Command Palette
Search for a command to run...
Recursive Language Models
Recursive Language Models
Alex L. Zhang Tim Kraska Omar Khattab
Abstract
We study allowing large language models (LLMs) to process arbitrarily long prompts through the lens of inference-time scaling. We propose Recursive Language Models (RLMs), a general inference strategy that treats long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt. We find that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs and common long-context scaffolds across four diverse long-context tasks, while having comparable (or cheaper) cost per query.
One-sentence Summary
The authors from MIT CSAIL propose Recursive Language Models (RLMs), a novel inference strategy enabling LLMs to process arbitrarily long prompts by recursively decomposing and querying them, significantly extending effective context beyond model limits while improving performance and cost-efficiency across long-context tasks.
Key Contributions
- The paper addresses the critical limitation of fixed context windows in large language models (LLMs), which leads to performance degradation—known as context rot—when processing long prompts, especially for complex tasks requiring dense access to input content.
- It introduces Recursive Language Models (RLMs), a general inference strategy that treats long prompts as programmable objects within an external environment, enabling the LLM to recursively decompose and process them through self-invocation via code generation, thereby bypassing the model’s native context limits.
- Evaluated on four diverse long-context tasks—including deep research, information aggregation, and synthetic reasoning—RLMs outperform base LLMs, context compaction, retrieval agents, and code-generation agents, maintaining strong performance even at inputs exceeding 10 million tokens while incurring comparable or lower computational cost.
Introduction
Modern language models face a critical bottleneck in handling long-context tasks due to limited context windows and context rot, where performance degrades as input length increases—even for state-of-the-art models like GPT-5. This limitation hinders their use in real-world applications requiring deep reasoning over massive inputs, such as analyzing large codebases or processing extensive research documents. Prior approaches to scaling context, such as context compaction or retrieval-based agents, often sacrifice fine-grained information or fail to scale beyond the model’s native context window. The authors introduce Recursive Language Models (RLMs), a general-purpose inference paradigm that treats the input prompt as a variable within a persistent Python REPL environment. By enabling the LLM to programmatically decompose, query, and recursively invoke itself on chunks of the input, RLMs effectively bypass context limits without relying on external tools or task-specific designs. This approach allows the model to maintain high performance across inputs exceeding 10 million tokens, outperforming direct LLM calls, compaction methods, and retrieval agents by significant margins while keeping computational costs comparable.
Dataset

- The dataset consists of 3,182 general-knowledge questions, one per line, sourced from a structured text context with metadata including date, user ID, and instance (question).
- Each line contains a question paired with a user ID and timestamp, forming a longitudinal record of user-generated queries.
- The dataset is used to evaluate reasoning capabilities across diverse semantic categories: description and abstract concept, entity, human being, numeric value, location, and abbreviation.
- The authors generate synthetic tasks (OOLONG-Pairs) by creating 20 new benchmark questions based on the original data, targeting pair-wise semantic relationships across user entries.
- Tasks require identifying user ID pairs that satisfy specific combinations of semantic labels and temporal constraints (e.g., instances must occur before or after certain dates).
- All pairs are listed in ascending order (lower ID first), with no duplicates, and answers must be formatted as (user_id_1, user_id_2) on separate lines.
- The dataset is processed to extract and validate semantic labels from question content, with no explicit labels provided—these must be inferred from context.
- The model uses the full dataset in a training and evaluation pipeline, leveraging recursive sub-calls to classify entries and aggregate over pairs, with a focus on scalability and correctness across input lengths from 1,024 to over 1 million tokens.
- A key processing strategy involves filtering entries by semantic category and temporal criteria, ensuring that aggregation tasks cannot be solved via linear pass methods, thus enforcing true pairwise reasoning.
Method
The authors introduce Recursive Language Models (RLMs), a general inference framework that enables large language models (LLMs) to process arbitrarily long prompts by treating the input as an external environment. The core architecture operates through a hierarchical, recursive structure where a root LLM orchestrates the processing of long inputs by making sub-queries to itself or other LLMs. This process is facilitated by a Python REPL (Read-Eval-Print Loop) environment, which serves as a shared memory space where the LLM can store, manipulate, and retrieve information. The root LLM, designated as RLM (root / depth=0), receives the full prompt and loads it as a variable in the environment. It then decomposes the prompt into manageable chunks, probes the context using code-based operations such as regex queries or keyword searches, and recursively calls sub-LM instances (RLM (depth=1)) to analyze specific segments. Each sub-LM operates independently, executing code in the REPL environment to extract relevant information, which is then returned to the root LLM as a sub-response. The root LLM aggregates these responses, performs further reasoning, and may initiate additional recursive calls to verify or refine its understanding. This iterative process continues until the root LLM determines that sufficient information has been gathered to form a final answer. The framework emphasizes the use of code to interact with the context, allowing the LLM to perform structured operations like summarization, filtering, and data extraction, rather than relying solely on token-based reasoning. The system prompt instructs the LLM to use the REPL environment extensively, encouraging the use of print() statements to inspect intermediate results and llm_query() calls to delegate subtasks. The final answer is explicitly provided using a FINAL or FINAL_VAR function, ensuring that the output is clearly distinguished from intermediate code execution. This design enables the LLM to handle inputs far beyond its native context window by offloading the context and leveraging recursive, programmatically guided reasoning.

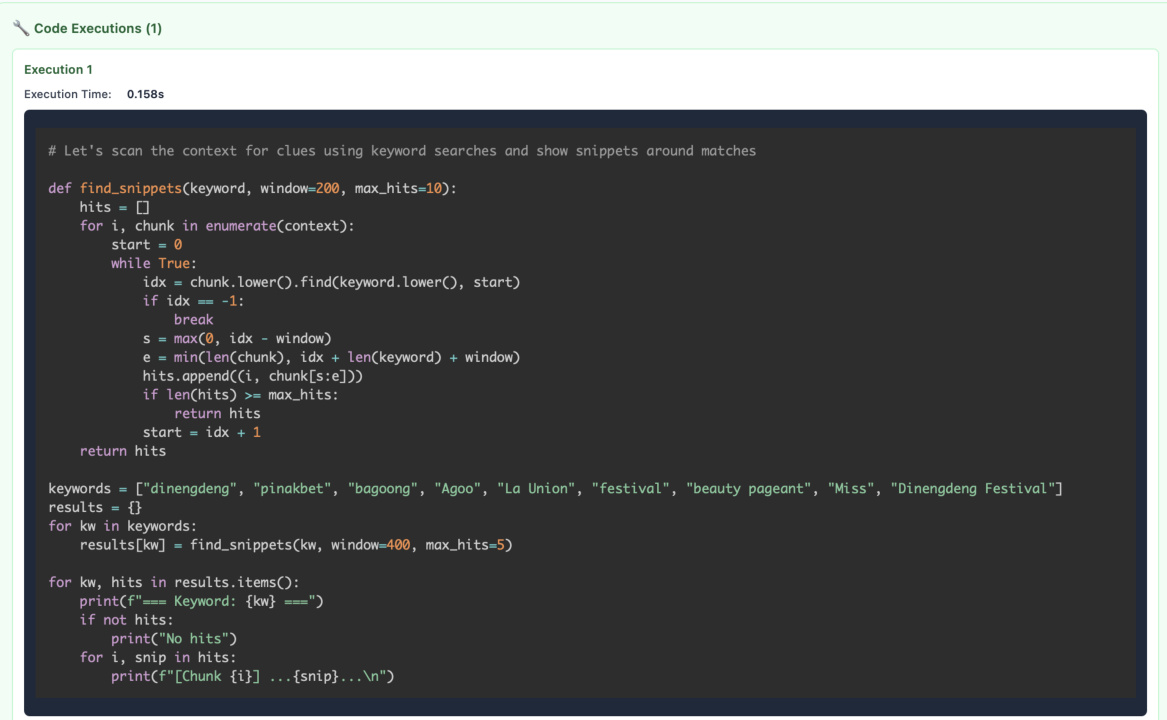
The RLM framework allows the model to interact with, probe, and filter the context using code, based on model priors and reasoning. As shown in the figure below, the root LLM can execute code in the REPL environment to split the prompt, search for specific keywords, and make sub-LM calls to analyze relevant sections. This enables the model to perform complex operations such as identifying relevant chunks, summarizing information, and extracting structured data. The model can also use the REPL environment to maintain state across multiple steps, storing intermediate results in variables and using them in subsequent queries. This capability is particularly useful for tasks that require multi-hop reasoning or the integration of information from disparate parts of the input. The framework supports both iterative and batched processing, allowing the model to efficiently handle large inputs by breaking them into smaller, manageable pieces. The use of code-based operations ensures that the model can perform precise and controlled actions, reducing the risk of errors that might arise from purely token-based reasoning.

RLMs defer reasoning over their large context by querying recursive LM calls. The model can process the context in batches, using code to classify questions, extract relevant information, and perform other operations. For example, the model might first classify questions into categories such as 'numeric value', 'entity', 'location', etc., and then process each category separately. This approach allows the model to handle complex tasks that require both information retrieval and reasoning. The model can also use the REPL environment to verify its answers, ensuring that the final output is accurate and consistent. The framework supports a wide range of operations, including data extraction, summarization, and classification, making it a versatile tool for long-context tasks.
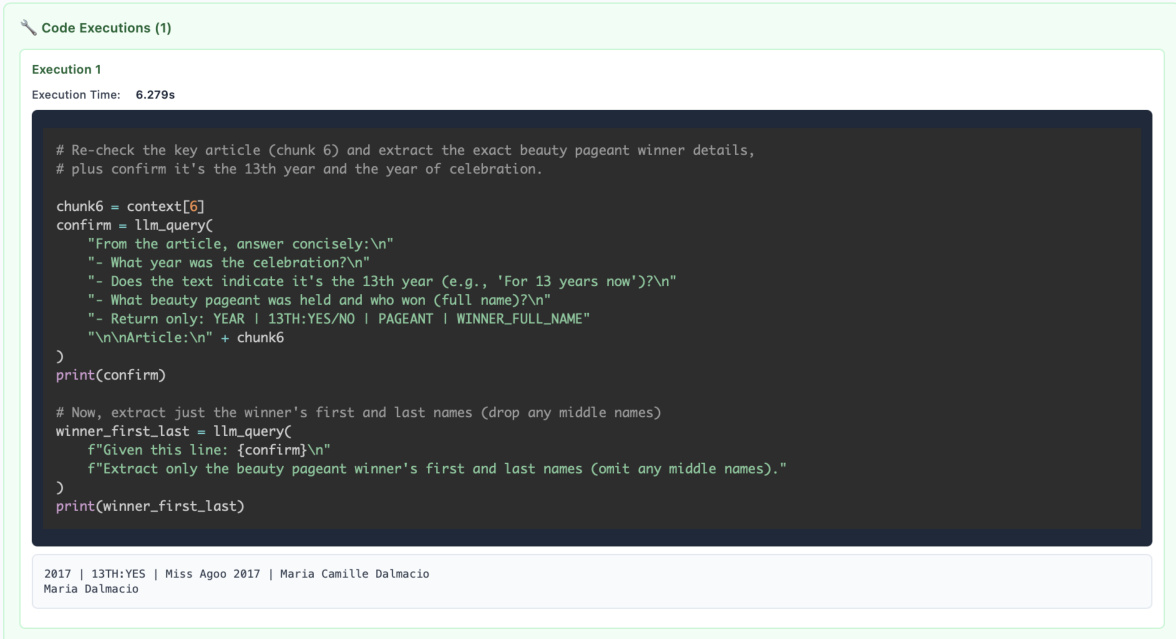
RLMs can stitch recursive LM outputs to form longer, composite outputs. The model can use the REPL environment to store intermediate results and combine them into a final answer. For example, the model might extract pairs of user IDs that satisfy certain conditions and store them in a variable. It can then use this variable to generate the final output, ensuring that the answer is complete and accurate. The model can also use the REPL environment to verify its answers, ensuring that the final output is consistent with the input data. This capability is particularly useful for tasks that require the integration of information from multiple sources, such as identifying pairs of users with specific properties. The framework supports a wide range of operations, including data extraction, summarization, and classification, making it a versatile tool for long-context tasks.
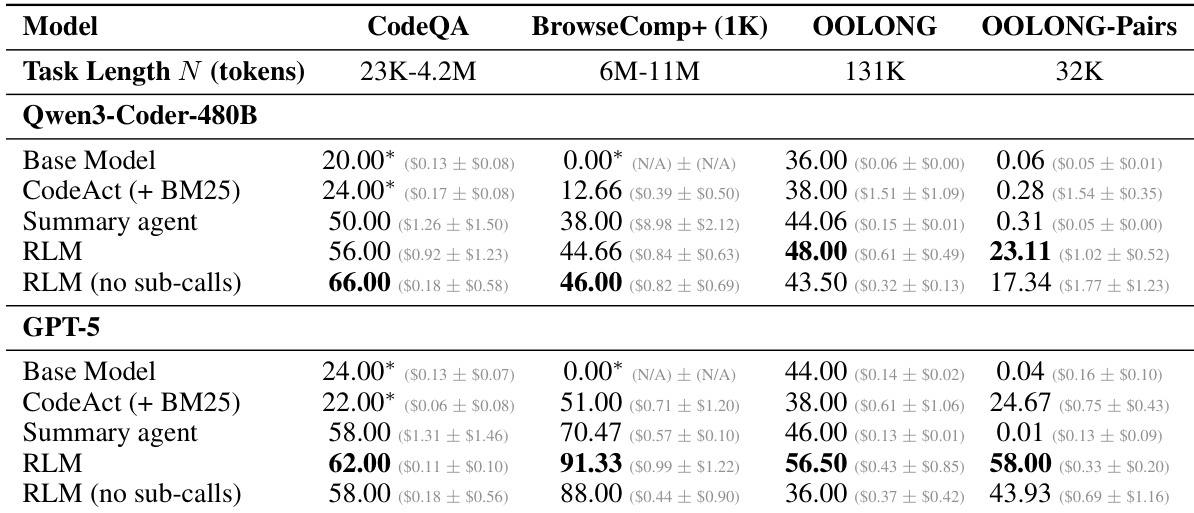
Experiment
- S-NIAH: Validates constant processing cost with input length; RLMs maintain high performance despite large inputs, outperforming base models and baselines.
- BrowseComp-Plus (1K documents): Tests multi-hop reasoning over large document sets; RLM(GPT-5) achieves perfect performance at 1000 documents, outperforming base models and summarization/retrieval baselines by over 29% with lower average cost (0.99vs.1.50–$2.75 for GPT-5-mini).
- OOLONG: Evaluates linear scaling with input length; RLMs with GPT-5 and Qwen3-Coder outperform base models by 28.4% and 33.3% respectively.
- OOLONG-Pairs: Tests quadratic scaling with input length; RLMs achieve F1 scores of 58.00% (GPT-5) and 23.11% (Qwen3-Coder), vastly surpassing base models (<0.1%).
- LongBench-v2 CodeQA: Assesses codebase understanding; RLMs achieve high accuracy on multi-choice tasks, demonstrating strong reasoning over fixed code files.
- RLMs scale effectively to 10M+ tokens, outperforming base models and task-agnostic agents by up to 2× in accuracy while maintaining comparable or lower costs.
- The REPL environment enables scaling beyond context limits, and recursive sub-calling is critical for information-dense tasks, improving performance by 10%–59% over ablations.
- RLM performance degrades slowly with input length and complexity, while base models degrade rapidly—RLMs consistently outperform base models beyond 2^14 tokens.
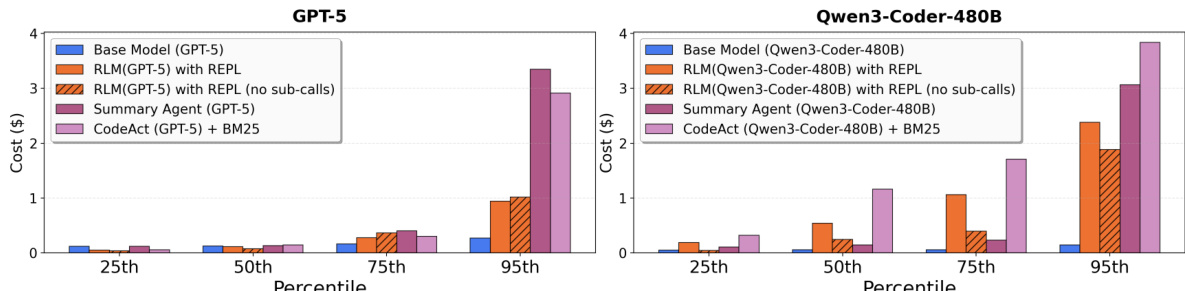
- RLM inference costs are comparable to base models at median but exhibit high variance due to variable trajectory lengths; however, RLMs are up to 3× cheaper than summarization baselines.
- RLMs are model-agnostic but show different behaviors: GPT-5 excels on BrowseComp-Plus, while Qwen3-Coder struggles, despite identical system prompts.
- Emergent patterns include context filtering via code execution, recursive chunking, answer verification via sub-calls, and variable-based output stitching for long outputs.
- RLMs with asynchronous calls and deeper recursion are future directions to reduce cost and improve efficiency.
The authors use a Python REPL environment to implement RLMs, which allows them to scale beyond the context limits of base models. Results show that RLMs achieve higher performance than base models and other baselines on long-context tasks, with costs that remain comparable or lower, particularly on information-dense tasks like OOLONG-Pairs where they outperform non-recursive variants by significant margins.
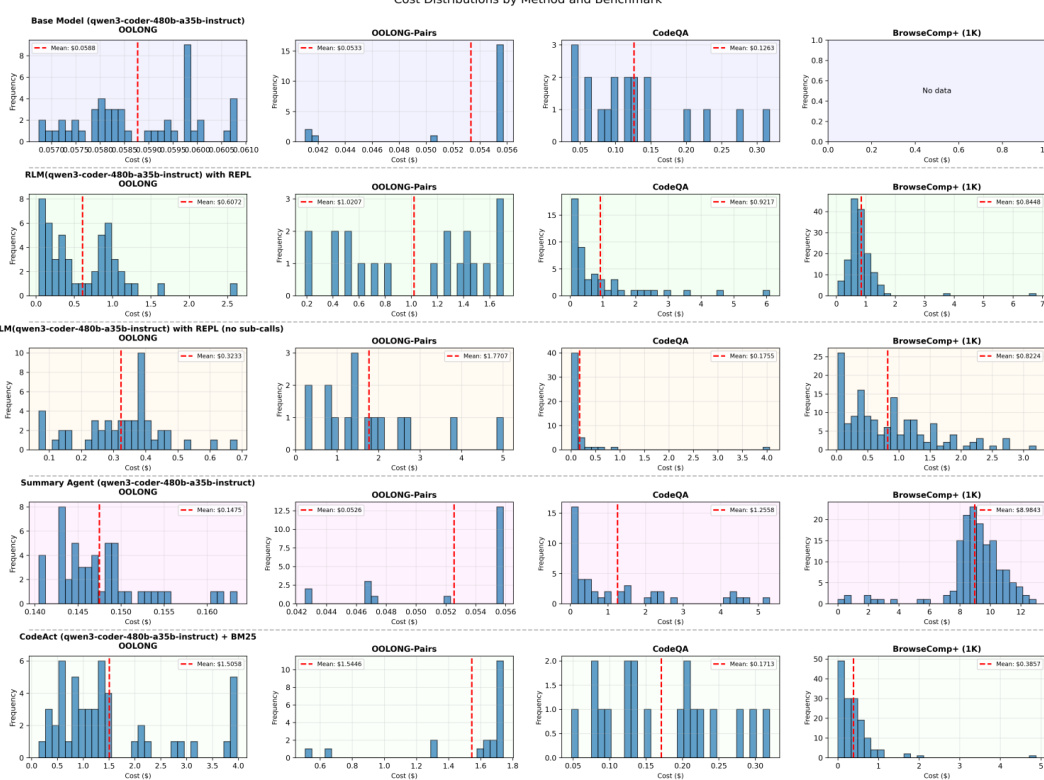
Results show that RLMs with REPL outperform base models and other baselines on long-context tasks, achieving higher performance with comparable or lower costs, particularly on information-dense tasks like OOLONG-Pairs. The RLM approach scales effectively with input size, maintaining strong performance even when base models fail due to context limits, while the cost of RLMs remains within the same order of magnitude as base model calls.
The authors use a table to compare the performance and cost of different methods on long-context tasks, including CodeQA, BrowseComp+, OOLONG, and OOLONG-Pairs. Results show that RLMs outperform base models and other baselines on tasks with large input lengths, achieving higher accuracy while maintaining comparable or lower costs, particularly on information-dense tasks like OOLONG-Pairs where RLMs achieve significantly higher F1 scores than base models.