Command Palette
Search for a command to run...
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Zhe Huang Hao Wen Aiming Hao Bingze Song Meiqi Wu Jiahong Wu Xiangxiang Chu Sheng Lu Haoqian Wang
Abstract
Multimodal Large Language Models (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise ell1 advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.
One-sentence Summary
The authors from Tsinghua University, Beihang University, and AMAP, Alibaba Group propose DualityForge, a diffusion-based framework for synthesizing counterfactual video QA pairs with structured context, enabling the construction of DualityVidQA and the DNA-Train-7B model that uses pair-wise ℓ₁ advantage normalization for stable contrastive training, significantly reducing hallucinations in MLLMs on counterfactual video reasoning while improving generalization across benchmarks.
Key Contributions
- We propose DualityForge, a novel counterfactual data synthesis framework that uses controllable diffusion-based video editing with embedded structured context to generate precise counterfactual video scenarios, enabling the automatic creation of high-quality, paired video-QA data for contrastive training.
- We introduce DualityVidQA, a large-scale dataset with 144K video-QA pairs (104K for SFT, 40K for RL) and 81K unique videos, designed to systematically evaluate and reduce hallucinations in MLLMs through contrastive learning on real vs. edited video pairs.
- We develop DNA-Train, a two-stage SFT-RL training method that applies pair-wise ℓ₁ advantage normalization during reinforcement learning, leading to more stable optimization and a 24.0% relative improvement over Qwen2.5-VL-7B on counterfactual video QA, with strong generalization across hallucination and general-purpose benchmarks.
Introduction
Multimodal Large Language Models (MLLMs) have made significant strides in video understanding but remain prone to visual ungrounded hallucinations—generating plausible-sounding yet incorrect answers by relying on language priors rather than actual visual content, especially in counterfactual scenarios that violate physical or commonsense norms. This issue is exacerbated by the inherent imbalance between vast textual and limited video training data, and prior attempts to mitigate hallucinations through text-only data modification are insufficient and labor-intensive. The authors introduce DualityForge, a diffusion-based, controllable video editing framework that systematically generates high-quality counterfactual videos by embedding structured contextual priors (e.g., event type, temporal location) into the editing process. This enables automated, scalable synthesis of paired video-QA data—original and edited videos with contrastive questions—forming the DualityVidQA dataset (144K samples). To leverage this contrastive structure, they propose DNA-Train, a two-stage training regime combining supervised fine-tuning and reinforcement learning with ℓ₁-normalized pairwise advantages, which stabilizes policy optimization and enforces visual grounding. Experiments show a 24.0% relative improvement on the DualityVidQA-Test benchmark and strong gains across general video understanding tasks, demonstrating that synthetic counterfactual data can effectively enhance MLLM robustness and generalization.
Dataset
-
The dataset, DualityVidQA, is built from two primary video sources: OpenVid and Pexels, contributing 61,591 and 36,333 clips respectively, for a total of 97,924 raw videos. These are used to create a diverse foundation for synthetic anomaly injection.
-
Visual anomalies are introduced at three levels—entire-frame, region, and object—using OpenCV and segmentation tools (Grounding DINO and SAM). Object-level anomalies target specific noun entities extracted from the video, with perturbations applied in temporally consistent segments.
-
Semantic anomalies include unexpected entity behavior (e.g., sudden appearance or disappearance) and visual distortions like blurred faces or unreadable text. These are inserted using the VACE video editing model to preserve the rest of the video content.
-
Common sense anomalies—such as violations of physical laws, causal inconsistencies, material abnormalities, and unnatural human movements—are generated via a two-step process: a multimodal LLM analyzes the video and generates an editing instruction, which is then executed using FLUX-Kontext. Frame interpolation with VACE creates the final edited video from original and edited frames.
-
The final dataset contains 135,168 anomaly-infused videos, which undergo quality screening before QA construction. The process required approximately 40,000 GPU hours on NVIDIA H20 GPUs.
-
For training, the authors use a two-stage framework: Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). The SFT stage generates 100K QA pairs from 25K real and 25K edited videos, using an 8:2 ratio of open-ended to multiple-choice questions. Dense captioning with red bounding boxes and video editing metadata guides caption generation, while GPT-5 and Gemini 2.5 Pro generate questions and answers, using 5,000 in-context references from LLaVA-Video to ensure consistency and diversity.
-
The RL stage constructs 20K counterfactual QA pairs, where the same question and answer options are used for both real and edited videos, but the correct answer differs. This forces the model to reason based on actual visual content. Gemini 2.5 Pro generates these pairs using video captions and identifies visual differences.
-
A high-quality test set, DualityVidQA-Test, consists of 600 real-counterfactual video pairs, each with a shared question and differing correct answers. It is curated through human and expert review to ensure clarity, validity, and answerability. The test set is categorized into four major types: counter-physical, object/scene deformation, causal reversal, and attribute change.
Method
The authors leverage a two-stage training framework, DNA-Train, to mitigate hallucinations in multimodal large language models (MLLMs) while preserving real-world performance. This framework is structured as a supervised fine-tuning (SFT) phase followed by a reinforcement learning (RL) phase, designed to explicitly penalize incorrect visual grounding and reward accurate reasoning. The overall architecture of DNA-Train is presented in the figure below, illustrating the transition from SFT to RL.

The first stage, SFT, initializes the model using the DualityVidQA dataset. This dataset is constructed through the DualityForge framework, which generates a comprehensive set of counterfactual videos by applying controlled edits to real-world source videos. The edits are guided by three hierarchical categories of anomalies: visual, semantic, and commonsense, each corresponding to a distinct video editing pipeline. The resulting counterfactual videos, alongside their original counterparts, form the basis for a dual dataset. In the second stage, the model undergoes reinforcement learning to refine its reasoning capabilities. This stage is built upon the DAPO framework, which is designed for stable optimization over long reasoning chains. The RL process samples a group of responses for both real and counterfactual videos, computes their rewards based on task correctness, and calculates the ℓ1 norm of intra-group advantages. The key innovation lies in the Duality Advantages Normalization strategy, which ensures balanced gradient updates by normalizing the advantages from each group to guarantee equal contribution to the gradient update.
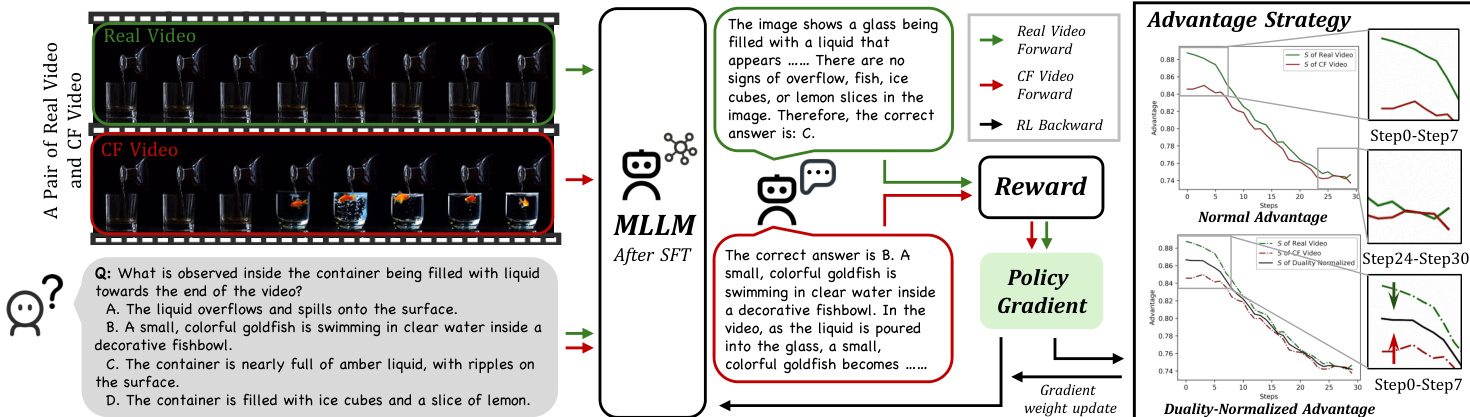
The reward signal for the RL stage is a dual-component design derived from the shared-question contrastive QA pairs. The first component is a correctness reward, a binary score assigned for selecting the single right answer, which forces the model to capture subtle visual information. This is supplemented by a format reward, which encourages adherence to a prescribed reasoning structure. The overall reward is formulated as R=rf+rc. The gradient of the DAPO objective is modulated by the advantage A^i,t, and the authors use the ℓ1 norm of advantages, S=∑iA^i, as a proxy for the total learning signal magnitude from a group of responses. This formulation reveals a critical property: the learning signal peaks for tasks of intermediate difficulty and diminishes as tasks become trivial or impossible. To counteract the systematic imbalance in learning signals between real and counterfactual data, the authors introduce Duality-Normalized Advantage, which normalizes the advantages from each group to guarantee equal contribution to the gradient update. This elegant re-weighting scheme (A^∗′=α∗A^∗) ensures a balanced learning signal across disparate data types, fostering robust and equitable optimization.
Experiment
- DualityVidQA introduces three video editing pipelines for generating counterfactual contexts: Visual Anomaly (pixel-level edits via OpenCV), Semantic Anomaly (object editing with mask generation and VACE-based editing), and Common Sense Anomaly (commonsense violation edits via FLUX-Kontext and VACE interpolation).
- Supervised Fine-Tuning (SFT) on DualityVidQA-SFT uses balanced sampling of real and counterfactual videos with cross-entropy loss to maintain performance on both domains.
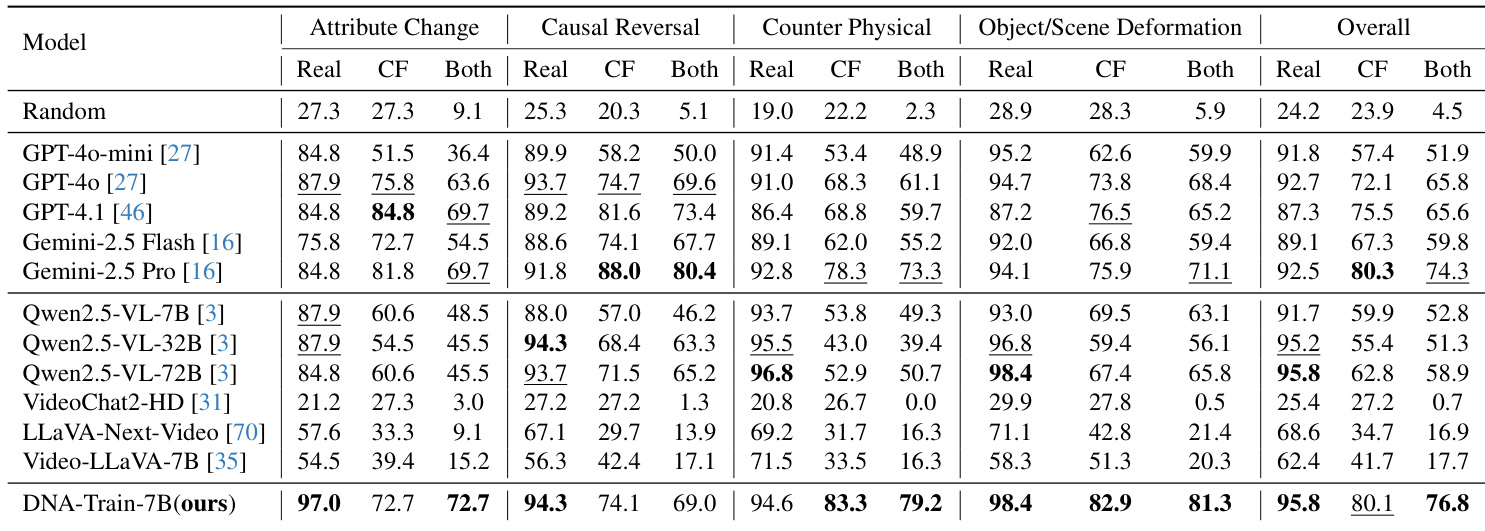
- On DualityVidVQA-Test, DNA-Train-7B achieves 76.8% accuracy, outperforming other open-source models and demonstrating state-of-the-art hallucination detection, while maintaining strong general video understanding.
- DNA-Train-7B surpasses GPT-4o on MVBench and TVBench, and achieves 79.2% on the challenging Counter Physical category, showing superior resilience to counterfactual edits.
- Ablation studies confirm that paired real-counterfactual data is essential, improving DualityVid-Test performance to 70.6 and boosting general benchmarks by +1.8 on average.
- DNA-Train outperforms GRPO and DAPO baselines by 10.8 average points on hallucination detection and improves all general benchmarks.
- Gains are consistent across model scales, with the 7B variant showing a 25.9-point improvement on hallucination detection, and the method is effective on multiple architectures, including LLaVA-Next-Video.
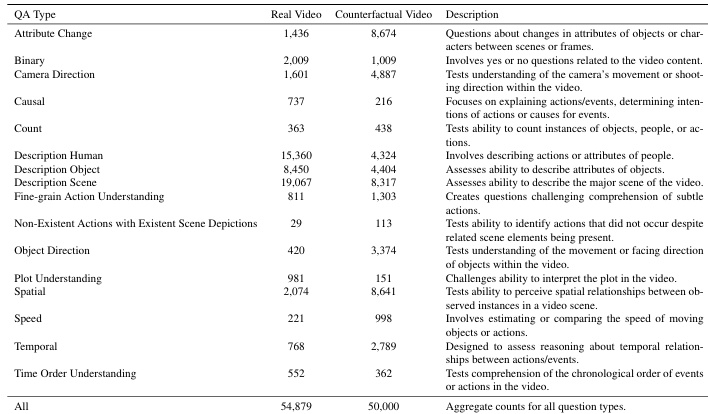
The authors use the table to summarize the distribution of question types across real and counterfactual videos in their DualityVidQA dataset, showing that counterfactual videos contain a higher number of questions related to attribute changes, binary reasoning, and camera direction, while real videos are more focused on object and action descriptions. Results show that the model's performance drops significantly on counterfactual videos, particularly in categories involving causal reasoning and fine-grained actions, highlighting a key challenge in robust video understanding.
The authors use a supervised fine-tuning and reinforcement learning approach to train models on both real and counterfactual videos, aiming to improve hallucination detection without sacrificing general video understanding. Results show that the DNA-Train-7B model achieves state-of-the-art performance on hallucination detection benchmarks while maintaining strong results on general video understanding tasks, outperforming both open-source and closed-source models.
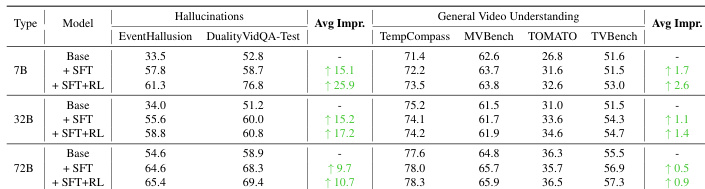
Results show that the DNA-Train-7B model achieves state-of-the-art performance on the DualityVidQA-Test benchmark, with an overall accuracy of 76.8%, significantly outperforming other open-source models and demonstrating strong resilience on counterfactual video understanding tasks. The model also maintains competitive performance on general video understanding benchmarks, improving upon its base model across all tasks while showing robustness across different model architectures and scales.
Results show that the paired data setting achieves the highest performance on both hallucination detection and general video understanding benchmarks, outperforming both real and counterfactual data alone. The model trained with paired data demonstrates a significant improvement in average improvement across all tasks, indicating the effectiveness of combining real and counterfactual data for balanced learning.

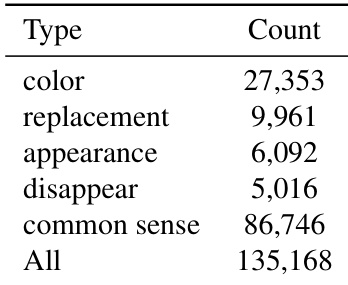
The authors use the table to summarize the distribution of different types of counterfactual video edits in their dataset. The data shows that common sense anomalies are the most frequent category, with 86,746 instances, while appearance and disappearance edits are the least common, with 6,092 and 5,016 instances respectively. The total count of 135,168 indicates a large-scale dataset designed to evaluate model robustness across diverse types of video manipulations.