Command Palette
Search for a command to run...
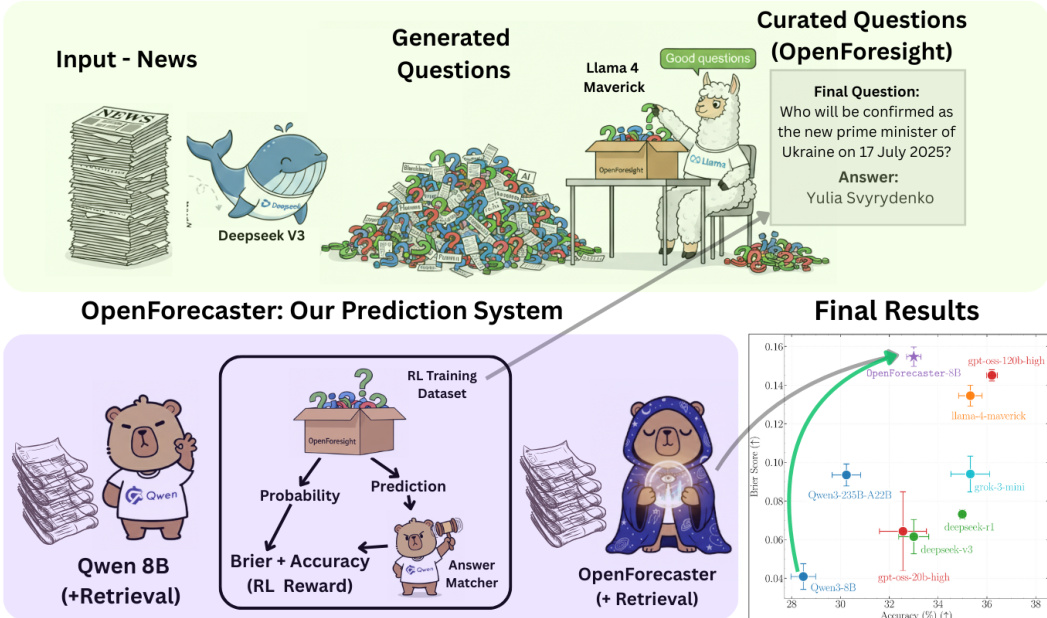
Scaling Open-Ended Reasoning to Predict the Future
Scaling Open-Ended Reasoning to Predict the Future
Nikhil Chandak Shashwat Goel Ameya Prabhu Moritz Hardt Jonas Geiping
Abstract
High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.
One-sentence Summary
The authors from the Max Planck Institute for Intelligent Systems, ELLIS Institute Tübingen, Tübingen AI Center, and University of Tübingen propose OpenForecaster8B, a specialized language model trained on OpenForesight—a synthetically generated dataset of forecasting questions from curated news—using offline data to prevent information leakage, with retrieval and an improved RL reward function enhancing prediction accuracy, calibration, and consistency, outperforming larger proprietary models and generalizing across benchmarks, with all resources open-sourced.
Key Contributions
-
The paper addresses the challenge of training language models for open-ended forecasting—predicting unstructured, natural language events without predefined outcome sets—by introducing a scalable method to generate diverse, real-world forecasting questions from daily news, overcoming limitations of existing data sources like prediction markets that are narrow, biased, and low in volume.
-
The authors develop OpenForecaster8B, a specialized model trained on their OpenForesight dataset using a carefully designed pipeline that avoids future information leakage by relying on offline news snapshots for both data generation and retrieval, and improve performance through retrieval-augmented inference and a refined reward function in Group Relative Policy Optimization (GRPO).
-
Evaluated on held-out data from May to August 2025, the model achieves accuracy, calibration, and consistency comparable to much larger proprietary models, with calibration gains generalizing across benchmarks, and the full system—including models, code, and data—is open-sourced to advance accessible research in language model forecasting.
Introduction
The authors address the challenge of training large language models (LLMs) for open-ended forecasting—predicting future events described in natural language without predefined outcome options. This task is critical for capturing unexpected, high-impact developments like scientific breakthroughs or geopolitical shifts, which are often missed by traditional prediction markets that rely on binary or multiple-choice questions. Prior work faces limitations: data scarcity due to human-curated questions, a dominance of binary outcomes leading to noisy reinforcement learning signals, and skewed distributions favoring specific domains like U.S. politics or crypto. To overcome these, the authors introduce a scalable pipeline that automatically generates high-quality, open-ended forecasting questions from static monthly news snapshots. Using a multi-stage process—question generation with DeepSeek-v3, validation via Llama-4-Maverick, and leakage removal—they ensure questions are specific, answerable, and free from answer hints. They then train models using Group Relative Policy Optimization (GRPO) with Brier scoring, enabling models to improve both accuracy and calibration. The approach demonstrates that open-ended forecasting can be effectively scaled, with an 8B model achieving performance competitive with proprietary models, while also showing generalization to out-of-distribution events.
Dataset
-
The dataset, named OpenForesight, is built from approximately 248,000 deduplicated English-language news articles collected from June 2023 to April 2025, sourced from diverse global outlets including Forbes, CNN, Hindustan Times, Deutsche Welle, and The Irish Times. These articles are drawn from the CommonCrawl News (CCNews) Corpus, which provides static, date-accurate snapshots that prevent future information leakage.
-
From each article, a sample creator model (DeepSeek v3) generates up to three forecasting questions, each including: a question about an event’s prediction, a brief background with definitions, resolution criteria (source of truth, resolution date, answer format), a verbatim short answer (1–3 words, non-numeric, typically a name or location), and a link to the source article.
-
After generation, the dataset undergoes multiple filtering stages: 60% of candidate questions are removed due to ambiguity or lack of clear resolution; articles yielding multiple valid questions have the best one selected via a sample selector (Llama-4-Maverick); numeric answers are excluded; and direct answer leakage is addressed through model rewriting, rejection, and a final string-matching filter.
-
A final data editing step ensures all questions resolve after January 1, 2024, and only questions with valid, unambiguous resolution criteria are retained. This process reduces the initial ~745,000 samples to a final training set of 52,000 high-quality, unique samples.
-
The validation set consists of 207 questions generated from 500 randomly sampled Guardian articles in July 2025, using a more capable model (o4-mini-high) to improve quality and achieve a 40% retention rate.
-
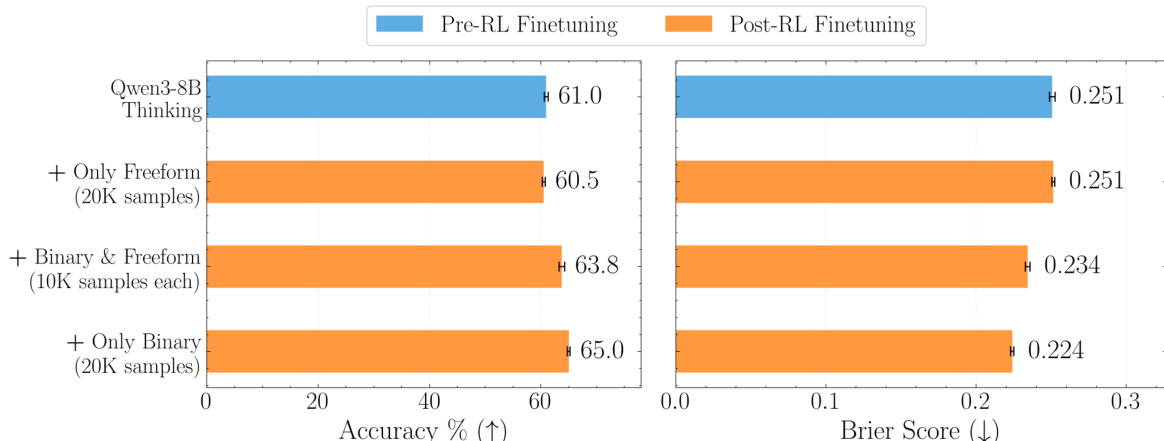
The dataset is used to train forecasting models with a mixture of free-form and binary questions, with experiments showing that combining both types yields the best performance. Training on OpenForesight leads to significant improvements in accuracy and Brier score, even outperforming larger models when scaled.
-
Answer types are dominated by People and Places (65%) and Miscellaneous Entities (35%), reflecting broad coverage across individuals, locations, organizations, teams, and other named entities.
-
Resolution criteria are explicitly defined for each question, specifying a verifiable source of truth, a fixed resolution date, and a precise answer format—ensuring consistency and reliability in evaluation.
-
The test set is manually filtered to exclude questions with multiple answers, unresolved future events, niche relevance, or already established facts, ensuring only valid, answerable questions are included.
Method
The authors leverage a multi-stage pipeline to generate and curate open-ended forecasting questions from news articles, forming the foundation of their training dataset, OpenForesight. The process begins with input news articles, which are processed by a language model to generate multiple candidate questions. These questions are then subjected to a validation and selection phase, where a separate language model evaluates each for adherence to specific criteria: the question-answer pair must be grounded in the source article, the question must be forward-looking (e.g., in future tense), and the answer must be definite, unambiguous, and resolvable by a specified date. This validation step ensures the quality and relevance of the generated questions. From multiple questions derived from a single article, the system selects the best one, prioritizing those with clear, unique answers and high relevance to enhance data diversity. Following validation, a final editing stage addresses potential information leakage, where the model checks the question's title, background, and resolution criteria for any direct or indirect hints about the answer. If leakage is detected, the model rewrites the offending spans using generic placeholders. This rigorous curation process ensures that the final dataset is both high-quality and free from future information bias.
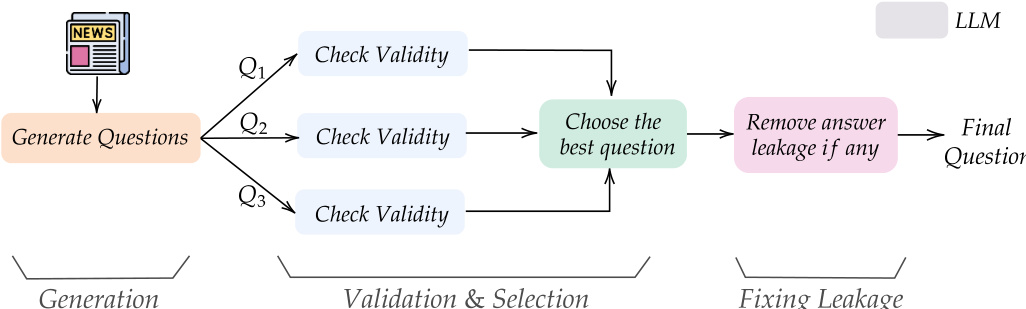
The core prediction system, named OpenForecaster, is built upon the Qwen 8B model and incorporates retrieval-augmented generation to improve forecasting performance. The system takes a forecasting question as input and generates a prediction, which is then evaluated by an answer matcher to determine the probability of the prediction being correct. This probability, along with the prediction's accuracy, is used to compute a reinforcement learning (RL) reward, which is designed to optimize for both brevity and accuracy. The RL training dataset is constructed from the OpenForesight dataset, and the model is trained using this reward signal to improve its forecasting capabilities. The system is designed to be retrieval-augmented, meaning it can access external information to inform its predictions, which is particularly important for forecasting tasks where relevant context may not be fully contained within the question itself.
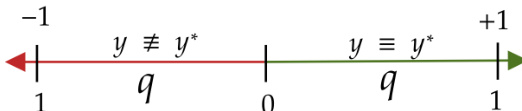
The authors employ a reward function for reinforcement learning that is designed to improve the calibration of the model's predictions. The reward function is based on the difference between the model's predicted probability and the actual outcome, with a penalty for overconfidence. The reward is defined as R=21(1+∣y−y∗∣y−y∗), where y is the model's predicted probability and y∗ is the actual outcome (1 for correct, 0 for incorrect). This reward function encourages the model to be well-calibrated, meaning that predictions with a certain probability should be correct approximately that fraction of the time. The reward function is used to train the model using reinforcement learning, with the goal of improving the accuracy, calibration, and consistency of its predictions.
Experiment
- Reward design ablation shows that combining accuracy and Brier score improves both accuracy and calibration, outperforming baseline accuracy-only or Brier-only rewards; the hybrid reward reduces over-reliance on low-confidence "Unknown" predictions.
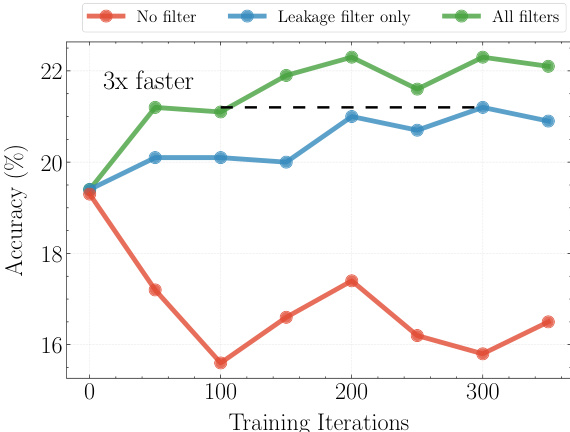
- Retrieval of up to five relevant news chunks (512 tokens each) from a curated CCNews corpus significantly boosts accuracy by 9–18%, with performance plateauing beyond five chunks.
- Training on the OpenForesight dataset (50,000 samples) with retrieval and the proposed reward function leads to strong performance on open-ended forecasting: OpenForecaster8B achieves a Brier score surpassing GPT OSS 120B and accuracy exceeding Qwen3 235B, with a 25% absolute accuracy improvement on Llama 3.1 8B.
- On the external FutureX benchmark (86 questions), OpenForecaster8B achieves the highest accuracy and near-best Brier score, outperforming larger proprietary models.
- Calibration improvements generalize to other domains: OpenForecaster8B shows significant gains on SimpleQA, MMLU-Pro, and GPQA-Diamond, enabling better uncertainty estimation and reduced hallucinations via simple confidence thresholds.
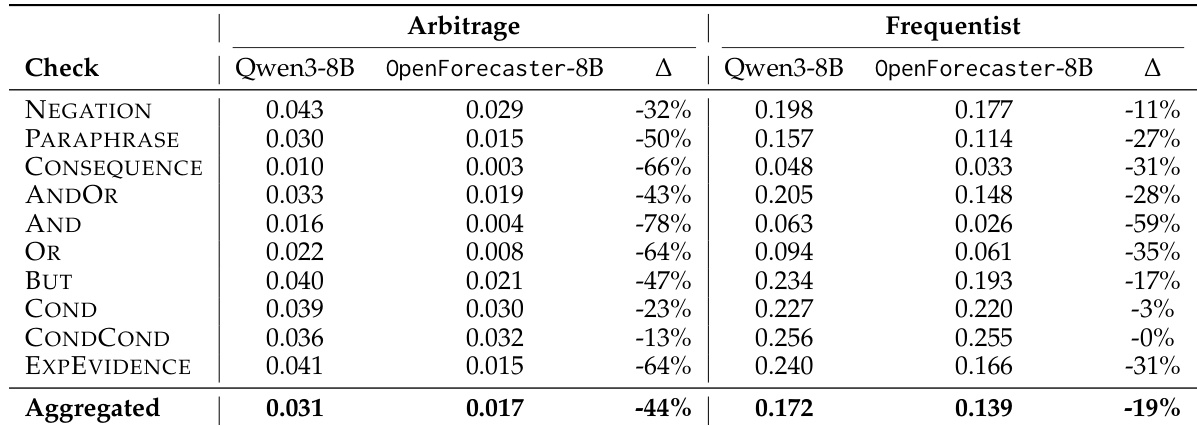
- Long-term prediction consistency improves by 44% on arbitrage metrics and 19% on frequentist metrics, indicating more logically coherent reasoning over time.
- Ablation studies confirm that free-form forecasting data is essential for open-ended performance, while combining binary and free-form data yields the best trade-off across evaluation tasks.
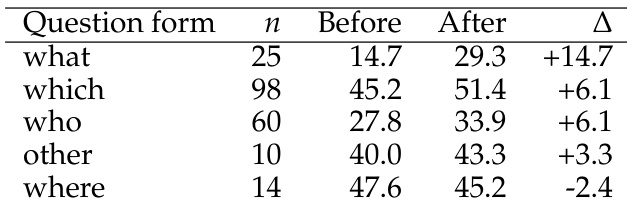
- Qualitative analysis reveals improvements in accuracy and confidence calibration for "who", "what", and "which" questions, though performance regresses slightly on "where" questions and in cases involving entity confusion or missing information.
The authors use a reward combining accuracy and Brier score to train their model, which leads to improved performance on both accuracy and calibration compared to using either metric alone. The results show that the proposed reward design enhances exploration and reduces overuse of "Unknown" predictions, resulting in better overall forecasting performance.
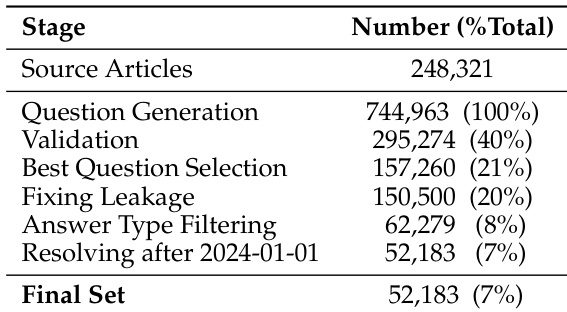
The authors use a multi-stage process to curate their dataset, starting with 248,321 source articles and generating 744,963 questions. After filtering and validation steps, the final dataset consists of 52,183 samples, with 7% of the initial articles contributing to the final set.
The authors use a table to evaluate the consistency of probabilistic predictions made by Qwen3-8B and the trained OpenForecaster-8B model on long-term forecasting questions. Results show that the trained model significantly reduces violation scores across most consistency checks, with a 44% reduction in arbitrage violations and a 19% reduction in frequentist violations compared to the baseline. This indicates that the training process improves logical consistency in the model's reasoning.
The authors use a retrieval system with a 5-chunk context to improve forecasting accuracy, and the results show that adding retrieval leads to significant gains in accuracy across models. The green line, representing the model with all filters applied, consistently outperforms the other two configurations, achieving higher accuracy and demonstrating that filtering improves performance.
Results show that the model's performance improves significantly on questions of the form "what", "which", and "who", with average accuracy increases of 14.7, 6.1, and 6.1 points respectively. However, performance decreases on "where" questions, dropping by 2.4 points, indicating a specific weakness in location-based predictions.