Command Palette
Search for a command to run...
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
Yuxue Yang Lue Fan Ziqi Shi Junran Peng Feng Wang Zhaoxiang Zhang
Abstract
In this paper, we propose NeoVerse, a versatile 4D world model that is capable of 4D reconstruction, novel-trajectory video generation, and rich downstream applications. We first identify a common limitation of scalability in current 4D world modeling methods, caused either by expensive and specialized multi-view 4D data or by cumbersome training pre-processing. In contrast, our NeoVerse is built upon a core philosophy that makes the full pipeline scalable to diverse in-the-wild monocular videos. Specifically, NeoVerse features pose-free feed-forward 4D reconstruction, online monocular degradation pattern simulation, and other well-aligned techniques. These designs empower NeoVerse with versatility and generalization to various domains. Meanwhile, NeoVerse achieves state-of-the-art performance in standard reconstruction and generation benchmarks. Our project page is available at https://neoverse-4d.github.io
One-sentence Summary
The authors from NLPR & MAIS, CASIA and CreateAI propose NeoVerse, a scalable 4D world model that enables pose-free, feed-forward 4D Gaussian Splatting reconstruction from monocular videos via online degradation simulation, achieving state-of-the-art performance in 4D reconstruction and novel-trajectory video generation across diverse real-world scenarios.
Key Contributions
- NeoVerse addresses the scalability limitations of existing 4D world models by enabling feed-forward, pose-free 4D reconstruction from diverse in-the-wild monocular videos, eliminating the need for expensive multi-view data or cumbersome offline pre-processing.
- The model introduces online monocular degradation simulation via Gaussian culling and average geometry filtering, which effectively mimics challenging rendering conditions and enhances the robustness and coherence of generated videos.
- NeoVerse achieves state-of-the-art performance in both 4D reconstruction and novel-trajectory video generation benchmarks, demonstrating strong generalization across diverse real-world video data.
Introduction
The authors leverage in-the-wild monocular videos to build a scalable 4D world model, addressing critical limitations in existing approaches that rely on curated multi-view data or computationally heavy offline reconstruction. Prior work in 4D modeling often depends on specialized, hard-to-acquire multi-view dynamic videos or requires extensive pre-processing steps such as depth estimation and Gaussian field reconstruction, which hinder scalability and flexibility. These constraints prevent effective use of the vast, diverse, and low-cost monocular video data available in real-world settings. To overcome this, the authors introduce NeoVerse, a feed-forward 4D Gaussian Splatting (4DGS) framework that enables online, efficient reconstruction from monocular videos using bidirectional motion modeling and sparse key-frame processing. By integrating real-time monocular degradation simulations—such as Gaussian culling and average geometry filtering—NeoVerse creates realistic training conditions for generative models, allowing end-to-end training on up to 1 million uncurated video clips. This approach achieves state-of-the-art performance in both 4D reconstruction and novel-view video generation while supporting diverse applications like video editing, stabilization, and super-resolution.
Dataset
-
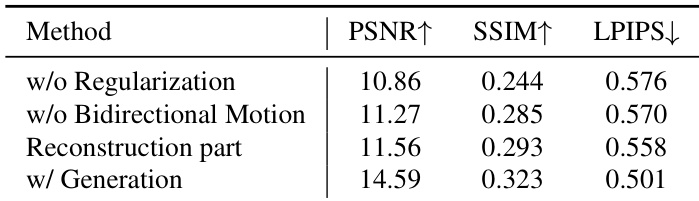
The dataset is divided into five categories used for training:
- Dynamic datasets with 3D flow for velocity supervision
- Dynamic datasets with depth and camera poses
- Dynamic datasets with incomplete 3D information (e.g., only camera poses or depth)
- Static datasets, where 3D flow is assumed to be zero
- Monocular videos, used exclusively for training the generation model
-
The reconstruction model is trained on categories ① through ④, leveraging 3D flow, depth, and pose data where available.
-
The generation model is trained solely on monocular video data from category ⑤.
-
Despite SpatialVID providing 3D information, it is excluded from reconstruction training due to inconsistent and unreliable depth quality.
-
No explicit cropping strategy is mentioned, but data is processed to align with task-specific requirements, including metadata construction for motion and depth supervision.
-
Training uses a mixture of these subsets, with ratios determined by the model’s objectives—reconstruction prioritizes 3D-consistent dynamic and static scenes, while generation focuses on visual realism from monocular input.
Method
The authors leverage a feed-forward architecture built upon the VGGT backbone to achieve pose-free 4D reconstruction from monocular videos. This process begins with extracting frame-wise features using a pretrained DINOv2 encoder, which are then processed through a series of Alternating-Attention blocks to obtain frame features. To address temporal unawareness in motion modeling, a bidirectional motion-encoding branch is introduced. This branch splits the frame features into forward and backward sequences, using cross-attention mechanisms to generate forward motion features Ftfwd and backward motion features Ftbwd. These features are subsequently used to predict bidirectional linear and angular velocities for Gaussian primitives. The 4D Gaussians are parameterized by 3D position, opacity, rotation, scale, spherical harmonics coefficients, life span, and the aforementioned forward and backward velocities. The 3D positions are derived from back-projected pixel depth, while the static attributes are predicted from frame features and the dynamic attributes from the bidirectional motion features.

The framework integrates reconstruction and generation in a scalable pipeline. For efficient training, the authors propose reconstructing from sparse key frames rather than the entire video, rendering from all frames due to the efficiency of the rendering process. This approach enables interpolation of the Gaussian field at non-keyframes using the bidirectional motion modeling. For a non-key-frame query timestamp tq, the position of a Gaussian i at key-frame timestamp t is interpolated linearly based on the forward or backward velocity, depending on whether tq is greater than or less than t. The rotation is interpolated using a quaternion conversion of the angular velocity, and the opacity decays over time based on a normalized temporal distance and the Gaussian's life span. To simulate degradation patterns for training the generation model, the authors employ three techniques: visibility-based Gaussian culling to simulate occlusion, an average geometry filter to create flying-edge-pixel effects, and a control branch to incorporate degraded renderings and camera motion information as conditions. The generation model is trained using a denoising diffusion process, with the degraded renderings serving as conditions and the original video frames as targets.

The training scheme is divided into two stages. The reconstruction model is trained with a multi-task loss that includes photometric, camera, depth, motion, and regularization components. The generation model is trained using Rectified Flow and Wan-T2V, with the training objective formulated as a mean squared error between the predicted and ground-truth velocities in the diffusion process. During inference, the model first reconstructs 4DGS and camera parameters from the input video. To improve the representation, Gaussians are aggregated across frames, with a global motion tracking mechanism used to separate static and dynamic parts based on visibility-weighted maximum velocity magnitude. The static and dynamic parts undergo different temporal aggregation strategies. Finally, the resulting Gaussians are rendered into a novel trajectory, and the degraded renderings are used as conditions for the generation model to produce the final novel video.
Experiment
- Reconstruction and generation experiments validate the effectiveness of NeoVerse on static and dynamic 3D video reconstruction, achieving state-of-the-art performance on multiple benchmarks. On the static reconstruction benchmark, NeoVerse surpasses existing methods in all metrics, with significant improvements over MoVieS and StreamSplat, which are not included due to lack of open-source availability. On dynamic reconstruction, NeoVerse outperforms competitors, including TrajectoryCrafter and ReCamMaster, particularly in handling complex motions and maintaining geometric fidelity.
- In novel view generation, NeoVerse achieves superior results on VBench, with 400 test cases across diverse in-the-wild videos, demonstrating high-quality rendering and precise trajectory controllability. The model maintains strong performance while enabling efficient inference, accelerated by distillation and bidirectional motion design.
- Qualitative evaluations show that NeoVerse produces visually accurate renderings with fewer artifacts, such as ghosting and blurring, compared to baselines. It effectively suppresses artifacts through degradation simulation and enables contextually grounded imagination in unobserved regions, such as occluded people or objects.
- Ablation studies confirm the importance of motion modeling, opacity regularization, degradation simulation, and global motion tracking. Removing any component leads to performance degradation, especially in artifact suppression and trajectory accuracy.
- The model supports diverse downstream applications: 3D tracking via 3D flow association, video editing using binary and textual conditions, video stabilization through trajectory smoothing, and video super-resolution via flexible rendering resolution. It also enables image-to-world and single-view to multi-view generation.
- On the 1M self-collected monocular video dataset and 18 public datasets, NeoVerse demonstrates scalability and robustness to diverse real-world scenarios, with training conducted on 32 A800 GPUs using a two-stage pipeline (150K + 50K iterations).
The authors use the table to summarize the datasets employed in their study, categorizing them into five groups based on data characteristics and their roles in reconstruction and generation tasks. The table shows that datasets are used for both static and dynamic reconstruction, with some also supporting generation, and highlights the scale and diversity of the data, including over 1 million monocular videos collected from the internet.
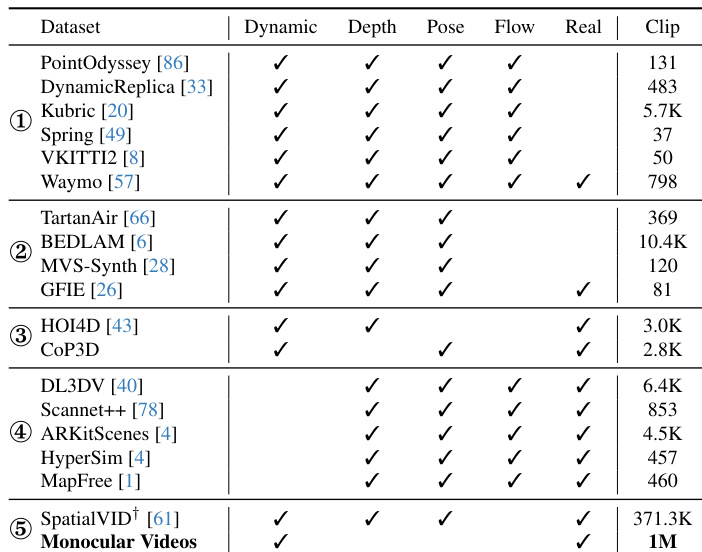
Results show that the proposed method achieves state-of-the-art performance on static reconstruction benchmarks, outperforming existing methods across all metrics including PSNR, SSIM, and LPIPS on both VRNeRF and Scannet++ datasets. The authors use a reconstruction model trained with a multi-task loss and a cosine learning rate schedule, achieving superior results compared to NoPoSplat, Flare, and AnySplat.
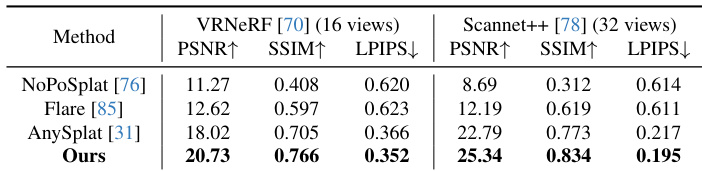
Results show that the proposed method achieves superior performance compared to existing approaches on both ADT and DyCheck benchmarks. On ADT, it outperforms MonST3R and 4DGT in PSNR and SSIM while significantly improving LPIPS, and on DyCheck, it achieves the highest PSNR and SSIM scores with the lowest LPIPS, indicating better reconstruction quality and fewer artifacts.
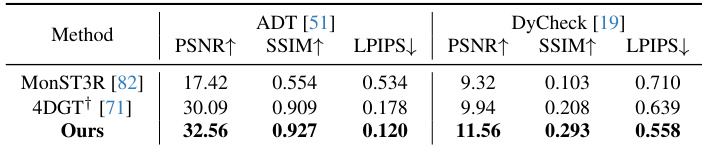
The authors use ablation experiments to evaluate the impact of different components in their pipeline. Results show that adding generation significantly improves performance across all metrics, with the full model achieving the highest PSNR and SSIM and the lowest LPIPS compared to the reconstruction-only version. The inclusion of bidirectional motion and regularization further enhances reconstruction quality, demonstrating their importance in the overall framework.
Results show that the proposed method achieves superior performance in both reconstruction and generation tasks compared to TrajectoryCrafter and ReCamMaster. The authors use a reduced number of key frames to significantly accelerate inference time while maintaining high-quality generation, with the full-frame version achieving the best results in most metrics.
