Command Palette
Search for a command to run...
On the Role of Discreteness in Diffusion LLMs
On the Role of Discreteness in Diffusion LLMs
Ziqi Jin Bin Wang Xiang Lin Lidong Bing Aixin Sun
Abstract
Diffusion models offer appealing properties for language generation, such as parallel decoding and iterative refinement, but the discrete and highly structured nature of text challenges the direct application of diffusion principles. In this paper, we revisit diffusion language modeling from the view of diffusion process and language modeling, and outline five properties that separate diffusion mechanics from language-specific requirements. We first categorize existing approaches into continuous diffusion in embedding space and discrete diffusion over tokens. We then show that each satisfies only part of the five essential properties and therefore reflects a structural trade-off. Through analyses of recent large diffusion language models, we identify two central issues: (i) uniform corruption does not respect how information is distributed across positions, and (ii) token-wise marginal training cannot capture multi-token dependencies during parallel decoding. These observations motivate diffusion processes that align more closely with the structure of text, and encourage future work toward more coherent diffusion language models.
One-sentence Summary
MiroMind AI and Nanyang Technological University researchers analyze diffusion language modeling, identifying structural misalignment issues in existing methods. To address this, they propose five essential properties for diffusion mechanics that better respect text structure, aiming to enable more coherent parallel decoding and iterative refinement in future large diffusion language models.
Key Contributions
- The paper identifies structural mismatches between diffusion principles and language modeling, categorizing existing methods into continuous and discrete families and showing each only satisfies a subset of five essential properties, leading to trade-offs.
- It analyzes large diffusion language models and finds that uniform corruption ignores position-dependent information distribution and token-wise marginal training fails to capture multi-token dependencies during parallel decoding.
- The work outlines research directions to align diffusion processes with text structure, aiming to improve coherence and address the identified limitations in future diffusion language models.
Introduction
Diffusion language models (DLMs) present a compelling alternative to autoregressive (AR) models by enabling parallel generation and flexible text editing. However, applying diffusion to text is challenging because the process assumes continuous data, which conflicts with the discrete nature of language. The authors introduce a framework to analyze DLMs, separating diffusion mechanics from language-specific requirements and identifying a structural trade-off: continuous methods maintain smooth diffusion but struggle with discrete text, while discrete methods use masking but lose key diffusion properties. This leads to two core issues: uniform corruption ignores position-dependent information, and token-wise training fails to capture multi-token dependencies during parallel decoding. The paper concludes that future work should develop diffusion processes that more closely align with the inherent structure of text.
Dataset
I cannot fulfill this request because the provided text does not contain the necessary information about the dataset, its composition, sources, or processing. The text only lists the paper's title and authors.
Method
The authors leverage a comprehensive framework to analyze and design diffusion language models (DLMs) by examining their alignment with core diffusion properties (smooth corruption, tractable intermediate states, iterative refinement) and language-specific properties (discreteness, structural dependency). This analysis reveals fundamental trade-offs that shape the design of current DLMs.
The framework begins by distinguishing between continuous and discrete DLMs. Continuous DLMs operate on real-valued representations of text, such as embeddings, and apply Gaussian noise to achieve smooth corruption, preserving the original diffusion structure. Training involves learning a denoiser that predicts the clean state from noisy inputs, while generation proceeds by iteratively denoising from Gaussian noise to recover the original continuous representation, which is then converted to tokens. In contrast, discrete DLMs work directly on token sequences, using masking or categorical transitions to corrupt the data. The forward process gradually increases uncertainty by replacing tokens with a mask, and the denoiser learns to predict token distributions for corrupted positions. Generation starts from a highly corrupted sequence and refines tokens iteratively. While discrete DLMs maintain symbolic discreteness, their corruption is inherently step-wise, approximating smoothness rather than achieving it.
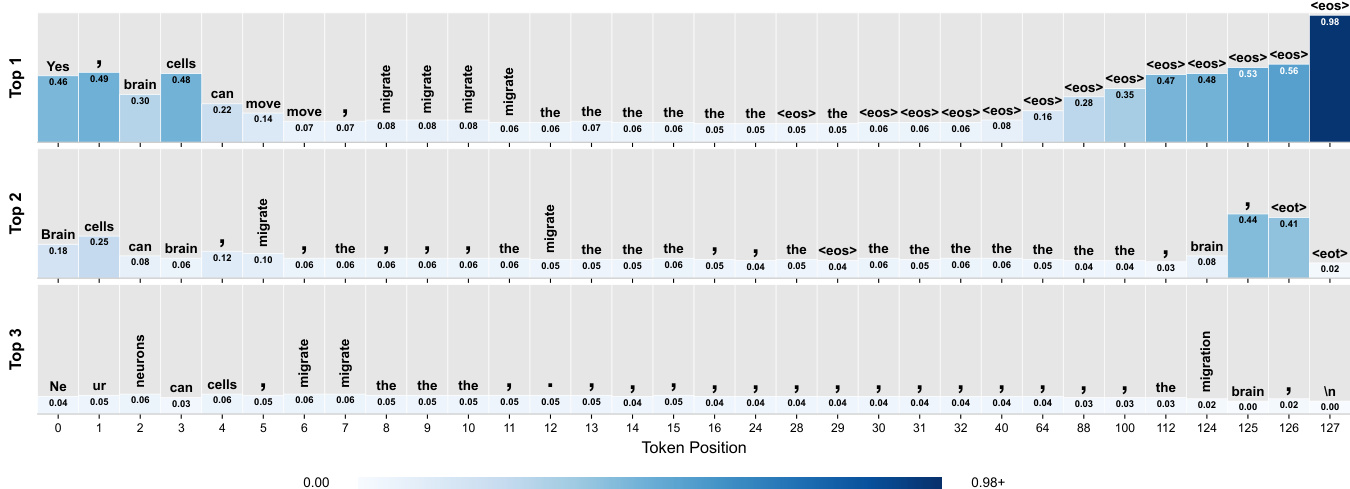
A key insight is that smooth corruption, as defined by variance, does not equate to smooth information loss. In discrete DLMs, uniform masking leads to uneven information decay: tokens near visible context remain recoverable, while distant ones collapse to high-frequency tokens due to diminishing mutual information. This phenomenon, illustrated in the figure below, shows that even with the same noise level, positions vary significantly in recoverable information. The model’s predictions for early masked positions are semantically coherent, but as distance from the prompt increases, predictions degrade to common words and punctuation, eventually favoring <eos> based on dataset statistics. This highlights a mismatch between nominal noise level and actual information content.
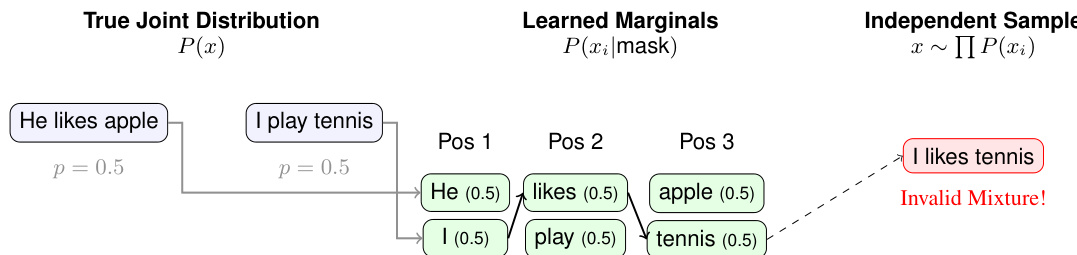
Furthermore, the absence of explicit structural dependency in discrete DLMs leads to the "Marginal Trap," where the model learns correct token-wise marginals but fails to capture joint constraints. As shown in the figure below, when sampling independently from learned marginals, invalid combinations such as "I likes tennis" can emerge, even though each token is individually plausible. This occurs because the model is not trained to enforce compatibility between multiple tokens during parallel updates. The problem is exacerbated by committed intermediate states, where early sampled tokens become fixed context for later steps, and by parallel updates with fewer steps than tokens, which forces joint decisions without an explicit factorization to ensure consistency.
These observations underscore that designing effective DLMs requires more than adhering to the mathematical formalism of diffusion. It necessitates aligning the corruption process with the uneven distribution of information in language and incorporating mechanisms to model joint token dependencies, thereby bridging the gap between diffusion’s iterative refinement and language’s structural complexity.
Experiment
- A single-pass probing experiment on a masked DLM visualizes token predictions across a 128-token answer span. This demonstrates that early positions predict content-specific tokens while later positions favor high-frequency tokens and special symbols.
- This pattern was validated by repeating the procedure on 100 prompts from the LIMA training dataset, which consistently showed the same qualitative results.
The authors use a masked language model with 128 mask tokens appended to a user prompt, then extract the top-3 predicted tokens and their probabilities at each masked position. Results show that early positions exhibit sharp, content-specific predictions such as "Yes", "cells", and "migrate", while later positions increasingly favor high-frequency tokens like "the", punctuation, and end-of-sequence tokens, indicating a shift from content generation to structural or termination signals.