Command Palette
Search for a command to run...
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
DiffThinker: Towards Generative Multimodal Reasoning with Diffusion Models
Zefeng He Xiaoye Qu Yafu Li Tong Zhu Siyuan Huang Yu Cheng
Abstract
While recent Multimodal Large Language Models (MLLMs) have attained significant strides in multimodal reasoning, their reasoning processes remain predominantly text-centric, leading to suboptimal performance in complex long-horizon, vision-centric tasks. In this paper, we establish a novel Generative Multimodal Reasoning paradigm and introduce DiffThinker, a diffusion-based reasoning framework. Conceptually, DiffThinker reformulates multimodal reasoning as a native generative image-to-image task, achieving superior logical consistency and spatial precision in vision-centric tasks. We perform a systematic comparison between DiffThinker and MLLMs, providing the first in-depth investigation into the intrinsic characteristics of this paradigm, revealing four core properties: efficiency, controllability, native parallelism, and collaboration. Extensive experiments across four domains (sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration) demonstrate that DiffThinker significantly outperforms leading closed source models including GPT-5 (+314.2%) and Gemini-3-Flash (+111.6%), as well as the fine-tuned Qwen3-VL-32B baseline (+39.0%), highlighting generative multimodal reasoning as a promising approach for vision-centric reasoning.
One-sentence Summary
The authors, affiliated with institutions including 1, 2, 3, and 4, propose DiffThinker, a diffusion-based generative reasoning framework that reformulates multimodal reasoning as a native image-to-image task, achieving superior logical consistency and spatial precision in vision-centric, long-horizon problems by leveraging native parallelism and controllability, outperforming GPT-5, Gemini-3-Flash, and Qwen3-VL-32B across multiple domains.
Key Contributions
-
The paper introduces DiffThinker, a novel generative multimodal reasoning paradigm that reformulates multimodal reasoning as a native image-to-image generation task using diffusion models, addressing the limitations of text-centric reasoning in vision-centric, long-horizon tasks.
-
Through systematic evaluation across four domains—sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration—DiffThinker demonstrates superior performance, outperforming state-of-the-art models including GPT-5 (+314.2%) and Gemini-3-Flash (+111.6%), while revealing four key properties: efficiency, controllability, native parallelism, and collaboration.
-
The framework achieves high logical consistency and spatial precision by operating directly in visual space, and its extension to video generation (DiffThinker-Video) further validates its effectiveness, showing that generative multimodal reasoning is a promising direction for complex vision-centric reasoning tasks.
Introduction
The authors address the limitations of current Multimodal Large Language Models (MLLMs), which rely on text-centric reasoning through lengthy Chain-of-Thought processes and iterative "Thinking with Image" interactions. These approaches suffer from high latency, uncontrollable generation lengths, and poor tracking of visual state over long reasoning sequences—critical bottlenecks in complex, vision-centric tasks like spatial configuration and combinatorial optimization. To overcome these challenges, the authors introduce DiffThinker, a diffusion-based framework that reformulates multimodal reasoning as a native image-to-image generation task, shifting reasoning from symbolic to visual space. This paradigm enables superior spatial precision and logical consistency, while revealing four key advantages: efficiency, controllability, native parallelism in exploring multiple solution paths, and collaborative potential with MLLMs. Extensive evaluations across four domains show DiffThinker outperforms leading models including GPT-5 and Gemini-3-Flash by up to 314.2%, establishing generative multimodal reasoning as a powerful alternative for vision-driven problem solving.
Dataset
- The dataset comprises samples synthesized from COCO (Lin et al., 2014), used for both training and testing across five jigsaw puzzle task categories.
- Five independent models are trained, each tailored to one of the five task categories, with evaluation conducted on corresponding test benchmarks.
- All training data undergoes thorough deduplication to ensure data quality and prevent overfitting.
- DiffThinker and the baseline MLLMs are trained on identical data distributions to enable a fair comparison.
- The training split is derived directly from COCO, with no additional external sources used.
- No explicit cropping or metadata construction is described; the focus is on using raw COCO images for puzzle synthesis.
- Mixture ratios for the five task categories are not specified, but each model is trained on data aligned with its respective category.
Method
The authors leverage a diffusion-based framework to implement DiffThinker, a generative multimodal reasoner designed for complex reasoning tasks. The core architecture is built upon a Multimodal Diffusion Transformer (MMDiT), which operates within the latent space of a Variational Autoencoder (VAE) to ensure computational efficiency. This framework is grounded in Flow Matching, a theoretical approach that models the transformation from noise to data as a continuous flow governed by Ordinary Differential Equations (ODEs). The model's training process involves encoding a ground-truth image y into a latent representation x0 using the VAE encoder E. A noise latent x1 is sampled from a standard normal distribution, and an intermediate latent xt is generated via linear interpolation between x0 and x1 at a randomly sampled timestep t. The target velocity field vt=x0−x1 represents the desired flow from noise to data. The MMDiT is trained to predict this velocity field, with the objective function defined as the mean squared error between the predicted and target velocities, conditioned on the user instruction S and derived via a multimodal large language model (MLLM) ϕ to produce a conditioning latent h.
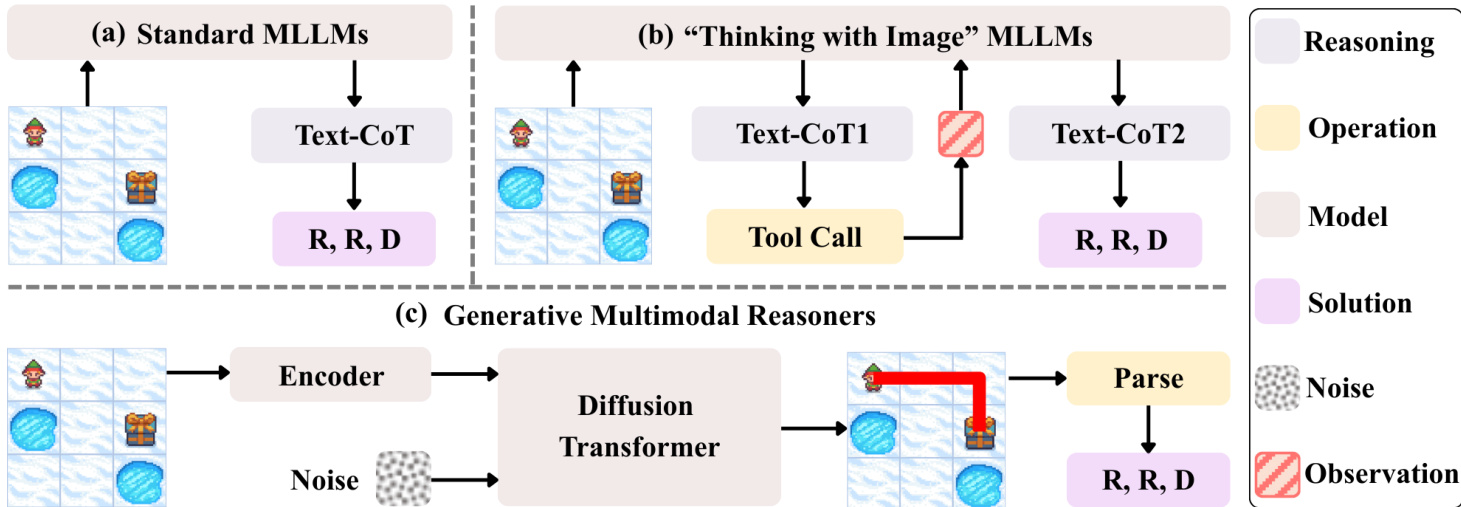
As shown in the figure below, the overall framework of DiffThinker is structured into three main components. The first component, labeled (a), represents standard Multimodal Large Language Models (MLLMs) that process the input image and text to generate a reasoning trace, followed by a text-based Chain-of-Thought (Text-CoT) to produce a solution. The second component, (b), illustrates "Thinking with Image" MLLMs, which incorporate visual observations into the reasoning process through a tool call mechanism, generating intermediate reasoning steps (Text-CoT1, Text-CoT2) before producing a solution. The third component, (c), details the generative multimodal reasoner, where the input image is encoded and combined with noise, processed by a Diffusion Transformer, and then parsed to generate a final solution. This architecture enables the model to reason through complex tasks by iteratively refining its understanding and solution in a latent space.
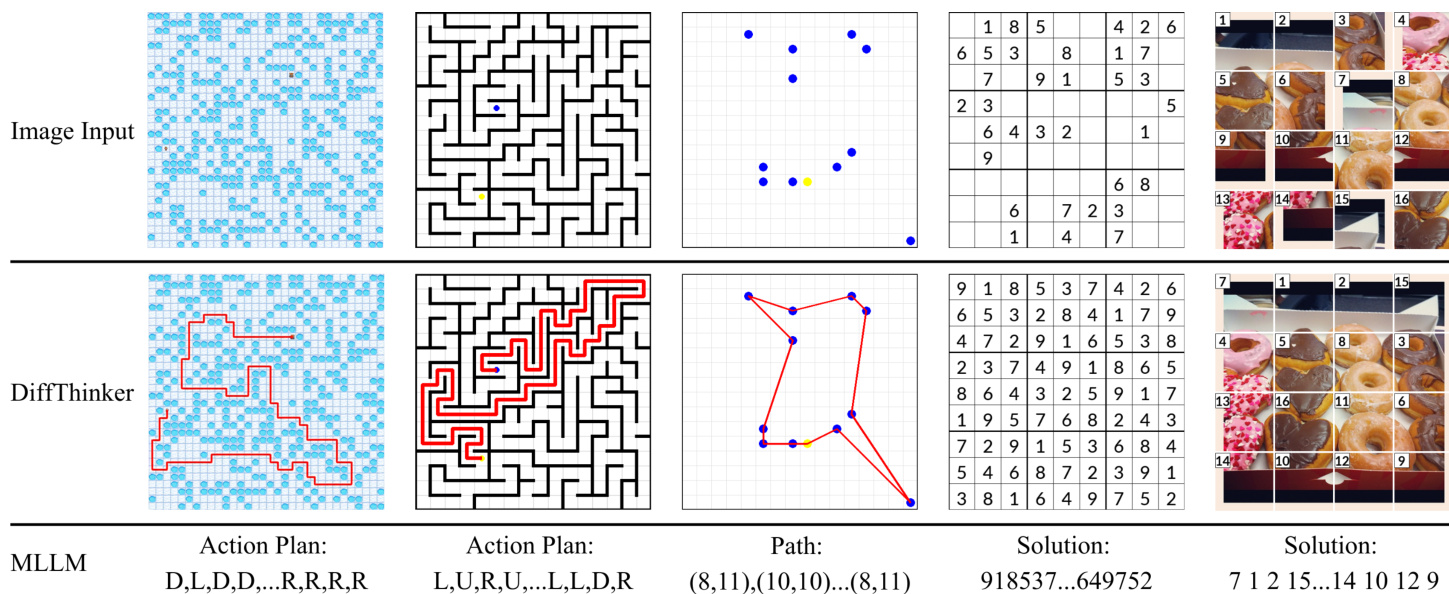
During inference, the model begins with an initial noise latent xt=0=x1 and numerically integrates the learned velocity field vθ(xt,t,h) using an ODE solver. A first-order Euler method with a step size Δt=1/T is employed, where the update rule is xt+Δt=xt+Δt⋅vθ(xt,t,h). After T integration steps, the final latent xt=1, which approximates the data distribution, is decoded back to pixel space using the VAE decoder to produce the visual solution ysol. This process allows DiffThinker to generate coherent and contextually relevant solutions for a range of tasks, including sequential planning, combinatorial optimization, constraint satisfaction, and spatial configuration, as demonstrated in the provided examples.
To facilitate training, the authors design task-specific partial reward functions for each domain to address the sparsity of binary rewards. For sequential planning tasks, a prefix matching reward evaluates the longest continuous sequence of correct actions. For the Traveling Salesperson Problem (TSP), the reward is tiered, first requiring the correct set of cities before rewarding path length precision. In Sudoku, the reward is based on the proportion of correctly filled cells in the completed grid. For jigsaw puzzles, the reward measures the positional accuracy of the restored image patches. These reward functions are designed to provide more informative feedback during the policy optimization process, enabling the model to learn complex reasoning patterns effectively.
Experiment
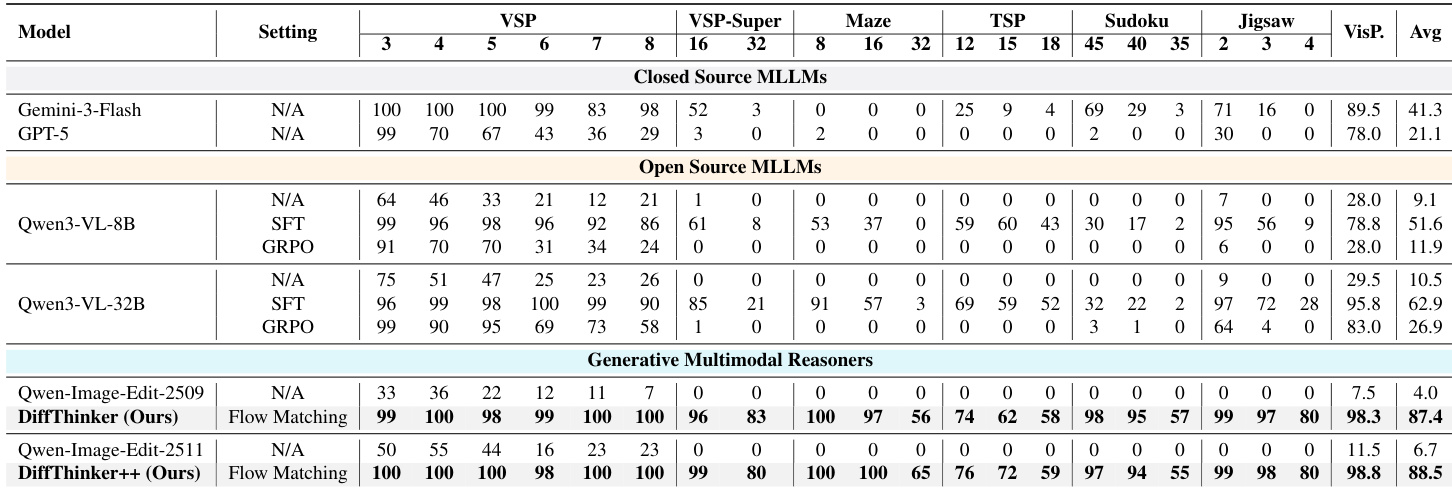
- DiffThinker validates its generative multimodal reasoning paradigm across seven tasks: VSP, VSP-Super, Maze, TSP, Sudoku, Jigsaw, and VisPuzzle, demonstrating superior performance in vision-centric, long-horizon reasoning.
- On all tasks, DiffThinker achieves state-of-the-art results, surpassing GPT-5 (+314.2%), Gemini-3-Flash (+111.6%), and fine-tuned Qwen3-VL-32B (+39.0%) with fewer parameters.
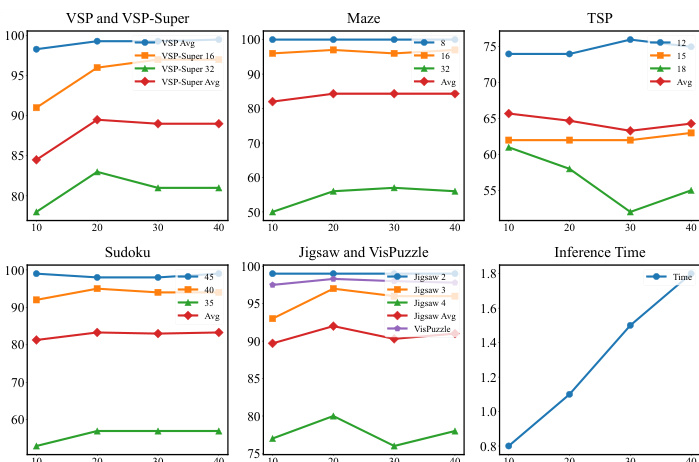
- In sequential planning (VSP, VSP-Super, Maze), DiffThinker maintains high accuracy as complexity increases, while MLLMs degrade significantly.
- In spatial configuration (Jigsaw, VisPuzzle), DiffThinker achieves near-perfect performance; in combinatorial optimization (TSP) and constraint satisfaction (Sudoku), it delivers exceptional results.
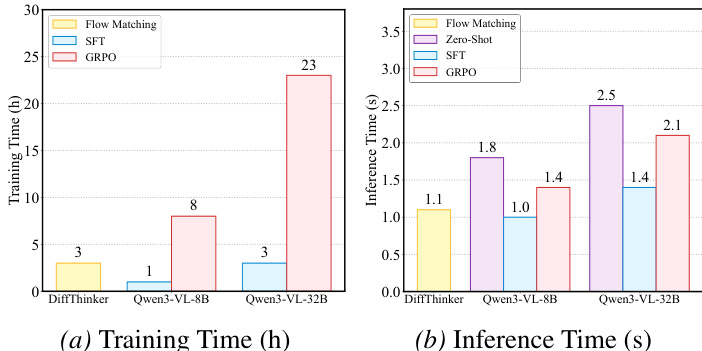
- DiffThinker exhibits competitive computational efficiency: training duration comparable to Qwen3-VL-32B (SFT), and inference latency of 1.1s, faster than Qwen3-VL-32B (1.4s) and comparable to Qwen3-VL-8B (1.0s).
- The model enables controllable reasoning via fixed-step diffusion, ensuring deterministic latency, in contrast to MLLMs’ unpredictable autoregressive inference.
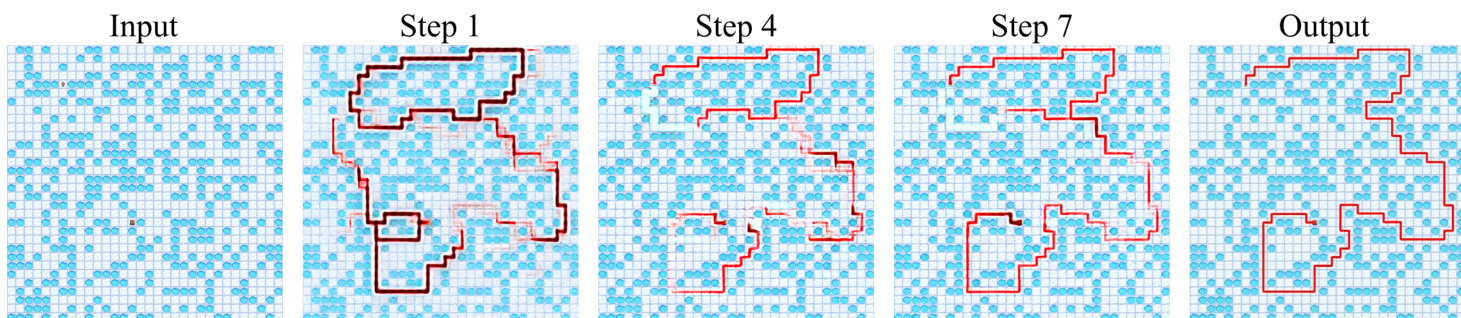
- DiffThinker performs native parallel reasoning, exploring multiple candidate paths simultaneously and refining them iteratively, leading to higher logical consistency and spatial precision.
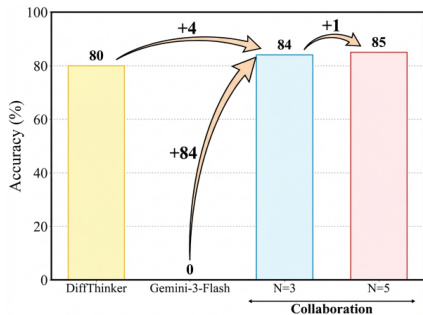
- A collaborative framework with MLLMs improves accuracy on Jigsaw level-4, where DiffThinker generates candidate solutions and MLLMs verify them, leveraging complementary strengths.
- Ablation studies confirm optimal performance at 20 inference steps, with accuracy plateauing beyond this point; performance scales consistently with training data size, achieving over 90% accuracy on Maze level-32 with 10⁵ samples.
- Classifier-Free Guidance (CFG) scale of 4 yields peak performance, balancing logical precision and generative fidelity.
- Video-based reasoning (DiffThinker-Video) shows lower accuracy and higher latency (2.0s vs. 1.1s), highlighting the computational inefficiency of current video generation for reasoning tasks.
The authors use DiffThinker, a diffusion-based model, and compare its training and inference times against Qwen3-VL-8B and Qwen3-VL-32B models across different training methods. Results show that DiffThinker achieves competitive training efficiency, with a training time of 3 hours, comparable to Qwen3-VL-8B (1 hour) and significantly lower than Qwen3-VL-32B (23 hours). Inference time for DiffThinker is 1.1 seconds, which is faster than Qwen3-VL-32B (2.1 seconds) and comparable to Qwen3-VL-8B (1.0 seconds), demonstrating its efficiency in both training and inference.
The authors use DiffThinker to evaluate its performance in a collaborative framework with MLLMs, where DiffThinker generates multiple candidate solutions and the MLLM verifies them. Results show that collaboration significantly improves accuracy, with DiffThinker achieving 80% accuracy alone and reaching 85% when combined with five candidates, demonstrating that the partnership outperforms either model in isolation.
Results show that DiffThinker achieves state-of-the-art performance across seven tasks, significantly outperforming GPT-5, Gemini-3-Flash, and fine-tuned Qwen3-VL models, particularly in complex long-horizon, vision-centric reasoning tasks. The model maintains high accuracy as task difficulty increases, demonstrating superior logical consistency and spatial precision compared to traditional MLLMs.
The authors use DiffThinker, a diffusion-based model, to perform multimodal reasoning tasks by reformulating them as image-to-image generation problems. The table compares the training configurations for three different frameworks—DiffSynth-Studio (Flow Matching), SWIFT (SFT), and verl (GRPO)—highlighting differences in hyperparameters such as learning rate, LoRA rank, and batch size. Results show that DiffThinker achieves state-of-the-art performance across seven tasks, surpassing models like GPT-5 and Gemini-3-Flash, while maintaining competitive training efficiency and inference latency.

The authors use DiffThinker, a generative multimodal reasoning model, to solve a range of vision-centric tasks including spatial planning, combinatorial optimization, and constraint satisfaction. Results show that DiffThinker achieves state-of-the-art performance across seven tasks, significantly outperforming both closed-source and open-source MLLMs, with an average accuracy of 87.4% compared to 41.3% for Gemini-3-Flash and 21.1% for GPT-5.