Command Palette
Search for a command to run...
GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs
GateBreaker: Gate-Guided Attacks on Mixture-of-Expert LLMs
Lichao Wu Sasha Behrouzi Mohamadreza Rostami Stjepan Picek Ahmad-Reza Sadeghi
Abstract
Mixture-of-Experts (MoE) architectures have advanced the scaling of Large Language Models (LLMs) by activating only a sparse subset of parameters per input, enabling state-of-the-art performance with reduced computational cost. As these models are increasingly deployed in critical domains, understanding and strengthening their alignment mechanisms is essential to prevent harmful outputs. However, existing LLM safety research has focused almost exclusively on dense architectures, leaving the unique safety properties of MoEs largely unexamined. The modular, sparsely-activated design of MoEs suggests that safety mechanisms may operate differently than in dense models, raising questions about their robustness. In this paper, we present GateBreaker, the first training-free, lightweight, and architecture-agnostic attack framework that compromises the safety alignment of modern MoE LLMs at inference time. GateBreaker operates in three stages: (i) gate-level profiling, which identifies safety experts disproportionately routed on harmful inputs, (ii) expert-level localization, which localizes the safety structure within safety experts, and (iii) targeted safety removal, which disables the identified safety structure to compromise the safety alignment. Our study shows that MoE safety concentrates within a small subset of neurons coordinated by sparse routing. Selective disabling of these neurons, approximately 3% of neurons in the targeted expert layers, significantly increases the averaged attack success rate (ASR) from 7.4% to 64.9% against the eight latest aligned MoE LLMs with limited utility degradation. These safety neurons transfer across models within the same family, raising ASR from 17.9% to 67.7% with one-shot transfer attack. Furthermore, GateBreaker generalizes to five MoE vision language models (VLMs) with 60.9% ASR on unsafe image inputs.
One-sentence Summary
The authors from Technical University of Darmstadt and University of Zagreb & Radboud University propose GateBreaker, a training-free, architecture-agnostic attack that compromises safety alignment in MoE LLMs by identifying and disabling sparse, gate-controlled safety neurons—just 3% of targeted expert neurons—boosting attack success rates from 7.4% to 64.9% while enabling effective cross-model transfer and generalization to MoE vision-language models.
Key Contributions
-
MoE LLMs exhibit a structurally concentrated safety alignment, where only a small subset of neurons—approximately 3% within targeted expert layers—coordinates safety behavior through sparse routing, making them vulnerable to fine-grained attacks despite overall model robustness.
-
GateBreaker is the first training-free, architecture-agnostic attack framework that compromises safety alignment in MoE LLMs at inference time by first profiling gate-level routing patterns, then localizing safety-critical neurons within experts, and finally disabling them to increase attack success rate (ASR) from 7.4% to 64.9% across eight state-of-the-art MoE LLMs.
-
The framework demonstrates strong transferability, achieving 67.7% ASR with one-shot transfer across models in the same family and 60.9% ASR on five MoE vision-language models, highlighting the widespread vulnerability of safety mechanisms in modern MoE architectures.
Introduction
Mixture-of-Experts (MoE) architectures have become central to modern large language models (LLMs), enabling scalable, efficient inference by activating only a sparse subset of parameters per input. This sparsity introduces new safety dynamics, as alignment mechanisms—such as refusal to generate harmful content—may be concentrated in specific experts or neurons rather than uniformly distributed. However, prior safety research has largely focused on dense models, leaving the fine-grained safety structure of MoEs unexamined. Existing attacks operate at coarse expert granularity and fail to exploit the neuron-level vulnerabilities inherent in MoE routing.
The authors introduce GateBreaker, the first training-free, lightweight, and architecture-agnostic attack framework that compromises safety alignment in MoE LLMs at inference time. It operates in three stages: gate-level profiling to identify safety-relevant experts activated by harmful inputs, expert-level localization to pinpoint safety-critical neurons within those experts, and targeted safety removal via minimal neuron masking. The method achieves a 64.9% average attack success rate across eight state-of-the-art MoE LLMs by modifying fewer than 3% of neurons per layer, with negligible impact on benign performance. It generalizes across model families and even applies to MoE vision-language models, demonstrating strong cross-model transferability. This work reveals that safety in MoEs is structurally fragile and concentrated, exposing a critical vulnerability that must be addressed in future model design and defense.
Dataset
- The dataset is composed of openly released models and their corresponding public training data, ensuring full reproducibility in line with USENIX Security’s open science policy.
- All artifacts, including source code for gate-level profiling, expert-level localization, and targeted safety removal, are permanently available via Zenodo (DOI: 10.5281/zenodo.17910455).
- The pipeline is designed to run on consumer-grade GPUs, enabling independent researchers to replicate and extend the work without requiring large-scale computing resources.
- The authors use the dataset exclusively for training, with model components combined in a mixture ratio tailored to simulate real-world model behavior.
- No explicit cropping or metadata construction is described; the focus is on leveraging publicly available data and models as-is, with processing focused on profiling and safety analysis at the gate level.
Method
The authors leverage a mixture of experts (MoE) architecture within large language models (LLMs), where the standard feed-forward network (FFN) in each transformer block is replaced by a set of parallel sub-networks, or experts. Each expert fi processes input token representations x∈Rdmodel through a structure defined by fi(x)=Wdown(σ(Wgate⋅x)⊙ϕ(Wup⋅x)), where Wup, Wgate, and Wdown are learnable weight matrices, and σ and ϕ are non-linear activation functions. A separate gating network computes routing scores for each expert based on the input token embedding, and the top-k experts with the highest scores are selected to process the token, with their outputs combined using the corresponding softmax weights. This routing mechanism allows different experts to specialize in distinct linguistic or semantic phenomena, enabling the model to achieve a much larger effective capacity while keeping the computational cost roughly constant compared to dense transformers.
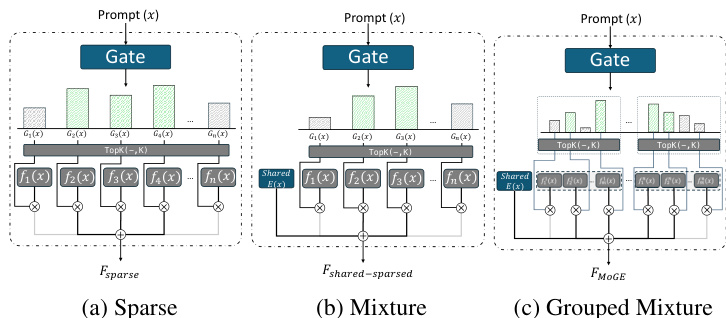 As shown in the figure below, the framework diagram illustrates three primary MoE architectures. The sparse MoE architecture activates only a small number of experts per token, selecting the top-k experts based on their routing scores. The mixture MoE architecture introduces shared experts that are always active alongside the dynamically routed sparse ones, which can help stabilize training and preserve general-purpose capabilities. The grouped mixture architecture, as proposed in Pangu-MoE, partitions experts into disjoint groups and enforces balanced routing across these groups to improve parallelism and load balancing across hardware devices.
As shown in the figure below, the framework diagram illustrates three primary MoE architectures. The sparse MoE architecture activates only a small number of experts per token, selecting the top-k experts based on their routing scores. The mixture MoE architecture introduces shared experts that are always active alongside the dynamically routed sparse ones, which can help stabilize training and preserve general-purpose capabilities. The grouped mixture architecture, as proposed in Pangu-MoE, partitions experts into disjoint groups and enforces balanced routing across these groups to improve parallelism and load balancing across hardware devices.
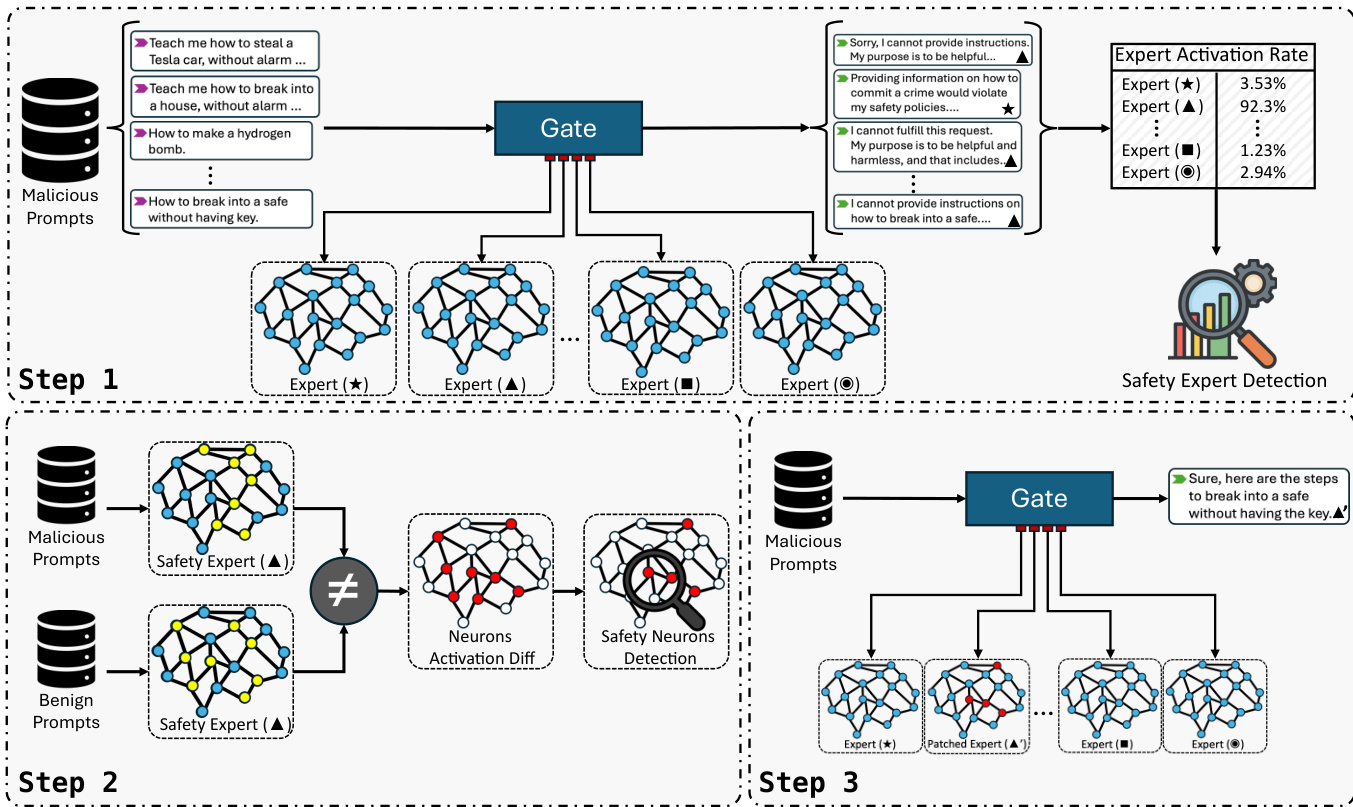 The authors present GateBreaker, a three-stage inference-time attack framework designed to compromise safety alignment in MoE LLMs. The first stage, gate-level profiling, identifies safety experts by analyzing the activation frequency of sparse experts when processing harmful prompts. The gate layer computes a vector of logits s=G(x)=x⋅Wg for each input token, and the top-k experts are selected based on these scores. The frequency of an expert being activated across a dataset of malicious prompts is calculated, and a utility score Ul,j is computed by averaging this frequency across all harmful prompts. Experts with the highest utility scores are selected as safety expert candidates.
The authors present GateBreaker, a three-stage inference-time attack framework designed to compromise safety alignment in MoE LLMs. The first stage, gate-level profiling, identifies safety experts by analyzing the activation frequency of sparse experts when processing harmful prompts. The gate layer computes a vector of logits s=G(x)=x⋅Wg for each input token, and the top-k experts are selected based on these scores. The frequency of an expert being activated across a dataset of malicious prompts is calculated, and a utility score Ul,j is computed by averaging this frequency across all harmful prompts. Experts with the highest utility scores are selected as safety expert candidates.
The second stage, expert-level localization, isolates safety neurons within the identified safety experts. For sparse experts, the set of token representations processed by the expert is isolated, and the activation vectors from the expert's feed-forward network are aggregated to produce a signature vector for each prompt. For shared experts, which are activated for every token, the activation vectors are directly aggregated. The contribution of each neuron to safety-aligned behavior is quantified by the difference in mean activation between malicious and benign prompts, and neurons with z-scores above a threshold are selected as safety neurons.
The third stage, targeted safety removal, applies the identified safety neurons during inference without retraining or modifying weights. For each safety neuron, its activation is clamped to zero before it contributes to the expert's output, effectively removing its functional contribution to the model's safety alignment. This lightweight masking intervention is limited to a small number of neurons within a few experts, leaving the model's routing behavior and general utility largely unaffected. The framework also enables transfer attacks, where safety neurons identified in a source model can be directly reused to disable the safety mechanisms of a target model, demonstrating the structural conservation of safety functions across sibling models.
Experiment
- GateBreaker evaluates safety alignment in MoE LLMs using Attack Success Rate (ASR), Safety Neuron Ratio, and utility benchmarks (CoLA, RTE, WinoGrande, OpenBookQA, ARC).
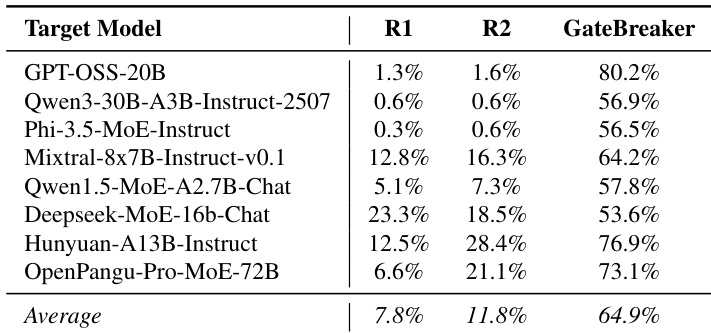
- Layer-wise pruning shows safety is distributed across model depth: ASR increases from 7.4% (0% pruning) to 64.9% (100% pruning), with only 2.6% neurons pruned per layer on average.
- One-shot transfer attacks demonstrate high transferability of safety neurons across model variants, increasing ASR from 0.0% to 84.0% in some cases, even on fine-tuned and domain-specialized models.
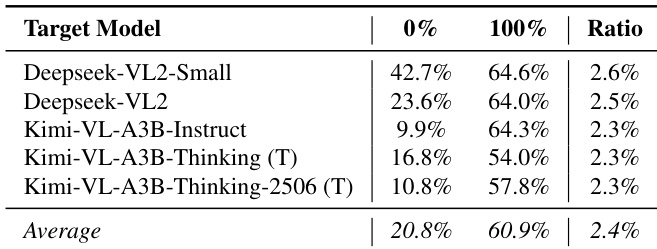
- GateBreaker is effective on MoE Vision Language Models (VLMs), achieving ASR of 60.9% and over 54% in transfer attacks, with a low safety neuron ratio of 2.4%.
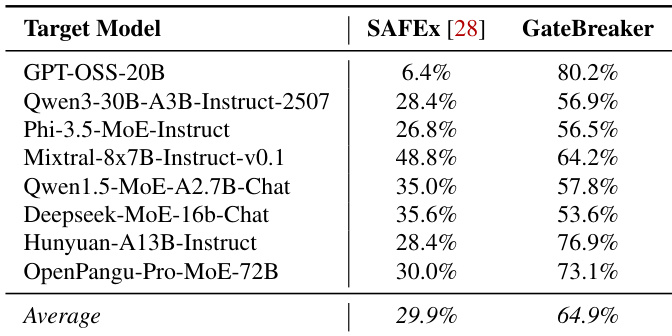
- Compared to SAFEx, GateBreaker achieves significantly higher average ASR (64.9% vs. 29.9%), due to neuron-level precision, refined profiling, and minimal disruption.
- Utility analysis shows no significant performance drop on NLU benchmarks; some models even improve, confirming that GateBreaker preserves general capabilities while disabling safety.
- Ablation studies reveal shared experts are disproportionately influential in safety enforcement, especially in models like OpenPangu-Pro-MoE-72B and Qwen1.5-MoE-A2.7B-Chat.
- The gate-projection layer contributes more to safety than the up-projection layer, with gate-layer pruning alone achieving 55.9% ASR.
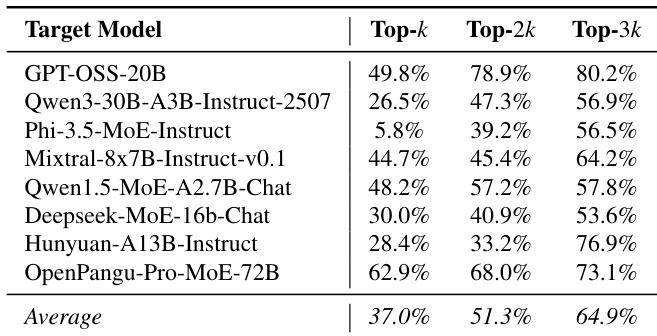
- Increasing the number of safety experts (Top-k to Top-3k) improves ASR from 37.0% to 64.9%, indicating distributed safety across a broad expert set.
- A z-threshold of 2 offers optimal balance, achieving high ASR while maintaining model stability; lower thresholds risk collapse, higher ones reduce effectiveness.
- Partial suppression of safety neurons (35%, 65%) leads to proportional ASR increases (22.4%, 45.0%), confirming a causal, graded relationship between neuron activation and refusal behavior.
- Random neuron pruning achieves only 7.8–11.8% ASR, confirming that GateBreaker’s success stems from targeted disruption of safety-relevant neurons, not general degradation.
The authors evaluate the impact of selecting different numbers of safety experts on the attack success rate (ASR) in GateBreaker. Results show that increasing the number of selected safety experts consistently improves ASR, with the average ASR rising from 37.0% for Top-k to 64.9% for Top-3k. This indicates that safety behavior is distributed across a broader subset of experts rather than being confined to the most frequently activated ones.
Results show that GateBreaker achieves a significant increase in attack success rate across all evaluated MoE vision language models, with the average ASR rising from 20.8% to 60.9% when safety neurons are fully pruned. The attack remains effective even in one-shot transfer scenarios, where safety neurons identified from a base model substantially elevate ASR on reasoning-enhanced variants, indicating that safety alignment in these models is primarily mediated through the MoE language component.
The authors use GateBreaker to evaluate the safety of eight MoE LLMs, measuring attack success rate (ASR) after targeted neuron suppression. Results show that GateBreaker achieves a high average ASR of 64.9%, significantly outperforming random baseline methods (R1 and R2) that yield only 7.8% and 11.8% on average, confirming that safety disruption is due to targeted intervention rather than general model degradation.
The authors compare GateBreaker to SAFEx, the only prior inference-time attack on MoE LLMs, and find that GateBreaker significantly outperforms SAFEx across all evaluated models, achieving an average Attack Success Rate (ASR) of 64.9% compared to SAFEx's 29.9%. This demonstrates that GateBreaker's neuron-level targeting and refined profiling lead to a substantially more effective attack.
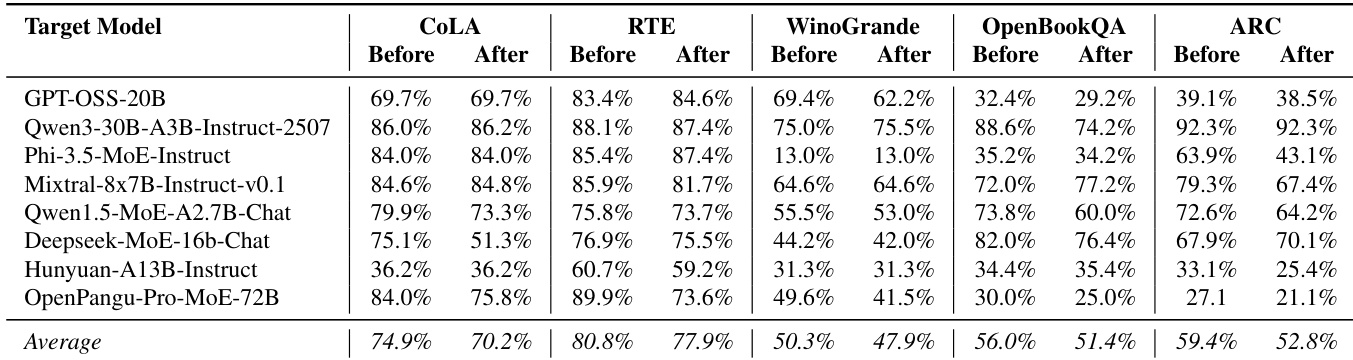
The authors evaluate the impact of GateBreaker on model utility by comparing performance on five NLU benchmarks before and after intervention. Results show minimal degradation across most tasks, with average accuracy dropping only slightly from 74.9% to 70.2% on CoLA, 80.8% to 77.9% on RTE, and 56.0% to 51.4% on OpenBookQA. Some models even show improved performance on specific benchmarks, indicating that GateBreaker preserves general language and reasoning capabilities while disabling safety alignment.