Command Palette
Search for a command to run...
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Abstract
We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
One-sentence Summary
The authors propose Youtu-LLM, a 1.96B-parameter lightweight language model developed by the Youtu-LLM Team, which achieves state-of-the-art performance on sub-2B models by pre-training from scratch with a principled "Commonsense-STEM-Agent" curriculum. The model integrates a compact Multi-Latent Attention architecture with a STEM-oriented tokenizer and a scalable pipeline for generating high-quality agentic trajectory data across math, coding, deep research, and tool-use domains. This enables the model to internalize native planning, reflection, and action capabilities, significantly outperforming larger models on agent benchmarks while maintaining strong general reasoning and long-context abilities.
Key Contributions
-
We introduce Youtu-LLM, a 2B-parameter lightweight open-source language model that achieves state-of-the-art performance on agentic benchmarks, outperforming larger models and demonstrating that compact LLMs can possess strong native agentic capabilities.
-
We propose a novel agentic pre-training paradigm centered on structured reasoning trajectories, using a refined Agentic-CoT framework that decomposes reasoning into distinct phases—analysis, planning, action, reflection, and summary—enabling systematic cultivation of planning, tool use, and self-correction abilities.
-
We develop scalable data construction frameworks to generate over 200B tokens of high-quality agentic trajectory data across domains like coding, mathematics, and research, providing empirical evidence that early-stage, agent-oriented pre-training enables scalable growth of agentic capabilities in small models.
Introduction
The authors leverage the growing demand for lightweight yet capable language models in real-world agentic applications—such as coding, deep research, and tool-augmented workflows—where computational efficiency and low latency are critical. Prior work on small models has relied heavily on post-training techniques like distillation or instruction tuning, which primarily align output behavior without systematically cultivating core cognitive abilities such as planning, reflection, and structured reasoning. This results in models that lack robustness, generalization, and true agentic competence. To address this, the authors introduce Youtu-LLM, a 2B-parameter open-source model that achieves state-of-the-art performance in both general and agentic benchmarks by embedding agent-oriented signals directly during pre-training. Their key contribution is a principled agentic pre-training framework that integrates scalable data construction for high-quality trajectories across reasoning, math, deep research, and tool use, enabling native agentic capabilities without post-augmentation.
Dataset
-
The dataset for Youtu-LLM’s pre-training consists of two main components: general pre-training data (over 95% of the corpus) and agentic trajectory data, with the former emphasizing broad quality and composition control and the latter focusing on high-quality, verifiable agent execution sequences.
-
General pre-training data starts with over 10T raw tokens from diverse sources, primarily English with secondary focus on Chinese. After deduplication, filtering, and decontamination, 8.7T tokens remain. This is expanded to 10.64T tokens through targeted up-sampling of high-quality STEM and code content, including 700B tokens of STEM corpora and 1,400B of code data, plus 500B synthesized materials like explanations, summaries, and code documentation.
-
The corpus is filtered using a multi-stage process: data is classified using 11 domain categories (46 sub-domains) and evaluated against 10 quality criteria. A semi-automated pipeline uses Deepseek-R1 for initial labeling, validated via manual review with over 95% consistency. A final quality model based on Qwen3-1.7B achieves over 95% accuracy in domain and quality scoring, enabling selection of data with average scores above 8.5.
-
Deduplication is performed using MinHash-LSH within length bins, complemented by heuristic rules such as 13-gram detection, toxicity scoring, and code keyword filtering. Aho-Corasick algorithm is used to decontaminate STEM and code corpora, preventing test set leakage.
-
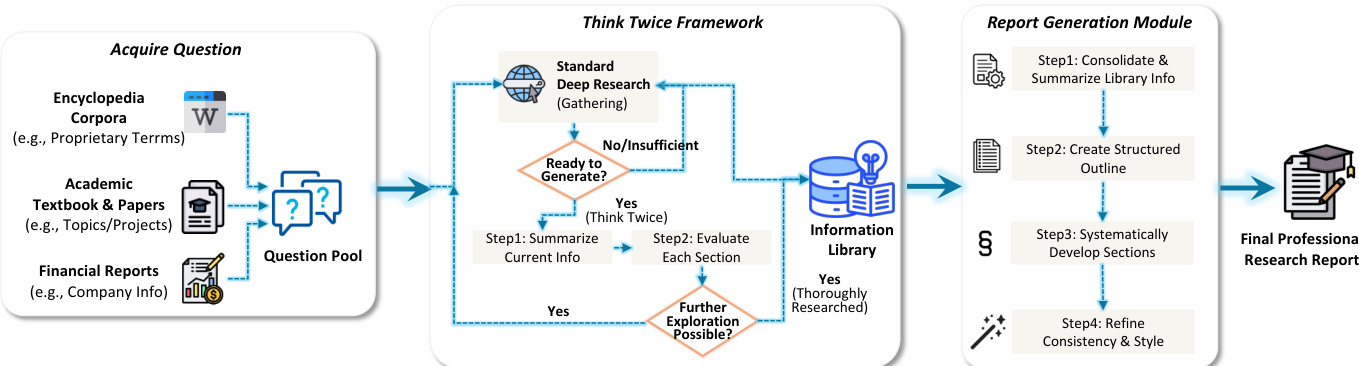
Agentic trajectory data totals 200B tokens, broken down into: 25B Agentic-CoT trajectories, 20B mathematical trajectories, 70B code execution trajectories, 60B Deep Research trajectories, and 25B other trajectories (e.g., tool use, function calling, planning).
-
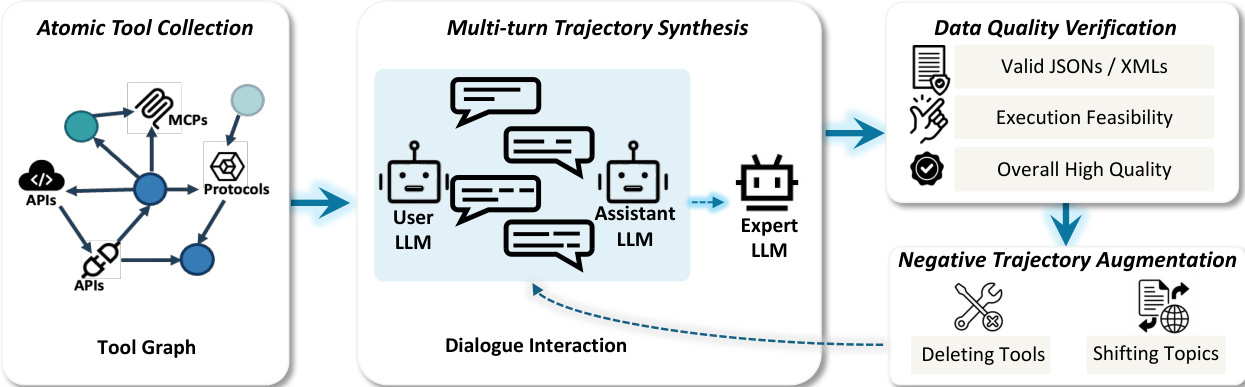
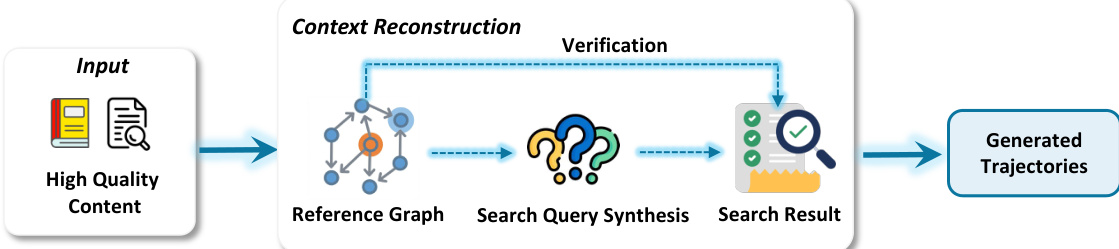
Code trajectory data is built in two parts: atomic code capabilities (e.g., proactive exploration, context-aware generation, patch editing, testing, environment comprehension, self-reflection) and end-to-end agent trajectories. The latter is scaled via three strategies: (1) diverse task environments using SWE-gym, SWE-smith, and SWE-rebench with synthetic instances; (2) scalable static evaluation tasks on repositories without executable images; (3) trajectory branching at critical actions (editing and testing), with successful paths expanded and failed paths truncated after one branch to prevent error propagation.
-
The trajectory synthesis pipeline uses a branching strategy that generates variations at successful critical steps and a single branch at the first failure point, followed by evaluation to ensure validity and prevent overfitting.
-
For instruction-tuning, data is collected from 10 categories: mathematics, code, scientific reasoning, agentic workflows, general knowledge QA, instruction following, role-playing, creative writing, multi-turn dialogue, and safety alignment. High-quality reasoning answers are constructed using advanced LLMs, either by generating full CoT reasoning for open-ended queries or reconstructing logical paths for existing answers.
-
A multi-stage cleaning pipeline removes low-quality samples via heuristic filters (e.g., truncation, repetition, mixed language) and uses teacher models to score logical coherence, fluency, and factual accuracy. Decontamination is performed using 32-gram exact matching to eliminate overlap with evaluation benchmarks.
-
Task-specific validation is applied: mathematical data uses structured output formats (e.g., \boxed{} notation) and is deduplicated via embedding similarity; code data is validated through execution environments and input/output mapping; complex instructions use rubrics and LLM-as-a-judge scoring; safety data includes adversarial red-teaming and training for informative refusal.
-
Global validation strategies include: preserving thinking format markers (e.g., , , , ), enforcing language consistency via pre-labeled targets, and detecting repetition using a confidence-based n-gram frequency metric to penalize cyclic outputs and promote diversity.
Method
The authors leverage a multi-stage training framework to develop Youtu-LLM, a 1.96B parameter language model designed to achieve strong agentic capabilities while maintaining high computational efficiency. The overall architecture is built upon a dense Multi-Latent Attention (MLA) design, which is optimized for on-device deployment and long-context reasoning. This framework is complemented by a custom STEM-oriented tokenizer and a principled curriculum that progresses from general commonsense to complex STEM and agentic tasks.
The model's core architecture is based on a dense Multi-Latent Attention (MLA) mechanism, which is designed to enhance the expressiveness of the attention layer without increasing the model's parameter count. This is achieved through low-rank compression of the key-value (KV) cache and the use of larger intermediate projection matrices. The MLA configuration is consistent with that of DeepSeek-V3, featuring a KV LoRA rank dimension of 512, a Q LoRA rank dimension of 1,536, a QK nope head dimension of 128, a QK RoPE head dimension of 64, and a V head dimension of 128. This design allows Youtu-LLM to achieve superior inference performance compared to vanilla GQA, particularly in long-context scenarios. The model's total parameter count is 1.96B, with a vocabulary size of 128,256, which is consistent with the Llama3 series. The model's architecture is further optimized for long-context reasoning, supporting a 128k context window, which enables robust state tracking and long-horizon planning.
The tokenizer design is a critical component of Youtu-LLM's performance, employing a multi-stage training strategy to achieve a balance between general language ability and domain-specific reasoning capacity. The tokenizer is a byte-level BPE (BBPE) tokenizer trained using a modified HuggingFace Tokenizers pipeline. It incorporates a stricter pre-tokenization scheme that segments Chinese characters, Japanese kana, Hangul letters, and CJK punctuation into standalone units, preventing them from merging with other text parts. For English, the pre-tokenization follows the design used in GPT-4o, allowing specific punctuation and capitalization patterns to be followed by lowercase sequences. Numeric tokenization is handled by retaining only the ten atomic digit tokens (0–9), avoiding multi-digit tokens. The base vocabulary is derived from the o200k vocabulary, with Chinese tokens and invalid tokens removed, resulting in a 101k token base. This base is then expanded with Chinese-specific tokens, and further augmented with specialized tokens for code and mathematical/technical content, resulting in a final vocabulary size of 128,256. This multi-stage approach ensures that the tokenizer is optimized for both general and reasoning-oriented data, achieving a 5% improvement in tokenization efficiency on general data and up to 10% on reasoning data compared to baselines.
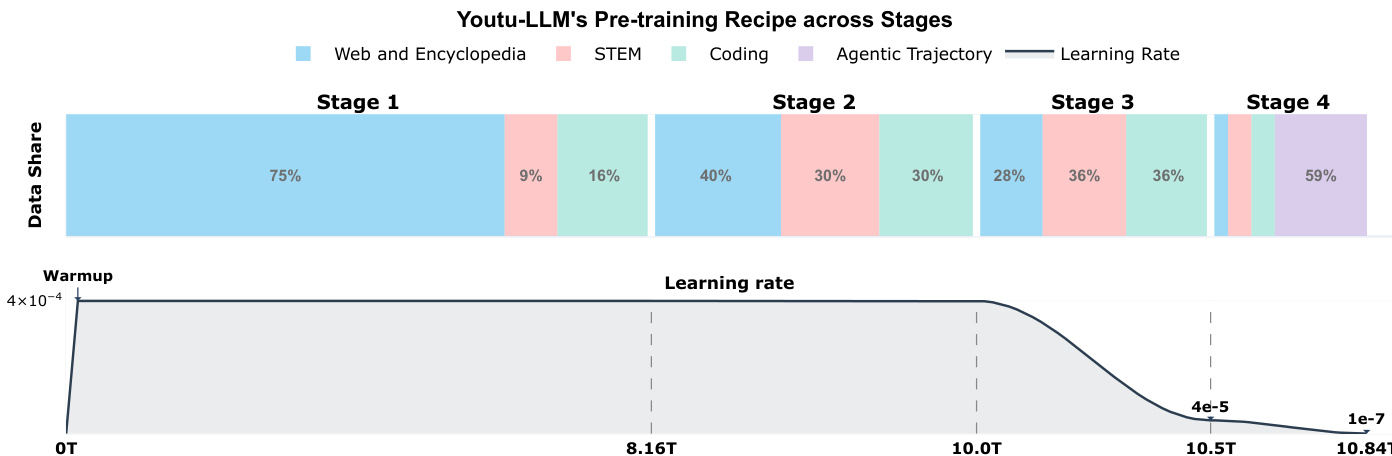
The pre-training of Youtu-LLM follows a multi-stage curriculum that progressively shifts the data distribution from general commonsense to complex STEM and agentic tasks. This principled approach ensures the model acquires deep cognitive abilities rather than superficial alignment. The training corpus consists of approximately 11T tokens, and the model is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The training process is designed to first "cold-start" the model's reasoning engines and then refine its general versatility. This is achieved through a two-stage Supervised Fine-Tuning (SFT) strategy. In Stage I, the model is fine-tuned on a logic-dense dataset composed of Mathematics (40%), Programming Code (30%), Scientific Reasoning (20%), and Agentic Tasks (10%), which forces the model to learn step-by-step deduction and structured response capabilities. In Stage II, the training corpus is expanded to include a diverse range of general user instructions, while integrating the Stage I subsets to mitigate catastrophic forgetting. This stage also introduces a dual-mode capability, enabling the model to switch between a "thinking" mode (generating explicit thought processes) and a "non-thinking" mode (direct answering) by conditioning on specific control tokens.
The model's agentic capabilities are further enhanced through a scalable agentic mid-training process. This involves synthesizing diverse and varied trajectories across math, coding, and tool-use domains using data construction schemes that generate rich and complex problem-solving paths. The training data is designed to simulate real-world software issues, including fault localization, refactoring, and procedural modification, which are used to generate diverse task instances. The model is trained to perform atomic task decomposition, feedback-enhancement planning, and action execution, with a feedback loop that includes a reflection generator and an evaluator. This process enables the model to internalize planning and reflection behaviors effectively, allowing it to conduct a full agentic loop involving analysis, planning, feedback, and action, rather than mere step-by-step computation. The model's ability to handle complex, multi-step tasks is demonstrated through its performance on agent-specific benchmarks, where it significantly surpasses existing SOTA baselines.
Experiment
- Multi-stage pre-training validates the effectiveness of the "Commonsense-STEM-Agent" design principle, with staged data progression (commonsense → STEM/coding → long-context → agentic trajectories) leading to improved model capabilities. Training on 10.84T tokens with 2B parameters achieved optimal stability using a 12M global batch size and 4e-4 initial learning rate, with agentic mid-training (Stage 4) yielding significant performance gains.
- Training dynamics analysis confirms FP16 precision maintains better training-inference consistency than BF16, reducing numerical drift and enabling sustained performance gains on mathematical and coding benchmarks. Consistent sampling with a KL divergence threshold (τ = 0.01) improves training stability by filtering high-drift prompts.
- Youtu-LLM 2B Base outperforms similarly sized baselines on general benchmarks: achieves 78.4% on MMLU-Pro, 82.1% on MATH, 85.3% on BBH, and 76.2% on LongBench v2, surpassing models like Qwen3-1.7B and SmolLM3-3B, and approaching Qwen3-4B performance.
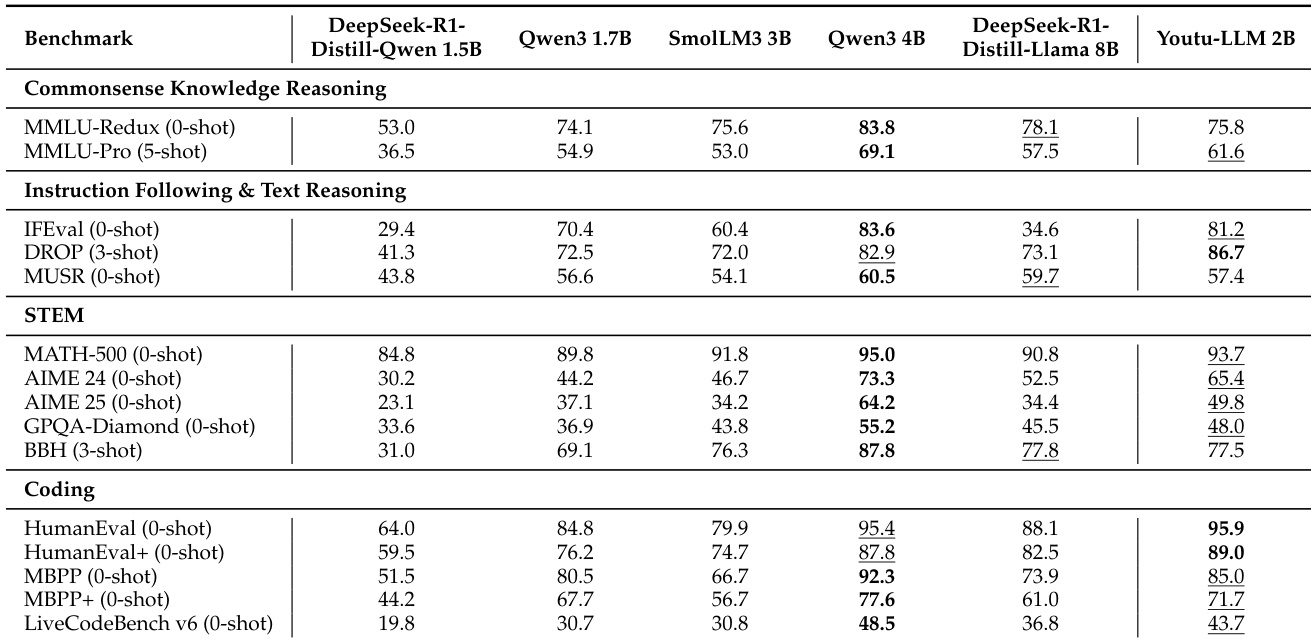
- Youtu-LLM 2B Instruct model exceeds similar-sized models (e.g., Qwen3-1.7B, SmolLM3-3B) and even outperforms the larger DeepSeek-R1-Distill-Llama 8B on instruction following, coding (HumanEval pass@1: 72.1%), and text reasoning (DROP F1: 78.3%), demonstrating strong efficiency in lightweight LLM design.
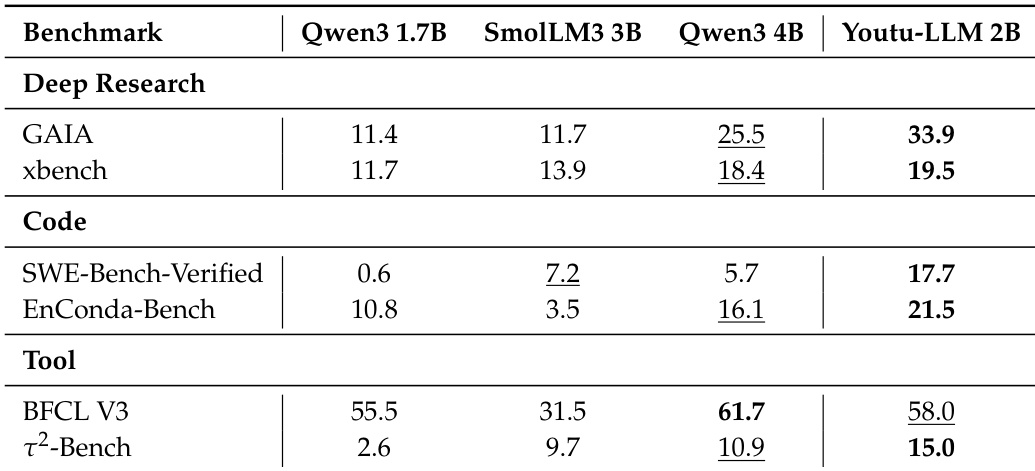
- Agentic mid-training significantly enhances agent capabilities: Youtu-LLM 2B Base achieves APTBench scores close to Qwen3-4B Base (AVG: 38.6% vs. 40.5%), with 14.4% average improvement across six agent benchmarks. Agentic mid-training (AMT) boosts SWE-Bench-Verified resolve rate by 42.7% at pass@1.
- Ablation studies confirm the value of trajectory data: Agentic-CoT data improves planning by 17.8% (65.1% → 82.9%), math trajectory data scaling shows performance saturation beyond 3× upsampling, and deep research trajectory data enables strong synergy with other data, narrowing the gap to Qwen3-4B-Base.
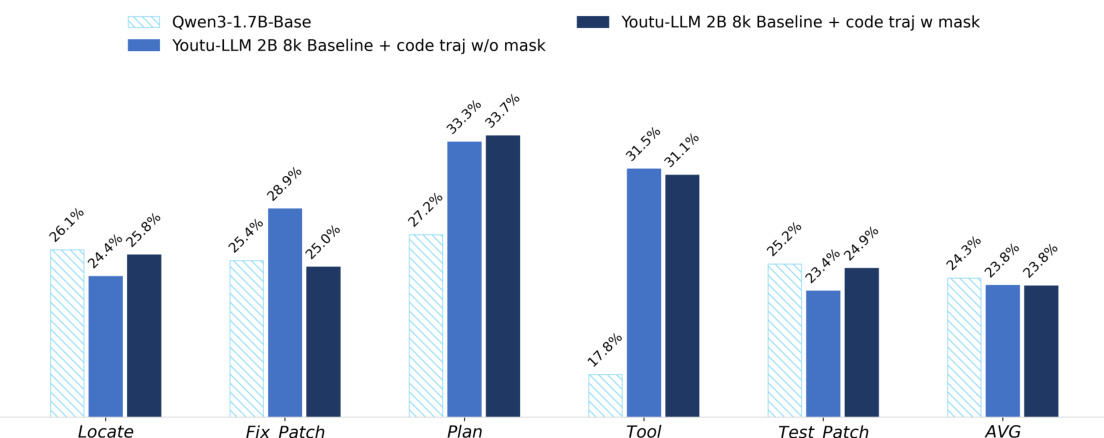
- Masking non-assistant turns in trajectory data (e.g., system prompts, tool outputs) consistently improves reasoning and action performance, especially in deep research and math tasks, by reducing noise and focusing learning on internal reasoning traces.
The authors use a multi-stage pre-training approach to develop Youtu-LLM 2B Base, focusing on progressively enhancing capabilities in commonsense, STEM, coding, and long-context reasoning. Results show that Youtu-LLM 2B Base significantly outperforms similarly sized base models across all evaluated dimensions, achieving competitive results with larger models like Qwen3-4B Base, particularly in coding and long-context tasks.
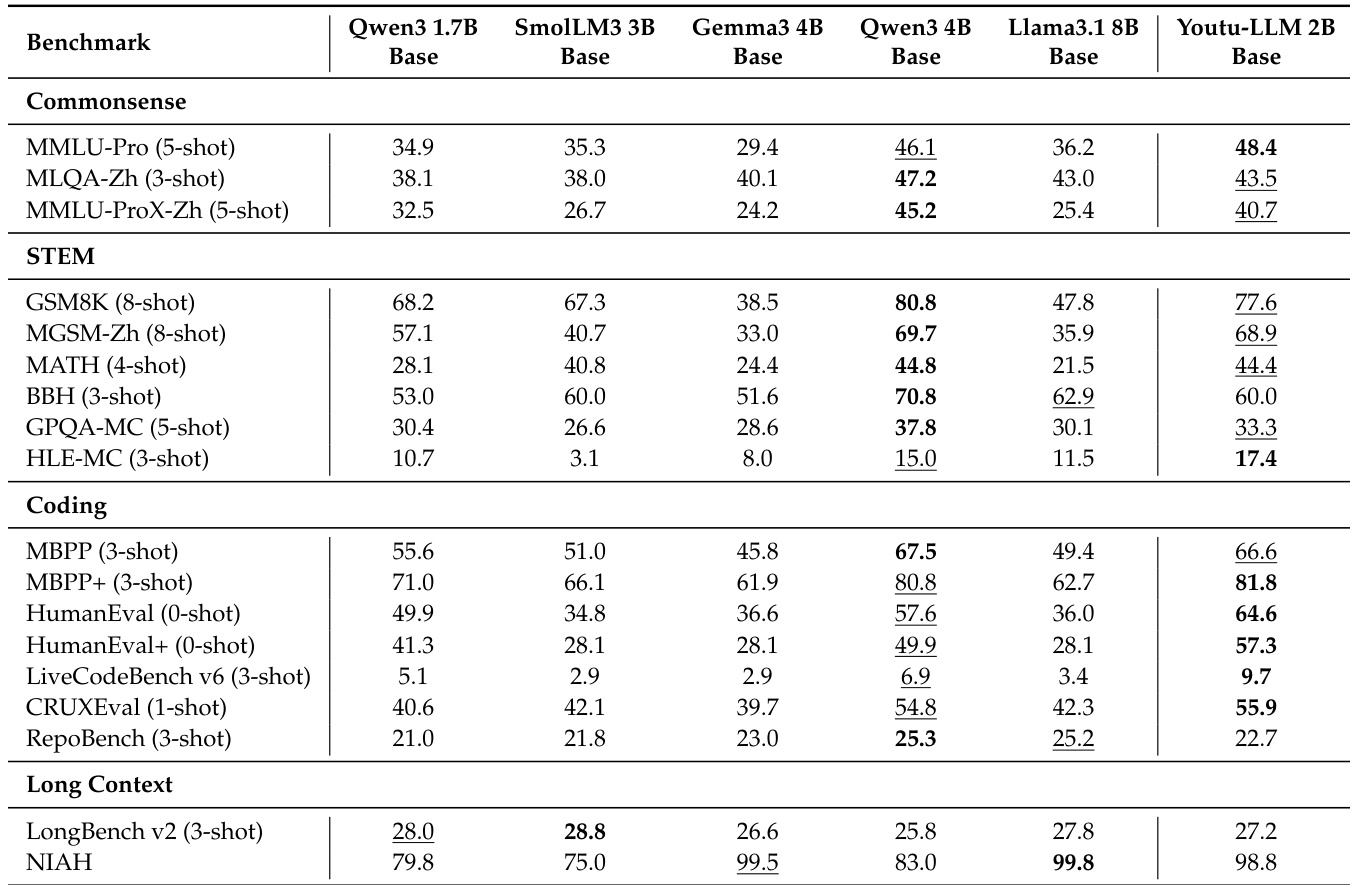
The authors use a multi-stage pre-training approach to develop Youtu-LLM 2B, focusing on progressively enhancing capabilities in commonsense reasoning, STEM, coding, and long-context understanding. Results show that the Youtu-LLM 2B model achieves competitive performance against larger models, particularly excelling in instruction following, text reasoning, and coding benchmarks, where it outperforms similarly sized models and approaches the performance of larger models like Qwen3-4B.
The authors evaluate the Youtu-LLM 2B instruct model against several similarly sized and larger models on agent benchmarks, including Deep Research, Code, and Tool tasks. Results show that Youtu-LLM 2B outperforms all smaller models and achieves competitive results with larger models, particularly excelling in tool-use and coding capabilities.
The authors compare the impact of masking non-assistant content during code trajectory training on the Youtu-LLM 2B model. Results show that masking improves performance across most metrics, with the highest gains in Planning (33.3% vs. 33.7%) and Tool (31.5% vs. 31.1%). The average score increases from 23.8% to 24.9% when masking is applied, indicating that focusing training on the model's reasoning and action components enhances overall agentic coding capabilities.
The authors use a multi-stage pre-training approach for Youtu-LLM 2B, incorporating data from commonsense, STEM, coding, and agentic domains to progressively enhance model capabilities. Results show that Youtu-LLM 2B achieves competitive performance with larger models like Qwen3-4B across general and agent benchmarks, particularly in coding and instruction following, despite having fewer parameters.
