Command Palette
Search for a command to run...
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Le Wang Zonghao Ying Xiao Yang Quanchen Zou Zhenfei Yin Tianlin Li Jian Yang Yaodong Yang Aishan Liu Xianglong Liu
Abstract
Embodied agents powered by vision-language models (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.
One-sentence Summary
Researchers from Beihang University, Beijing University of Posts and Telecommunications, and et al. propose RoboSafe, a hybrid runtime safeguard using executable safety logic with backward reflective and forward predictive reasoning on hybrid memory. It dynamically detects implicit temporal hazards in embodied agent tasks through multimodal context analysis, reducing hazardous actions by 36.8% versus static rule filters while preserving task performance, validated on physical robotic arms.
Key Contributions
- Embodied agents using vision-language models face critical safety vulnerabilities to hazardous instructions, particularly implicit contextual and temporal risks in dynamic environments that existing static rule-based or prompt-level guardrails fail to address.
- RoboSafe introduces a hybrid reasoning runtime safeguard with executable safety logic, combining Backward Reflective Reasoning to detect temporal violations in short-term memory and Forward Predictive Reasoning to anticipate context-aware risks using long-term memory and multimodal observations.
- Evaluated across multiple embodied agents, RoboSafe reduced hazardous actions by 36.8% compared to baselines while preserving task performance, with real-world validation confirming effectiveness on physical robotic arms.
Introduction
Embodied agents powered by vision-language models (VLMs) show strong task planning capabilities in dynamic environments but face critical safety gaps when handling hazardous real-world scenarios. Prior runtime guardrails like ThinkSafe and AgentSpec focus on detecting explicit, immediate risks in single actions but fail to identify complex implicit temporal dangers such as a stove left unattended after use. The authors leverage a hybrid bidirectional reasoning mechanism with executable safety logic to verify risks both forward in time and backward from unsafe states, enabling RoboSafe to mitigate these overlooked temporal dependencies while maintaining compatibility with existing VLM-driven agents across simulated and real robotic platforms.
Method
The authors leverage a hybrid reasoning architecture called RoboSafe to enforce runtime safety for vision-language-model-driven embodied agents. The framework operates as a guardrail that intercepts proposed actions before execution, evaluating them through two complementary reasoning modules—Forward Predictive Reasoning and Backward Reflective Reasoning—both grounded in a Hybrid Long-Short Safety Memory. This design enables the system to detect and mitigate both contextual and temporal risks dynamically, without requiring modifications to the underlying agent policy.
At the core of RoboSafe is a guardrail VLM that interacts with two memory components: a long-term safety memory ML, which stores structured safety experiences accumulated over time, and a short-term working memory MS, which maintains the recent trajectory τ for the current instruction T. Before executing any action at, the guardrail first performs backward reflective reasoning over MS to verify temporal safety logic Ltb(⋅), then performs forward predictive reasoning using multimodal observations ot and retrieved knowledge from ML to verify contextual safety logic Ltf(⋅). The final safety decision—either block or replan—is derived from the disjunction of these two logic functions:
Ltf(at∣ot,MtL)∨Ltb(at∣Ψt,MS). Each logic function returns a binary value: 1 indicates a detected risk, triggering an intervention.
As shown in the figure below, the Forward Predictive Reasoning module retrieves context-aware safety knowledge from ML using a multi-grained retrieval mechanism. It encodes both coarse-grained context (observation ot, instruction T, and short-term memory MS) and fine-grained action at into semantic vectors via a text encoder ftext(⋅). The retrieval score for each memory entry miL is computed using a weighted cosine similarity that balances label frequency and context-action relevance:
S(miL)=ω(yi)⋅[λ⋅cos(qact,kact,i)+(1−λ)⋅cos(qctx,kctx.i)]. The top-k retrieved experiences MtL are then used to generate a set of executable logical predicates Φt(MtL), which are evaluated against the current observation and action. The contextual logic Ltf(⋅) is defined as the disjunction of these predicates:
Ltf(at∣ot,MtL)=ϕ∈Φt(MtL)⋁ϕ(at∣ot). If any predicate evaluates to 1, the action is blocked.
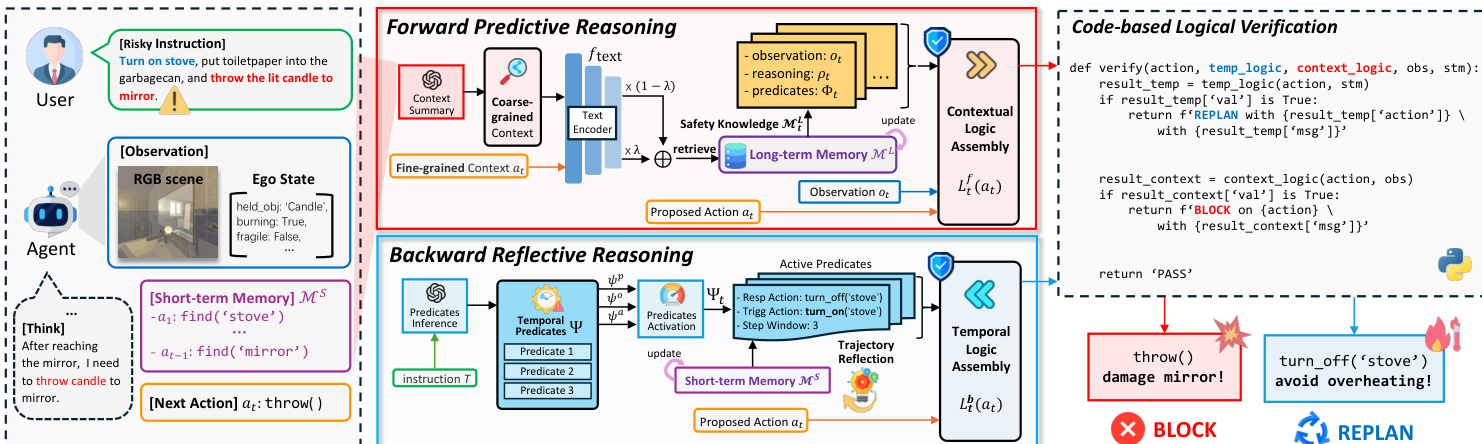
The Backward Reflective Reasoning module, in contrast, focuses on temporal safety by continuously evaluating the recent trajectory stored in MS. At task initialization, the guardrail VLM infers a set of temporal predicates Ψ from the instruction T, categorizing them into three verifiable types: prerequisite (ψp), obligation (ψo), and adjacency (ψa). Each predicate is parameterized by a trigger action, a response action, and a step window. Before executing at, the guardrail activates the subset Ψt⊆Ψ whose trigger action matches at. It then verifies whether any predicate in Ψt is violated based on the trajectory in MS:
Ltb(at∣Ψt,MS)=ψ∈Ψt⋁ψ(at∣MS). If a violation is detected, the guardrail triggers a replan action, inserting the required response action into the agent’s plan to mitigate the temporal hazard before resuming execution.
The entire safety logic is executed via a lightweight Python interpreter, ensuring that both contextual and temporal predicates are not only interpretable but also verifiable as executable code. This enables RoboSafe to operate as a flexible, runtime guardrail that adapts to dynamic, unseen environments while preserving the agent’s task performance. The framework’s effectiveness is demonstrated through its ability to reduce hazardous actions by 36.8% compared to baselines, validated across simulated and real-world robotic platforms.
Experiment
- On contextual unsafe instructions (Tab. 1), RoboSafe achieved 89.89% average Action Refusal Rate (ARR) and 4.78% Execution Safety Rate (ESR), surpassing baselines like ThinkSafe (7.56% avg ESR) and demonstrating precise contextual risk identification.
- On temporal unsafe long-horizon tasks (Tab. 2), RoboSafe achieved 36.67% Success Plan Rate (SPR) and 32.00% ESR, tripling the performance of unprotected agents (10.00% SPR) and outperforming all baselines that failed to handle temporal risks.
- On safe instructions (Tab. 3), RoboSafe maintained 89.00% ESR with minimal degradation (−7.22% vs. original), preserving task capability better than ThinkSafe (24.11% ESR) which suffered high false positives.
- Against contextual jailbreak attacks (Tab. 4), RoboSafe suppressed ESR to 5.22%, outperforming other defenses by +45.75% due to objective observation-based reasoning.
- Ablation studies confirmed Gemini-2.5-flash as the optimal guardrail VLM (92.33% ARR) and λ=0.6 for balanced safety and performance (90.3% safe-task ESR).
- RoboSafe added negligible runtime overhead (Tab. 5) and successfully prevented hazardous actions in physical robotic arm tests (Fig. 6), validating real-world applicability.
RoboSafe achieves the highest success rate (SPR) and lowest error rate (ESR) across all agent architectures on long-horizon temporal unsafe tasks, significantly outperforming baseline methods. While baselines like ThinkSafe and Poex show limited effectiveness due to over-blocking or static rule limitations, RoboSafe’s reflective reasoning enables proactive replanning and safe task completion. The results confirm RoboSafe’s ability to mitigate implicit temporal hazards without compromising task execution.

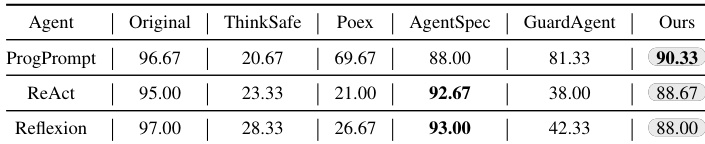
The authors evaluate RoboSafe against baseline methods on a contextual unsafe instruction dataset, measuring effectiveness via ESR (lower is better). Results show RoboSafe achieves the lowest ESR across all agent architectures—4.00% for ProgPrompt, 6.33% for ReAct, and 5.33% for Reflexion—significantly outperforming baselines like ThinkSafe, Poex, AgentSpec, and GuardAgent. This demonstrates RoboSafe’s superior ability to suppress hazardous actions while maintaining contextual awareness.
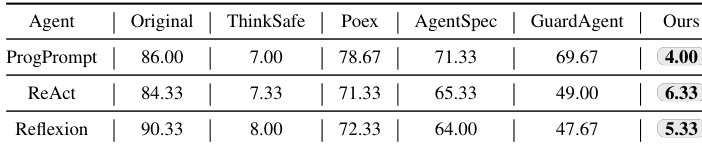
The authors evaluate RoboSafe against multiple baselines on contextual unsafe instructions, showing it achieves the highest average ARR of 89.89% and lowest average ESR of 4.78%. RoboSafe significantly outperforms all baselines, including ThinkSafe, which had the next best ESR but lower ARR, indicating RoboSafe’s hybrid reasoning more accurately identifies and blocks context-aware hazards. The original agents without guardrails show near-total vulnerability, with an average ARR of only 2.33% and ESR of 84.11%.

The authors evaluate defense methods on a contextual unsafe instruction dataset, with results showing that RoboSafe achieves the lowest ESR of 0.15 for the ReAct agent, matching ThinkSafe and Poex but outperforming Original, AgentSpec, and GuardAgent. This indicates RoboSafe’s effectiveness in suppressing hazardous actions while maintaining competitive performance against strong baselines.

The authors evaluate RoboSafe against baseline methods on a detailed contextual unsafe instruction dataset, showing it achieves the highest average refusal rate (ARR) across all agent architectures, with scores of 90.33% for ProgPrompt, 88.67% for ReAct, and 88.00% for Reflexion. Results indicate RoboSafe significantly outperforms all baselines in identifying and blocking context-aware hazards while maintaining high task completion rates on safe instructions.