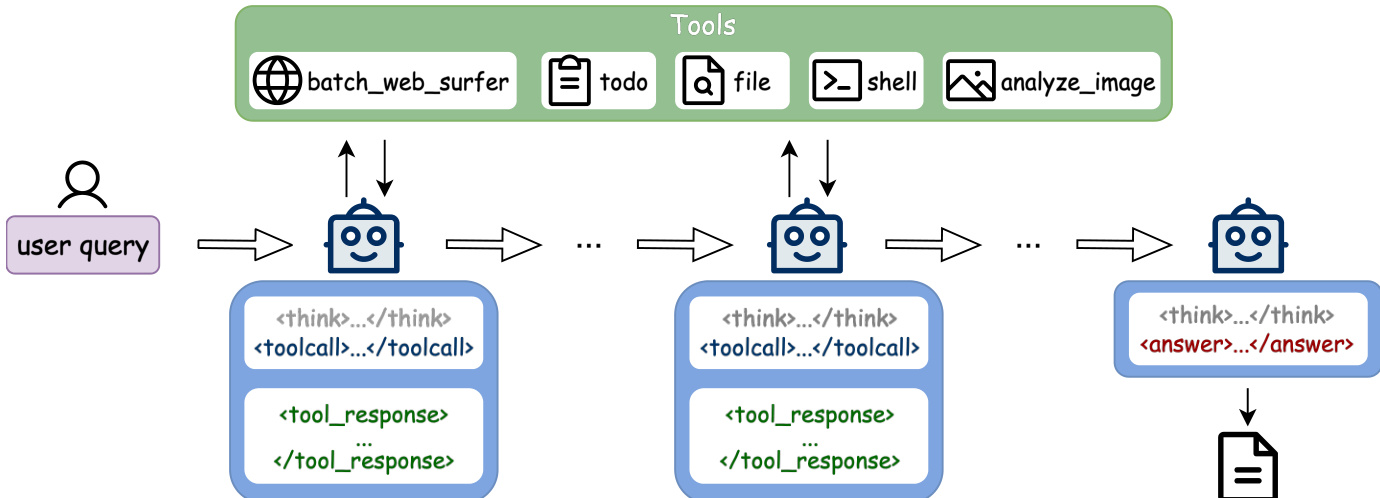
The agent’s core operational loop is supported by a unified tool system designed for capability alignment, information adaptation, and architectural simplification. Key tools include batch_web_surfer for high-precision information retrieval, todo for stateful task tracking, file for token-efficient document editing and local storage, shell for sandboxed terminal execution, and analyze_image for multimodal perception. These tools are not merely wrappers but are engineered to preserve human-like interaction logic while optimizing for token efficiency and long-context robustness.
For information acquisition, the system employs a curated authority indexing strategy, isolating over 600 authoritative domains to ensure factual grounding. Knowledge-dense retrieval operates at paragraph-level granularity to maximize information density per token, while authority-aware ranking heuristics prioritize high-trust sources when semantic relevance is comparable. During execution, the agent leverages a patch-based editing protocol to minimize token overhead during report refinement and a summary-aware local storage mechanism to offload context pressure to disk, enabling near-infinite context support.
To support long-horizon reasoning, the system integrates stateful todo management that decouples research progress from model weights, ensuring goal alignment across extended trajectories. Interactive execution is enhanced through tmux-integrated sandboxing, allowing stable operation of stateful command-line tools, and a perception-optimized browser that suppresses redundant visual feedback via perceptual hash comparison, reducing multimodal token redundancy.
The agent’s behavior is governed by a policy πθ that maps states—comprising user intent, historical tokens, and tool observations—to actions, which may include natural language generation or structured tool calls. Training proceeds through a three-stage pipeline: mid-training to instill atomic capabilities, supervised fine-tuning to enforce instruction following and formatting, and reinforcement learning to optimize for real-world task performance. In the RL stage, the agent interacts within a multi-tool environment under explicit budget constraints, and its performance is evaluated via a rubric-based reward system. The reward signal is derived from a trained Rubrics Judge model that maps fine-grained rubric judgments to binary signals—either 1 or 0—based on whether each rubric is fully satisfied, eliminating ambiguity from intermediate categories. Policy updates are performed using the clipped PPO objective, with advantage estimation via GAE (γ=1,λ=1) to simplify credit assignment in long-horizon, sparse-reward settings.
Experiment
- Stage 1 mid-training (32K context) validated gains in structured reasoning, achieving +10.88% on FRAMES benchmark after 150B tokens, with steady improvements on SimpleQA (+1.26%) and TriviaQA (+2.30%).
- Stage 2 mid-training (128K context) validated enhanced tool-augmented reasoning for real-world tasks, enabling retrieval and multi-tool collaboration under ultra-long contexts.
- Step-DeepResearch achieved 61.42 on RESEARCHRUBRICS benchmark, surpassing open-source models by +5.25 (e.g., Kimi-k2-thinking) and nearing Gemini DeepResearch (63.69), while costing under 0.50 RMB per report—less than one-tenth of Gemini (6.65 RMB).
- On ADR-Bench human evaluation, Step-DeepResearch won 30 out of 70 comparisons against its non-midtrained version and achieved 67.1% non-inferiority rate against top commercial systems, leading in AI/ML (64.8), Historical Analysis (65.8), and Technical Documentation (64.6) domains.