Command Palette
Search for a command to run...
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
GaMO: Geometry-aware Multi-view Diffusion Outpainting for Sparse-View 3D Reconstruction
Yi-Chuan Huang Hao-Jen Chien Chin-Yang Lin Ying-Huan Chen Yu-Lun Liu
Abstract
Recent advances in 3D reconstruction have achieved remarkable progress in high-quality scene capture from dense multi-view imagery, yet struggle when input views are limited. Various approaches, including regularization techniques, semantic priors, and geometric constraints, have been implemented to address this challenge. Latest diffusion-based methods have demonstrated substantial improvements by generating novel views from new camera poses to augment training data, surpassing earlier regularization and prior-based techniques. Despite this progress, we identify three critical limitations in these state-of-the-art approaches: inadequate coverage beyond known view peripheries, geometric inconsistencies across generated views, and computationally expensive pipelines. We introduce GaMO (Geometry-aware Multi-view Outpainter), a framework that reformulates sparse-view reconstruction through multi-view outpainting. Instead of generating new viewpoints, GaMO expands the field of view from existing camera poses, which inherently preserves geometric consistency while providing broader scene coverage. Our approach employs multi-view conditioning and geometry-aware denoising strategies in a zero-shot manner without training. Extensive experiments on Replica and ScanNet++ demonstrate state-of-the-art reconstruction quality across 3, 6, and 9 input views, outperforming prior methods in PSNR and LPIPS, while achieving a 25times speedup over SOTA diffusion-based methods with processing time under 10 minutes. Project page: https://yichuanh.github.io/GaMO/
One-sentence Summary
The authors from National Yang Ming Chiao Tung University propose GaMO, a geometry-aware multi-view diffusion outpainter that expands sparse input views to enhance 3D Gaussian Splatting reconstruction, achieving superior geometric consistency and visual quality by leveraging zero-shot multi-view conditioning and geometry-aware denoising, outperforming prior diffusion-based methods in PSNR and LPIPS while reducing processing time by 25×.
Key Contributions
-
Sparse-view 3D reconstruction faces challenges in handling unobserved regions, leading to holes, ghosting, and geometric inconsistencies, particularly when relying on novel view generation from diffusion models that introduce misalignment and artifacts across views.
-
GaMO introduces a geometry-aware multi-view outpainting framework that expands the field of view from existing camera poses, leveraging multi-view conditioning and zero-shot geometry-aware denoising to preserve consistency and avoid the pitfalls of novel view synthesis.
-
Evaluated on Replica and ScanNet++, GaMO achieves state-of-the-art results in PSNR and LPIPS across 3, 6, and 9 input views, while reducing reconstruction time to under 10 minutes—25× faster than prior diffusion-based methods—without requiring any training.
Introduction
Reconstructing 3D scenes from limited input views is critical for applications like virtual tours and telepresence, but prior methods struggle with incomplete geometry and visual artifacts due to sparse data. While recent diffusion-based approaches improve reconstruction by generating novel views, they suffer from geometric inconsistencies, poor coverage beyond known view peripheries, and high computational costs from complex trajectory planning. The authors introduce GaMO, a geometry-aware multi-view outpainting framework that expands the field of view around existing camera poses instead of generating new ones. This approach inherently preserves geometric consistency, avoids multi-view alignment issues, and enables zero-shot, efficient reconstruction without fine-tuning. GaMO achieves state-of-the-art results on Replica and ScanNet++ across 3, 6, and 9 input views, improving both PSNR and LPIPS metrics while delivering a 25× speedup and completing reconstructions in under 10 minutes.
Method
The authors leverage a three-stage pipeline for sparse-view 3D reconstruction, beginning with a coarse 3D initialization to establish geometric priors. This initial step uses DUSSt3R to generate a point cloud and trains a coarse 3D Gaussian Splatting (3DGS) model to capture the scene's structure. From this model, an opacity mask and a coarse color rendering are generated for each target outpainted view. The opacity mask is derived by rendering the scene with an enlarged field-of-view (FOV) and thresholding the resulting opacity map to identify regions requiring outpainting. The coarse rendering provides appearance priors. These two outputs serve as essential geometry and appearance cues for the subsequent diffusion-based outpainting stage.
The core of the method is the GaMO (Geometry-aware Multi-view Diffusion Outpainter), a multi-view diffusion model that generates outpainted views with enlarged FOV. The model operates in latent space using DDIM sampling for efficient denoising. It conditions the generation process on multiple signals to ensure geometric consistency. For camera representation, Plücker ray embeddings are used, providing dense 6D ray parameterizations for each pixel that encode both ray origin and direction. For geometric correspondence, input RGB images and Canonical Coordinate Maps (CCM) are warped to align with the expanded FOV, and the original inputs are downsampled and placed at the center of the warped features to create augmented signals. For appearance, the input RGB images are encoded into clean latent features using a variational autoencoder (VAE). All conditioning signals are processed through lightweight convolutional encoders and fused with the latent features to condition the pre-trained diffusion model in a zero-shot manner.
The central component of GaMO is the denoising process with mask latent blending, which integrates the coarse geometry priors into the diffusion loop. At selected denoising timesteps, the denoised latent is blended with the coarse latent, which is obtained by encoding the coarse rendering. To ensure both latents share the same noise level, noise is added to the coarse latent. The blending is performed using a latent-space mask derived from the opacity mask, with the mask evolution controlled by iterative mask scheduling. This process ensures that outpainted content respects existing scene structures while generating plausible peripheral regions.
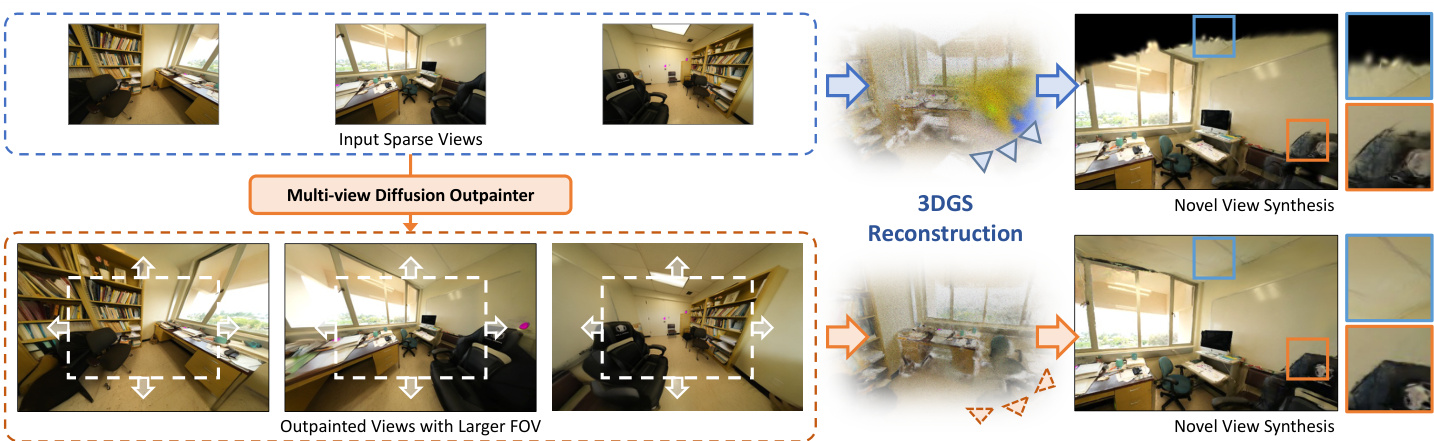
To maintain smooth transitions across blended regions, noise resampling is performed after each blending operation. After blending, the model predicts the clean latent from the blended latent and adds noise back to the current timestep. This resampling prevents boundary artifacts and ensures smooth integration between the coarse geometry and generated content. The iterative mask scheduling strategy dynamically adjusts the mask region throughout the denoising process. It employs progressively shrinking mask sizes at specific denoising steps to balance generative freedom with geometric consistency, allowing the model to first explore peripheral content and later refine geometry within coarse regions. This framework ensures that outpainted regions seamlessly blend with known content while maintaining geometric plausibility, requiring only inference without fine-tuning the backbone diffusion model.
Experiment
- 3DGS refinement with outpainted views: Joint optimization using input and outpainted views validates that perceptual loss (LPIPS) and masked latent blending improve reconstruction quality, reducing artifacts and enhancing geometric consistency in unobserved regions.
- Quantitative evaluation on Replica and ScanNet++: Achieved 25.84 dB PSNR and 25.9% lower LPIPS than GuidedVD-3DGS on Replica, and 23.41 dB PSNR with 11.3% lower LPIPS on ScanNet++, while being 25× faster.
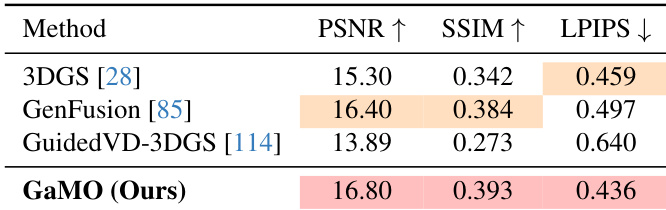
- Generalization to Mip-NeRF 360: Outperformed 3DGS, GenFusion, and GuidedVD-3DGS in PSNR, SSIM, and LPIPS across nine outdoor and indoor scenes, maintaining structural fidelity and high-frequency details.
- Ablation studies: Demonstrated that iterative mask scheduling, hard masking, and noise resampling improve outpainting quality and 3DGS refinement, with perceptual loss significantly reducing artifacts and filling holes.
- Multi-view consistency: Outperformed adapted diffusion baselines (SEVA, MGenMaster) in outpainting consistency and reconstruction quality, avoiding multi-view inconsistencies and noise.
- Runtime: Completed 6-view reconstruction in under nine minutes on a single RTX 4090 GPU, with efficient pipeline stages.
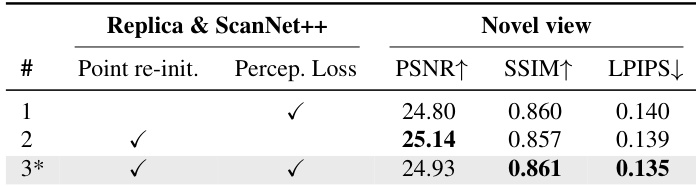
Results show that combining point cloud re-initialization and perceptual loss during 3DGS refinement leads to the best performance on both Replica and ScanNet++ datasets, achieving the highest PSNR and SSIM while maintaining the lowest LPIPS. The full method with both components outperforms the baseline and individual ablation variants across all metrics.
Results show that GaMO achieves the highest PSNR and SSIM values while also attaining the lowest LPIPS score among the compared methods, indicating superior reconstruction quality and perceptual consistency. The authors use a joint optimization framework that combines input views and outpainted views to refine the 3DGS model, with perceptual loss guiding the filling of unobserved regions.
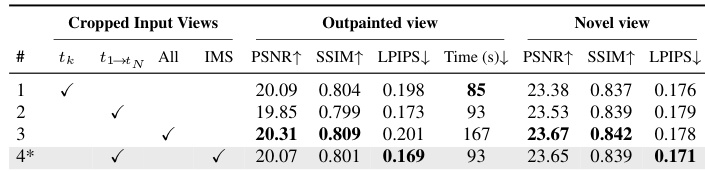
The authors use a multi-step mask blending strategy with iterative mask scheduling to improve the quality of outpainted views, achieving the best performance in terms of PSNR, SSIM, and LPIPS compared to single-step and every-step blending approaches. Results show that their method produces more coherent and geometrically consistent reconstructions, particularly in challenging regions with complex structures.
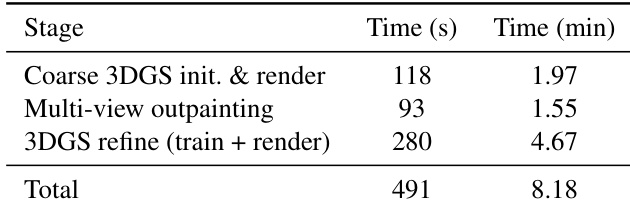
The authors use a three-stage pipeline for 3D reconstruction, with the total end-to-end runtime on a single NVIDIA RTX 4090 GPU being 491 seconds (8.18 minutes). The most time-consuming stage is the 3DGS refinement, which takes 280 seconds (4.67 minutes), followed by multi-view outpainting at 93 seconds (1.55 minutes) and coarse 3DGS initialization and rendering at 118 seconds (1.97 minutes).
Results show that the proposed method achieves higher PSNR, SSIM, and lower LPIPS compared to GuidedVD-3DGS across all view settings on ScanNet++ with 3, 6, and 9 input views, while also being significantly faster in terms of reconstruction time.
