Command Palette
Search for a command to run...
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
Marc Finzi Shikai Qiu Yiding Jiang Pavel Izmailov J. Zico Kolter Andrew Gordon Wilson
Abstract
Can we learn more from data than existed in the generating process itself? Can new and useful information be constructed from merely applying deterministic transformations to existing data? Can the learnable content in data be evaluated without considering a downstream task? On these questions, Shannon information and Kolmogorov complexity come up nearly empty-handed, in part because they assume observers with unlimited computational capacity and do not target the useful information content. In this work, we identify and exemplify three seeming paradoxes in information theory: (1) information cannot be increased by deterministic transformations; (2) information is independent of the order of data; (3) likelihood modeling is merely distribution matching. To shed light on the tension between these results and modern practice, and to quantify the value of data, we introduce epilepticsity, a formalization of information capturing what computationally bounded observers can learn from data. Epilepticsity captures the structural content in data while excluding time-bounded entropy, the random unpredictable content exemplified by pseudorandom number generators and chaotic dynamical systems.
One-sentence Summary
To address the limitations of Shannon information and Kolmogorov complexity in modern machine learning, researchers propose epiplexity, a new information-theoretic framework that quantifies the learnable structural content in data for computationally bounded observers by distinguishing useful patterns from time-bounded entropy.
Key Contributions
- This work introduces epilepticsity, a formalization of information that quantifies the structural content learnable by computationally bounded observers while excluding time-bounded entropy.
- The paper presents an empirical estimator for epilepticsity that allows for the comparison of datasets and data interventions by measuring the reusable structural information they induce in a model.
- The research demonstrates how the epilepticsity framework explains empirical phenomena in machine learning, such as the effectiveness of data augmentation, curriculum design, and synthetic data that may not improve traditional likelihood metrics.
Introduction
Modern machine learning success often depends on the quality and structure of training data, yet classical information theory provides little guidance for data selection or curation. Existing frameworks like Shannon entropy and Kolmogorov complexity assume observers with unlimited computational capacity, which leads to theoretical paradoxes where deterministic transformations appear unable to increase information and likelihood modeling is viewed as merely matching a distribution. These limitations fail to explain empirical phenomena such as the utility of synthetic data, the impact of data ordering, or how models can learn emergent structures that were not explicitly present in the generating process.
The authors leverage the concept of computational boundedness to resolve these tensions by introducing epiplexity, a formal measure of structural information that a resource-constrained observer can extract from data. By decomposing information into time-bounded entropy (random, unpredictable content) and epiplexity (learnable, structural content), the authors provide a theoretical foundation for understanding how models acquire reusable knowledge. They demonstrate that epiplexity can track improvements in out-of-distribution generalization and explain why certain data modalities, such as language, are more effective for pre-training than others.
Dataset
The authors utilize two distinct datasets for their experiments:
- OpenWebText: Sourced from Hugging Face, this text dataset is filtered to retain only documents consisting of 96 common alphanumeric symbols. The authors process this data using character level tokenization.
- CIFAR-5M: Sourced from GitHub, this image dataset undergoes a specific transformation where 32×32×3 color images are converted to greyscale. These images are then flattened into 1D sequences of 1024 elements using raster scan order. The vocabulary for this subset is defined by the set of pixel intensities ranging from 0 to 255.
Method
To quantify the information content of data, the authors build upon the Minimum Description Length (MDL) principle. In its statistical two-part code instantiation, the goal is to find a model H from a candidate set H that minimizes the total description length:
L(x)=minH∈HL(H)−logP(x∣H),
where L(H) represents the bits required to encode the model, and −logP(x∣H) represents the bits required to encode the data given that model. This formulation inherently penalizes overly complex models unless they significantly improve data compression.
The authors extend this concept to a computationally bounded setting by introducing epiplexity and time-bounded entropy. They define a T-time probabilistic model as a program P on a prefix-free universal Turing machine U that can both evaluate probabilities and sample data within T(n) steps. For a random variable X, the T-bounded epiplexity ST(X) is defined as the length of the program P∗ that minimizes the expected two-part code length, while the time-bounded entropy HT(X) is the expected log-loss under that same program.
As shown in the figure below:
This framework allows for a formal distinction between structural information (epiplexity) and random information (entropy). For instance, pseudorandom number generators (PRGs) exhibit nearly maximal time-bounded entropy but negligible epiplexity, meaning they appear random to a polynomial-time observer despite being generated by a simple program.
To practically estimate these quantities for neural networks, the authors propose two estimation procedures. The first is prequential coding, which approximates the model description length by observing the cumulative loss during the training process. Specifically, the model description length is estimated as the difference between the total code length of the training data and the model, which can be visualized as the area under the loss curve above the final loss.
The second, more rigorous approach is resequential coding. This method constructs an explicit code for the model by training a student model on synthetic tokens sampled from a teacher model. This approach avoids paying for the entropy of the original training data and instead focuses on the complexity of the learning process itself.
The authors also analyze how these measures scale with the computational budget T. By combining neural scaling laws with the prequential coding framework, they derive analytical models showing that as compute increases, the optimal model size and training dataset size both grow. In the large-compute regime, epiplexity typically grows with the compute budget as more intricate structures are extracted, while the per-token time-bounded entropy decays toward the irreducible loss.
Experiment
The experiments evaluate different methods for estimating epilepticity, comparing the efficiency of prequential coding against the rigor of requential coding across various datasets including cellular automata, induction tasks, and natural data. Results demonstrate that higher epilepticity correlates with a model's ability to extract structural information, which in turn serves as a predictor for out-of-distribution generalization in tasks like chess. Furthermore, the findings suggest that epilepticity can be used to characterize the complexity of data types and provide a framework for understanding how deterministic processes can increase time-bounded information content.
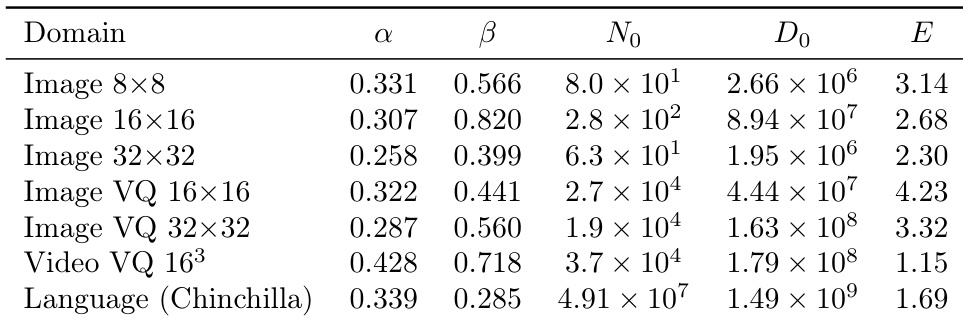
The authors present scaling law parameters for various data domains including image, video, and language. The results demonstrate how different resolutions, tokenization methods, and data types influence the constants used to describe model loss behavior. Applying VQ tokenization to image data leads to higher values for certain scaling constants compared to standard image representations. Video data exhibits different scaling characteristics than image data, particularly in its relationship to temporal dimensions. Language data follows a distinct scaling pattern compared to the image and video domains.
The authors investigate scaling law parameters across image, video, and language domains to determine how data characteristics influence model loss behavior. The experiments validate how varying resolutions, tokenization methods, and temporal dimensions impact scaling constants. The findings reveal that different data modalities and representation techniques, such as VQ tokenization, result in distinct scaling patterns across the studied domains.