Command Palette
Search for a command to run...
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
InfiniteVGGT: Visual Geometry Grounded Transformer for Endless Streams
Shuai Yuan Yantai Yang Xiaotian Yang Xupeng Zhang Zhonghao Zhao Lingming Zhang Zhipeng Zhang
Abstract
The grand vision of enabling persistent, large-scale 3D visual geometry understanding is shackled by the irreconcilable demands of scalability and long-term stability. While offline models like VGGT achieve inspiring geometry capability, their batch-based nature renders them irrelevant for live systems. Streaming architectures, though the intended solution for live operation, have proven inadequate. Existing methods either fail to support truly infinite-horizon inputs or suffer from catastrophic drift over long sequences. We shatter this long-standing dilemma with InfiniteVGGT, a causal visual geometry transformer that operationalizes the concept of a rolling memory through a bounded yet adaptive and perpetually expressive KV cache. Capitalizing on this, we devise a training-free, attention-agnostic pruning strategy that intelligently discards obsolete information, effectively ``rolling'' the memory forward with each new frame. Fully compatible with FlashAttention, InfiniteVGGT finally alleviates the compromise, enabling infinite-horizon streaming while outperforming existing streaming methods in long-term stability. The ultimate test for such a system is its performance over a truly infinite horizon, a capability that has been impossible to rigorously validate due to the lack of extremely long-term, continuous benchmarks. To address this critical gap, we introduce the Long3D benchmark, which, for the first time, enables a rigorous evaluation of continuous 3D geometry estimation on sequences about 10,000 frames. This provides the definitive evaluation platform for future research in long-term 3D geometry understanding. Code is available at: https://github.com/AutoLab-SAI-SJTU/InfiniteVGGT
One-sentence Summary
The authors from AutoLab, Shanghai Jiao Tong University, and Anyverse Dynamics propose InfiniteVGGT, a causal visual geometry transformer with a bounded, adaptive KV cache that enables infinite-horizon streaming 3D geometry understanding by intelligently pruning obsolete information without retraining. Unlike prior methods, it maintains long-term stability through a rolling memory mechanism compatible with FlashAttention, and they introduce the Long3D benchmark—featuring 10,000-frame sequences—to rigorously evaluate continuous 3D estimation, setting a new standard for long-term visual geometry systems.
Key Contributions
- Existing streaming 3D geometry models face a fundamental trade-off between scalability and long-term stability, either accumulating unbounded memory or suffering from catastrophic drift due to lossy state compression, limiting their applicability in real-time systems.
- InfiniteVGGT introduces a causal visual geometry transformer with a bounded, adaptive rolling memory via a training-free, attention-agnostic pruning strategy that uses key cosine similarity to discard redundant tokens, enabling infinite-horizon streaming while maintaining compatibility with FlashAttention.
- To rigorously evaluate long-term performance, the authors introduce Long3D, the first benchmark for continuous 3D geometry estimation on sequences of approximately 10,000 frames, providing a definitive platform for assessing infinite-horizon stability and accuracy.
Introduction
The authors address the challenge of continuous, long-term 3D scene reconstruction in real-time systems, where existing methods face a fundamental trade-off: offline models achieve high geometric accuracy but are incompatible with streaming due to batch processing, while online approaches either suffer from unbounded memory growth or catastrophic drift from aggressive state compression. Prior work struggles to maintain both scalability and stability over infinite horizons, particularly due to the inefficiency of pruning strategies that rely on attention scores—these require materializing large attention matrices, which contradicts the use of optimized kernels like FlashAttention. To overcome this, the authors introduce InfiniteVGGT, a causal visual geometry transformer that implements a bounded, adaptive rolling memory via a training-free, attention-agnostic pruning strategy based on key cosine similarity. This enables efficient, dynamic retention of semantically distinct tokens while discarding redundant ones, preserving long-term consistency without memory overflow. The system is fully compatible with FlashAttention, supports infinite-length input streams, and is evaluated on the newly proposed Long3D benchmark— the first dataset designed for rigorous, continuous evaluation over 10,000+ frames—providing a definitive testbed for future research in long-term 3D geometry understanding.
Dataset

- The Long3D benchmark consists of 5 long, continuous 3D video sequences captured in diverse indoor and outdoor environments, with each sequence ranging from approximately 2,000 to 10,000 frames—significantly longer than prior benchmarks limited to 1,000 frames or fewer.
- Data was collected using a handheld 3D spatial scanner equipped with an IMU, a 360° horizontal by 59° vertical FOV LiDAR, and an RGB camera (800 × 600 resolution at 10 Hz, 90° FOV).
- Each sequence includes a globally aligned ground-truth point cloud and a corresponding uninterrupted stream of RGB images, enabling evaluation of long-term 3D reconstruction from continuous input.
- The dataset is designed to assess dense-view streaming reconstruction, where models process the full image stream in real time to generate a complete, globally consistent point cloud.
- For evaluation, predicted point clouds are aligned with ground truth using the Iterative Closest Point (ICP) algorithm, following standard practices in the field.
- Performance is measured using four established metrics: Accuracy (Acc.), Completion (Comp.), Chamfer Distance (CD), and Normal Consistency (NC).
- The authors use the Long3D dataset as the primary evaluation benchmark, training models on shorter sequences from existing datasets like 7-Scenes and NRGBD, then testing on Long3D to assess long-term robustness and continuity.
- No explicit cropping is applied; instead, the full sequences are used as captured, preserving temporal continuity.
- Metadata includes scene identifiers, capture timestamps, and sensor calibration data, which are used to synchronize RGB and LiDAR streams and support accurate alignment during evaluation.
Method
The authors leverage a transformer-based architecture adapted for online 3D reconstruction, building upon the offline model VGTT and its streaming variant StreamVGGT. The framework processes a sequence of input frames incrementally, maintaining a key-value (KV) cache to retain contextual information across time. At each timestep, the model generates 3D outputs—camera parameters, depth maps, point maps, and tracking features—by combining frame-specific features from a frame attention module with cached context from prior frames via a causal temporal attention module. This incremental processing enables streaming inference but leads to unbounded memory growth as the KV cache accumulates tokens over time.
To address this, the proposed method introduces a rolling memory paradigm that prunes the KV cache to prevent memory overflow while preserving geometric consistency. The framework begins by establishing an immutable anchor set derived from the KV cache of the first input frame. This anchor set serves as a fixed global reference, ensuring that all subsequent 3D predictions remain aligned to the coordinate system of the initial frame. All subsequent frames contribute to a mutable candidate set, which is subject to compression. The pruning strategy operates independently on each decoder layer and attention head, reflecting their heterogeneous information content.

The retention of tokens within the candidate set is guided by a diversity-aware mechanism. Instead of relying on attention weights, the method measures redundancy through the geometric dispersion of key vectors in the feature space. As shown in the figure below, queries and keys from different frames occupy nearly orthogonal subspaces, indicating that key-space similarity is a stable proxy for redundancy. The diversity score for each key is defined as the negative cosine similarity to the mean of all normalized candidate keys in the same layer and head. Keys that are dissimilar to the mean, and thus more geometrically distinct, are assigned higher scores and are more likely to be retained.

To further optimize memory usage, the method employs a layer-wise adaptive budget allocation. This mechanism assigns a non-uniform storage budget to each decoder layer based on its average information diversity. The diversity score for a layer is computed as the mean of the diversity scores of all its attention heads. A softmax function, modulated by a temperature hyperparameter, normalizes these scores to determine the proportion of the total memory budget allocated to each layer. The final compressed cache is formed by retaining the top-K tokens from the candidate set in each layer and head, according to their diversity scores, and combining them with the immutable anchor set. This approach ensures that the most informative tokens are preserved while maintaining bounded memory and computational efficiency for long-horizon streaming.
Experiment
- Evaluated on 3D reconstruction, video depth estimation, and camera pose estimation tasks using StreamVGGT and the novel Long3D benchmark, demonstrating effectiveness in long-sequence streaming scenarios.
- On 7-Scenes and NRGBD datasets, InfiniteVGGT maintains state-of-the-art reconstruction accuracy with minimal temporal error accumulation, outperforming CUT3R and TTT3R, while avoiding OOM errors that affect baseline methods.
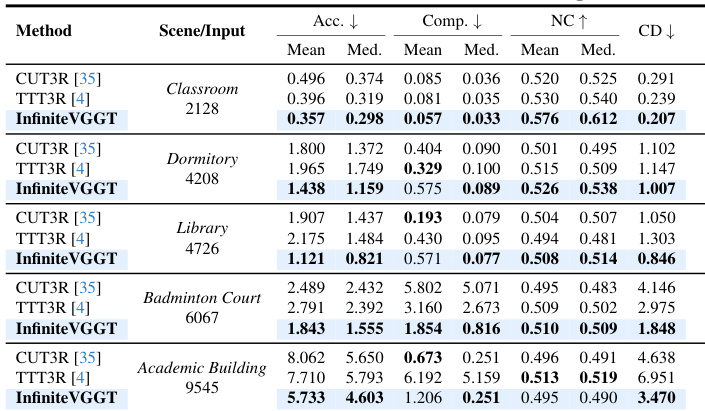
- On Long3D with sequences up to nearly 10,000 frames, InfiniteVGGT achieves robust performance across diverse scenes, effectively limiting temporal drift compared to baselines, though it underperforms slightly on the Comp. metric.
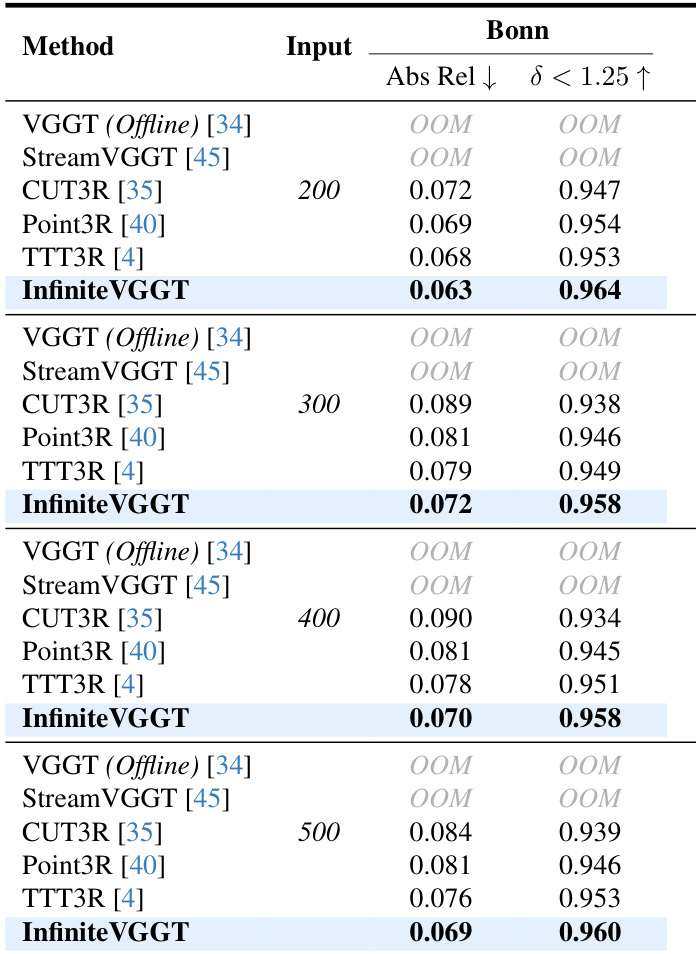
- On the Bonn dataset, InfiniteVGGT shows strong video depth estimation performance on long continuous sequences (200–500 frames), matching or exceeding CUT3R and TTT3R.
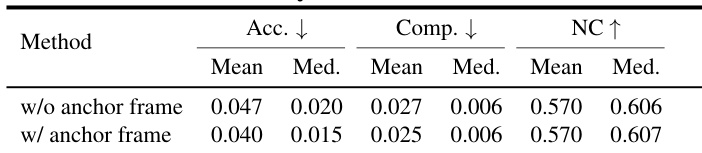
- Ablation studies confirm that cosine similarity-based token selection improves reconstruction accuracy and reduces inference latency, while dynamic layer-wise budget allocation and anchor frame retention significantly enhance point cloud quality and stability.
- The method achieves comparable performance to StreamVGGT on short sequences (50–100 frames) with negligible metric differences and a slight edge in normal consistency, validating its efficiency and robustness.
Results show that InfiniteVGGT achieves state-of-the-art performance on the Long3D benchmark across multiple scenes and sequence lengths, outperforming baselines like CUT3R and TTT3R on most metrics. While it effectively limits temporal error accumulation compared to other methods, it underperforms on the mean Comp. metric, indicating a key area for future improvement.
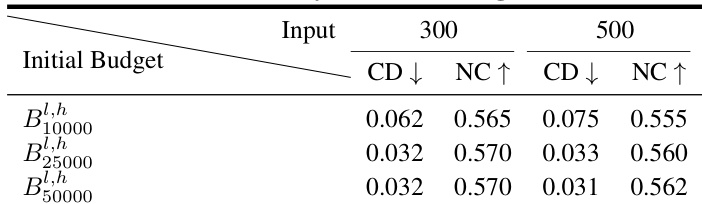
Results show that increasing the initial token storage budget improves reconstruction quality, with a significant drop in chamfer distance and improvement in normal consistency when moving from B10000l,h to B25000l,h. However, further increasing the budget to B50000l,h yields no additional gains, indicating that B25000l,h is sufficient for optimal performance.
Results show that InfiniteVGGT achieves the best performance on the Bonn dataset for video depth estimation, outperforming baselines like CUT3R and TTT3R across different input lengths. The method maintains high accuracy and consistency, with the lowest absolute relative error and highest δ < 1.25 metric values, demonstrating its effectiveness in long-term depth estimation.
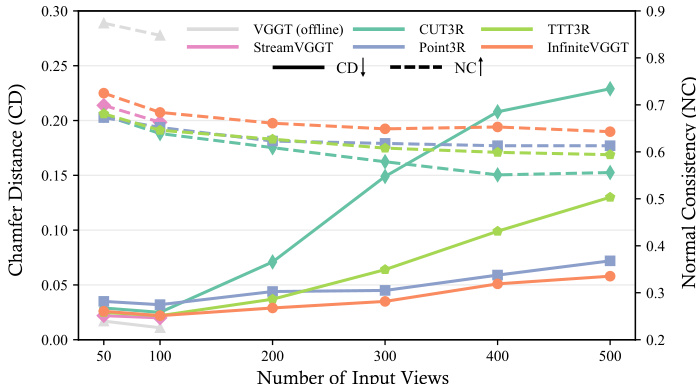
Results show that InfiniteVGGT maintains stable reconstruction accuracy across increasing input frames, outperforming baselines like CUT3R and TTT3R in both chamfer distance and normal consistency. The method effectively limits temporal error accumulation, achieving consistent performance on long sequences where other approaches degrade or fail due to memory constraints.
Results show that incorporating an anchor frame significantly improves reconstruction accuracy, reducing the mean chamfer distance from 0.047 to 0.040 while maintaining consistent normal consistency. The authors use this ablation to demonstrate that preserving the first frame's tokens prevents error accumulation and enhances robustness in long-sequence 3D reconstruction.