Command Palette
Search for a command to run...
Evaluating Parameter Efficient Methods for RLVR
Evaluating Parameter Efficient Methods for RLVR
Qingyu Yin Yulun Wu Zhennan Shen Sunbowen Li Zhilin Wang Yanshu Li Chak Tou Leong Jiale Kang Jinjin Gu
Abstract
We systematically evaluate Parameter-Efficient Fine-Tuning (PEFT) methods under the paradigm of Reinforcement Learning with Verifiable Rewards (RLVR). RLVR incentivizes language models to enhance their reasoning capabilities through verifiable feedback; however, while methods like LoRA are commonly used, the optimal PEFT architecture for RLVR remains unidentified. In this work, we conduct the first comprehensive evaluation of over 12 PEFT methodologies across the DeepSeek-R1-Distill families on mathematical reasoning benchmarks. Our empirical results challenge the default adoption of standard LoRA with three main findings. First, we demonstrate that structural variants, such as DoRA, AdaLoRA, and MiSS, consistently outperform LoRA. Second, we uncover a spectral collapse phenomenon in SVD-informed initialization strategies ( extit{e.g.,} PiSSA, MiLoRA), attributing their failure to a fundamental misalignment between principal-component updates and RL optimization. Furthermore, our ablations reveal that extreme parameter reduction ( extit{e.g.,} VeRA, Rank-1) severely bottlenecks reasoning capacity. We further conduct ablation studies and scaling experiments to validate our findings. This work provides a definitive guide for advocating for more exploration for parameter-efficient RL methods.
One-sentence Summary
Zhejiang University, HKUST, WUST, USTC, Brown University, Hong Kong Polytechnic University, and INSAIT propose that structural variants like DoRA outperform standard LoRA in Reinforcement Learning with Verifiable Rewards (RLVR) for mathematical reasoning, due to better alignment with RL's off-principal optimization dynamics, while SVD-based initialization fails due to spectral misalignment and extreme parameter reduction creates an expressivity bottleneck.
Key Contributions
-
This work addresses the challenge of efficient training in Reinforcement Learning with Verifiable Rewards (RLVR), where sparse binary feedback limits the effectiveness of full-parameter fine-tuning, necessitating parameter-efficient methods to reduce computational cost while preserving reasoning performance.
-
The study reveals that structural variants of LoRA—such as DoRA, AdaLoRA, and MiSS—consistently outperform standard LoRA in RLVR, while SVD-informed initialization strategies (e.g., PiSSA, MiLoRA) fail due to spectral collapse, indicating a fundamental misalignment between their update mechanisms and the sparse optimization dynamics of RL.
-
Empirical evaluations across the DeepSeek-R1-Distill family on mathematical reasoning benchmarks demonstrate that extreme parameter reduction (e.g., VeRA, Rank-1) severely degrades reasoning capacity, and ablation studies confirm the robustness of these findings across diverse training configurations and loss types.
Introduction
The authors investigate parameter-efficient fine-tuning (PEFT) methods within the context of Reinforcement Learning with Verifiable Rewards (RLVR), a paradigm that enhances language models' reasoning abilities through sparse, binary feedback. While LoRA has become the default PEFT approach in RLVR, its suitability for the unique optimization dynamics of reinforcement learning—characterized by sparse supervision and off-principal updates—remains unproven. Prior work has largely overlooked the performance differences among PEFT variants in this setting, and SVD-based initialization strategies have shown unexpected failures despite theoretical promise. The authors conduct the first comprehensive evaluation of over 12 PEFT methods across multiple models and mathematical reasoning benchmarks, revealing that structural variants like DoRA, AdaLoRA, and MiSS consistently outperform standard LoRA. They identify a spectral collapse phenomenon in SVD-informed methods, attributing their failure to a misalignment between principal-component updates and RL optimization. Additionally, they show that extreme parameter reduction severely limits reasoning capacity. These findings challenge the status quo and advocate for a more nuanced selection of PEFT architectures in RLVR, emphasizing structural design over mere parameter count.
Method
The authors leverage Reinforcement Learning with Verifiable Rewards (RLVR) to enhance large language model (LLM) reasoning capabilities by incorporating deterministic verifiers that provide sparse but accurate binary feedback. This approach enables the elicitation of complex behaviors such as self-correction and iterative refinement, distinguishing it from traditional RLHF. The foundational framework for many recent advancements in this domain is Group Relative Policy Optimization (GRPO), which eliminates the need for a separate critic model by estimating advantages through group-level statistics. For a given prompt q, GRPO samples a group of G responses {o1,…,oG} and optimizes the following surrogate objective:
IGRPO(θ)=Eq∼D,{oi}∼πθoldG1i=1∑G∣oi∣1t=1∑∣oi∣min(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1±ϵ)A^i)where A^i=std({Ri})(Ri−mean({Rj})) represents the standardized advantage within the group. This formulation allows for relative comparison of responses within a batch, promoting policy updates based on comparative performance rather than absolute reward values.
To address challenges such as entropy collapse and training instability in long chain-of-thought (CoT) scenarios, several optimized variants of GRPO have been proposed. One such variant is Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO), which introduces a Clip-Higher strategy by decoupling the clipping range into ϵlow and ϵhigh. By setting a larger ϵhigh, such as 0.28, DAPO allows for greater exploration of low-probability tokens, thereby maintaining policy diversity. Additionally, DAPO employs Dynamic Sampling to filter out prompts where all outputs yield identical rewards—either all 0 or all 1—ensuring consistent gradient signals and improved sample efficiency.
Another refinement is Dr. GRPO, which addresses systematic biases present in the original GRPO formulation. Dr. GRPO removes the per-response length normalization term ∣oi∣1, which can inadvertently favor longer incorrect responses over concise correct ones. Furthermore, it eliminates the group-level standard deviation in advantage estimation to mitigate difficulty bias, where questions with low reward variance—either too easy or too hard—are assigned disproportionately high weights. These modifications improve the robustness and fairness of the training process.
Following prior work, the authors adopt DAPO as their standard training algorithm, using it as the baseline for comparative analysis while treating other methods as ablation experiments.
Experiment
- Conducted a large-scale evaluation of 12 PEFT methods in RLVR using DeepSeek-R1-Distill models across MATH-500, AIME, AMC, Minerva, and HMMT benchmarks, validating the superiority of structural variants over standard LoRA.
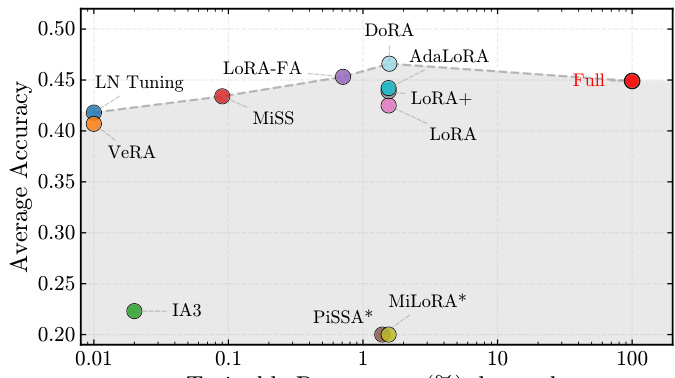
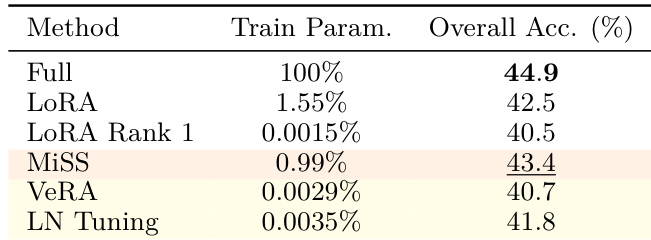
- Structural variants (DoRA, MiSS, AdaLoRA) consistently outperform standard LoRA and full-parameter fine-tuning, with DoRA achieving 46.6% average accuracy, surpassing full-parameter fine-tuning (44.9%) on key benchmarks like AIME and AMC.
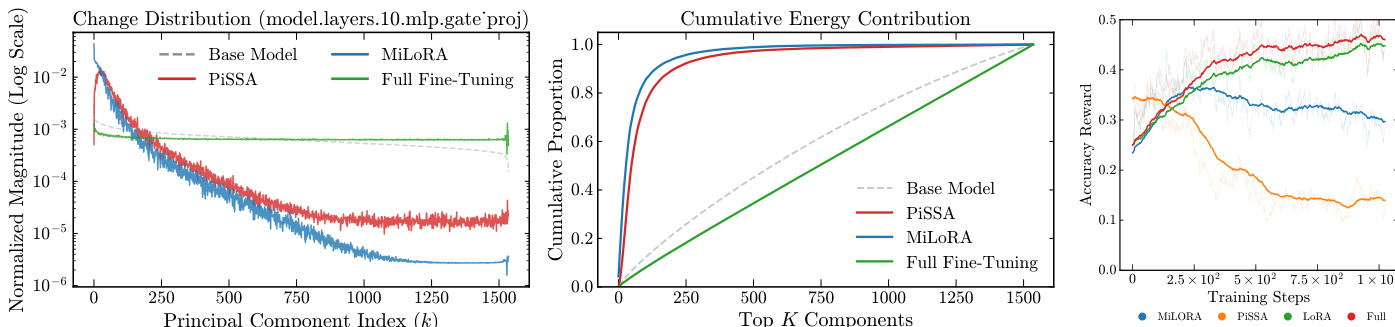
- SVD-based initialization strategies (e.g., PiSSA, MiLoRA) fail due to structural misalignment with RLVR’s off-principal update dynamics; PiSSA collapses to 0.2% accuracy, while MiLoRA degrades to 18.0% despite theoretical alignment.
- Extreme parameter reduction methods (VeRA, IA³, LN-tuning) cause performance collapse (e.g., VeRA at 40.7%, IA³ at 22.3%), revealing a critical expressivity floor in RLVR that requires sufficient trainable capacity for complex reasoning.
- Ablation studies confirm that learning rate scaling, moderate LoRA rank (r=16, 32), and larger batch sizes improve performance, while RLVR algorithm choice has minimal impact on PEFT efficacy.
- Scaling to the 7B model shows consistent results: DoRA and LoRA+ achieve 55.0% average accuracy, confirming the generalizability of findings across model scales.
The authors use a comprehensive benchmark to evaluate parameter-efficient methods for reinforcement learning with verifiable rewards, focusing on mathematical reasoning tasks. Results show that standard LoRA underperforms compared to structural variants like MiSS, which achieve higher accuracy despite using fewer trainable parameters, while extreme compression methods such as VeRA and LN Tuning lead to significant performance drops.
The authors use a large-scale benchmark to evaluate over 12 parameter-efficient fine-tuning methods in reinforcement learning with verifiable rewards, finding that standard LoRA is suboptimal and that structural variants like DoRA and MiSS consistently outperform it, often surpassing full-parameter fine-tuning. Results show that SVD-based initialization strategies fail due to a fundamental misalignment with RL's off-principal update dynamics, while extreme parameter reduction methods collapse performance by creating an expressivity bottleneck.

The authors use a large-scale benchmark to evaluate parameter-efficient methods for reinforcement learning with verifiable rewards, focusing on mathematical reasoning tasks. Results show that structural variants like DoRA and LoRA+ outperform standard LoRA across multiple benchmarks, with DoRA achieving the highest average accuracy and consistently surpassing full-parameter fine-tuning on key tasks.

The authors conduct ablation studies to assess the impact of key training hyperparameters on parameter-efficient reinforcement learning. Results show that while batch size and learning rate have some influence, the choice of RLVR algorithm and LoRA rank have a more significant effect on performance, with higher ranks and certain algorithms yielding better outcomes.

The authors use spectral analysis to examine the update dynamics of different parameter-efficient methods in reinforcement learning with verifiable rewards. Results show that SVD-based initialization strategies like PiSSA and MiLoRA fail due to structural misalignment with RLVR's off-principal update dynamics, leading to performance collapse despite theoretical alignment. In contrast, structural variants such as DoRA and MiSS achieve superior reasoning accuracy by better aligning with the optimization landscape of RLVR.