Command Palette
Search for a command to run...
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning
Atlas: Orchestrating Heterogeneous Models and Tools for Multi-Domain Complex Reasoning
Jinyang Wu Guocheng Zhai Ruihan Jin Jiahao Yuan Yuhao Shen Shuai Zhang Zhengqi Wen Jianhua Tao
Abstract
The integration of large language models (LLMs) with external tools has significantly expanded the capabilities of AI agents. However, as the diversity of both LLMs and tools increases, selecting the optimal model-tool combination becomes a high-dimensional optimization challenge. Existing approaches often rely on a single model or fixed tool-calling logic, failing to exploit the performance variations across heterogeneous model-tool pairs. In this paper, we present ATLAS (Adaptive Tool-LLM Alignment and Synergistic Invocation), a dual-path framework for dynamic tool usage in cross-domain complex reasoning. ATLAS operates via a dual-path approach: (1) training-free cluster-based routing that exploits empirical priors for domain-specific alignment, and (2) RL-based multi-step routing that explores autonomous trajectories for out-of-distribution generalization. Extensive experiments across 15 benchmarks demonstrate that our method outperforms closed-source models like GPT-4o, surpassing existing routing methods on both in-distribution (+10.1%) and out-of-distribution (+13.1%) tasks. Furthermore, our framework shows significant gains in visual reasoning by orchestrating specialized multi-modal tools.
One-sentence Summary
The authors from Tsinghua University and Zhejiang University propose ATLAS, a dual-path framework for adaptive tool-LLM alignment that combines training-free cluster-based routing with RL-based multi-step optimization, enabling dynamic, high-performance tool selection across diverse domains and outperforming GPT-4o on in- and out-of-distribution reasoning tasks, including visual reasoning through specialized multi-modal tools.
Key Contributions
- The paper addresses the challenge of dynamically selecting optimal model-tool combinations in complex, cross-domain reasoning tasks, where existing methods fail to leverage synergies between diverse large language models (LLMs) and external tools due to rigid, fixed invocation logic or isolated optimization.
- It introduces ATLAS, a dual-path framework that combines training-free cluster-based routing—using empirical domain priors for efficient, in-distribution alignment—with RL-driven multi-step routing that enables autonomous exploration and out-of-distribution generalization.
- Evaluated on 15 benchmarks, ATLAS surpasses both closed-source models like GPT-4o and state-of-the-art routing methods by +10.1% on in-distribution and +13.1% on out-of-distribution tasks, with notable improvements in visual reasoning through coordinated multi-modal tool usage.
Introduction
The integration of large language models (LLMs) with external tools has enabled more capable AI agents, but as model and tool diversity grows, selecting optimal model-tool combinations becomes a high-dimensional challenge. Prior approaches either fix tool invocation logic or route models in isolation, failing to exploit synergies between heterogeneous models and tools, and lacking adaptability in open-domain or out-of-distribution settings. The authors introduce ATLAS, a dual-path framework that dynamically orchestrates model-tool pairs by combining training-free cluster-based routing—leveraging domain-specific performance priors for efficient, in-distribution decisions—with RL-driven multi-step routing that explores optimal trajectories for generalization. This unified approach enables adaptive, scalable coordination across diverse tasks, outperforming closed-source models like GPT-4o and existing routing methods by up to 13.1% on out-of-distribution benchmarks, while also showing strong gains in visual reasoning through multi-modal tool integration.
Dataset

- The dataset comprises multiple benchmark tasks spanning mathematical, arithmetic, code generation, commonsense, logical, scientific, and multi-modal reasoning, as detailed in Table 4.
- AIME 2024 and 2025 (MAA, 2024, 2025) each contain 30 advanced math problems requiring high-level problem-solving and computation, targeting elite high school-level reasoning.
- AMC (Lightman et al., 2023) includes 40 multiple-choice problems assessing foundational mathematical reasoning and computational skills.
- Calculator (Wu et al., 2025b) consists of 1,000 complex arithmetic problems that evaluate a model’s ability to recognize when to invoke external tools and correctly interpret computational outputs.
- HumanEval (Chen, 2021) features 164 hand-crafted programming problems with function signatures, docstrings, and unit tests, testing precise code synthesis from natural language.
- MBPP (Austin et al., 2021) contains 974 crowd-sourced Python problems for entry-level programmers, requiring short, functionally correct code snippets involving basic constructs like loops and conditionals.
- Natural Questions (NQ) (Kwiatkowski et al., 2019) includes real user queries from Google Search paired with Wikipedia articles, assessing knowledge-intensive information retrieval and synthesis.
- Web Questions (WebQ) (Berant et al., 2013) provides 1,000 factual questions derived from web search queries, testing reasoning over external knowledge bases.
- LogiQA2 (Liu et al., 2023) contains 1,572 multiple-choice logical reasoning problems from standardized exams, evaluating deductive, inductive, and abductive reasoning.
- GPQA (Rein et al., 2024) features 448 expert-written multiple-choice questions in biology, physics, and chemistry, designed to challenge PhD-level domain knowledge and deep understanding.
- ChartQA (Masry et al., 2022) includes questions about bar charts, line graphs, and pie charts, testing numerical reasoning from visual data.
- Geometry3K (Lu et al., 2021) provides 3,000 geometry problems with diagram annotations, assessing visual-geometric reasoning and application of mathematical principles.
- TallyQA (Acharya et al., 2019) contains complex counting questions across real-world images, requiring spatial reasoning and selective attention.
- CountBench (Paiss et al., 2023) focuses on precise object enumeration in cluttered, occluded, or similar-object scenarios, emphasizing robust visual counting.
- TableVQA (Kim et al., 2024) includes questions about tables across domains, testing comprehension of structure, extraction of relevant data, and reasoning over tabular content.
- The authors use these datasets to construct a training mixture with balanced ratios across domains, ensuring diverse reasoning capabilities are covered.
- During training, the model is exposed to a multi-step routing process where it dynamically selects between reasoning, tool use, or direct response based on task type.
- Each dataset is processed to extract task-specific metadata, including problem type, required reasoning mode, and tool dependency.
- For visual datasets, images are preprocessed to ensure consistent resolution and format, and question-answer pairs are aligned with diagram or table context.
- The framework uses a policy-driven routing mechanism (Algorithm 2) to guide the model through reasoning steps, tool invocation, and final answer parsing, with trajectory tracking for training feedback.
Method
The ATLAS framework employs a two-tiered architecture to address diverse query complexity, combining a training-free cluster-based routing mechanism for low-latency decisions with an RL-driven multi-step routing strategy for complex, iterative tasks. The overall system operates within a hybrid reasoning engine that orchestrates a pool of large language models (LLMs) and external tools, adapting its approach based on the query's domain and required reasoning depth.
The first tier, training-free cluster-based routing, enables rapid, real-time decision-making. This method leverages historical query data to pre-compute a semantic clustering of the query space. At training time, queries are projected into a latent manifold using a pre-trained encoder, and the embedding space is partitioned into K disjoint clusters by minimizing the inertia, as defined by the equation:
{μk}k=1Kmink=1∑Kvi∈Ck∑∥vi−μk∥2,where μk is the centroid of cluster Ck. For each cluster and every possible model-tool pair (m,t), empirical statistics are derived, including the success rate (accuracy) and operational cost. The cost is computed based on average token throughput and unit prices for input and output tokens. A cluster-level utility score, Uk(m,t), is then defined to balance performance and cost:
Uk(m,t)=(1−α)⋅Acck(m,t)−α⋅Costk(m,t).At inference, a new query is embedded and assigned to the nearest cluster centroid. The optimal model-tool pair is selected by maximizing the utility score within that cluster. This process is illustrated in the framework diagram, which shows the query being embedded, clustered, and then routed to the best-performing combination from the routing pool.
The second tier, RL-driven multi-step routing, is designed for complex tasks requiring iterative reasoning and dynamic tool invocation. This strategy models the routing process as a sequential decision-making task, where an agent, guided by a policy πθ, maintains an evolving state that includes the query and accumulated context. The agent's action space consists of two types: internal reasoning (think), which involves local chain-of-thought processing, and dynamic routing (route), which selects a model-tool pair from the routing pool to gather external information. This iterative loop continues until a final answer is produced or a maximum step limit is reached. The policy is trained using Proximal Policy Optimization (PPO) to maximize a composite reward function that balances structured execution, task correctness, and routing efficiency. The reward function is defined as:
rϕ=Rfmt+γRout+ξRsel,where Rfmt enforces syntactic rules, Rout provides a binary signal for task correctness, and Rsel penalizes the selection of sub-optimal models. The training process is depicted in the diagram, showing the policy LLM interacting with the environment through a series of think and route actions, with the reward signal feeding back into the PPO update mechanism.

Experiment
- ATLAS(cluster) achieves 63.5% average accuracy on in-distribution tasks, surpassing RouterDC by 10.1% and outperforming GPT-4o (53.1%) on AIME25 (40.0% vs. 53.1%) and AMC (82.5% vs. 63.0%), demonstrating strong task-configuration alignment via semantic clustering and empirical priors.
- ATLAS(RL) maintains 59.4% average accuracy in out-of-distribution settings, 10.2% higher than ATLAS(cluster) (49.2%) and 13.1% higher than RouterDC (46.3%), with 43.3% and 33.3% accuracy on AIME24 and AIME25 respectively, indicating superior generalization through transferable routing policies.
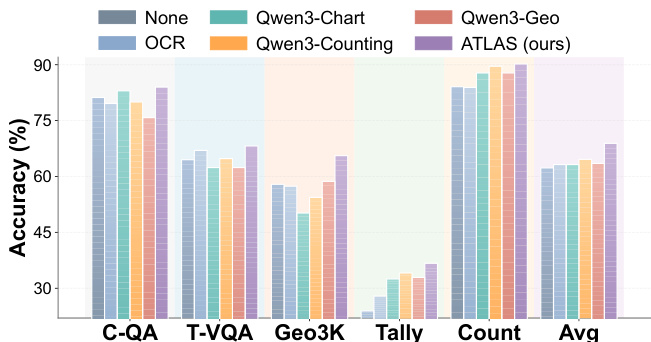
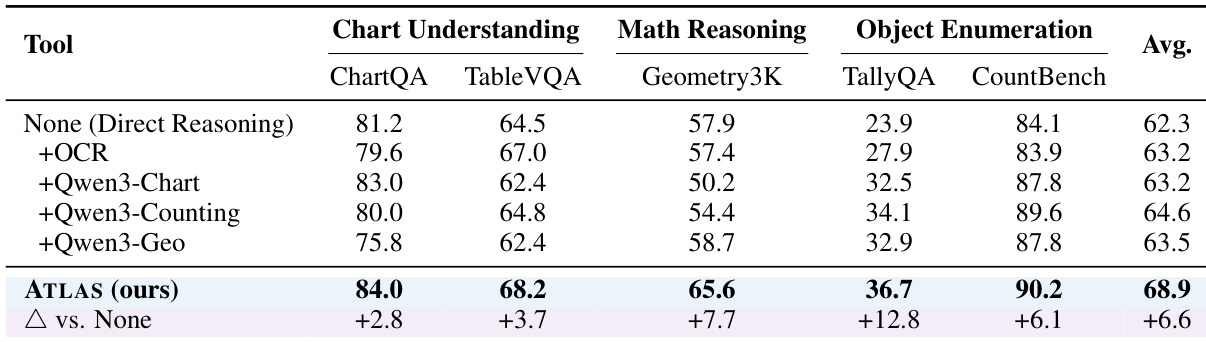
- On multi-modal tasks, ATLAS achieves 68.9% average accuracy, outperforming the strongest single-tool baseline by 4.3%, and surpasses individual tools across all categories, including 83.0% on ChartQA and 50.2% on Geometry3K, validating dynamic tool orchestration.
- With dynamic model-tool pool extensions (adding medical, math, and verification tools), ATLAS(RL) improves from 59.4% to 61.7% accuracy, with gains of +6.7% on AIME24 and AIME25, while baselines show limited or degraded performance, confirming robust adaptability without retraining.
- ATLAS(RL) achieves 59.4% pass@1 accuracy, a +23.0% improvement over zero-shot routing (36.4%), and reaches 63.1% at pass@16, indicating near-optimal reasoning capacity and efficient exploration, with faster reward convergence and lower entropy in training dynamics.
- RL training enables task-adaptive API call patterns: high call counts on complex tasks (AIME25, GPQA) and minimal calls on simple retrieval tasks (WebQ, NQ), balancing performance and inference cost effectively.
The authors use ATLAS to evaluate multi-modal tool orchestration across five visual reasoning datasets, demonstrating that dynamic routing outperforms single-tool baselines. Results show ATLAS achieves the highest average accuracy of 68.9%, surpassing the best single tool by 4.3% and outperforming all individual tools in each task category.
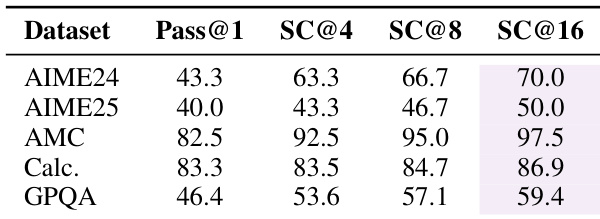
Results show that ATLAS(RL) achieves strong reasoning performance across diverse benchmarks, with Pass@1 accuracy improving significantly as self-consistency sampling increases, reaching 70.0% on AIME24 at SC@16. The framework demonstrates near-optimal reasoning capacity, with performance gains persisting across all tasks even at high sample counts, indicating efficient exploration and convergence to high-quality solutions.
The authors use ATLAS (cluster) to achieve 63.5% average accuracy in the in-distribution setting, surpassing the strongest baseline RouterDC by 10.1% and outperforming GPT-4o on several tasks. In the out-of-distribution setting, ATLAS (RL) maintains a higher average accuracy of 59.4% compared to ATLAS (cluster) at 49.2%, demonstrating its superior generalization capability.
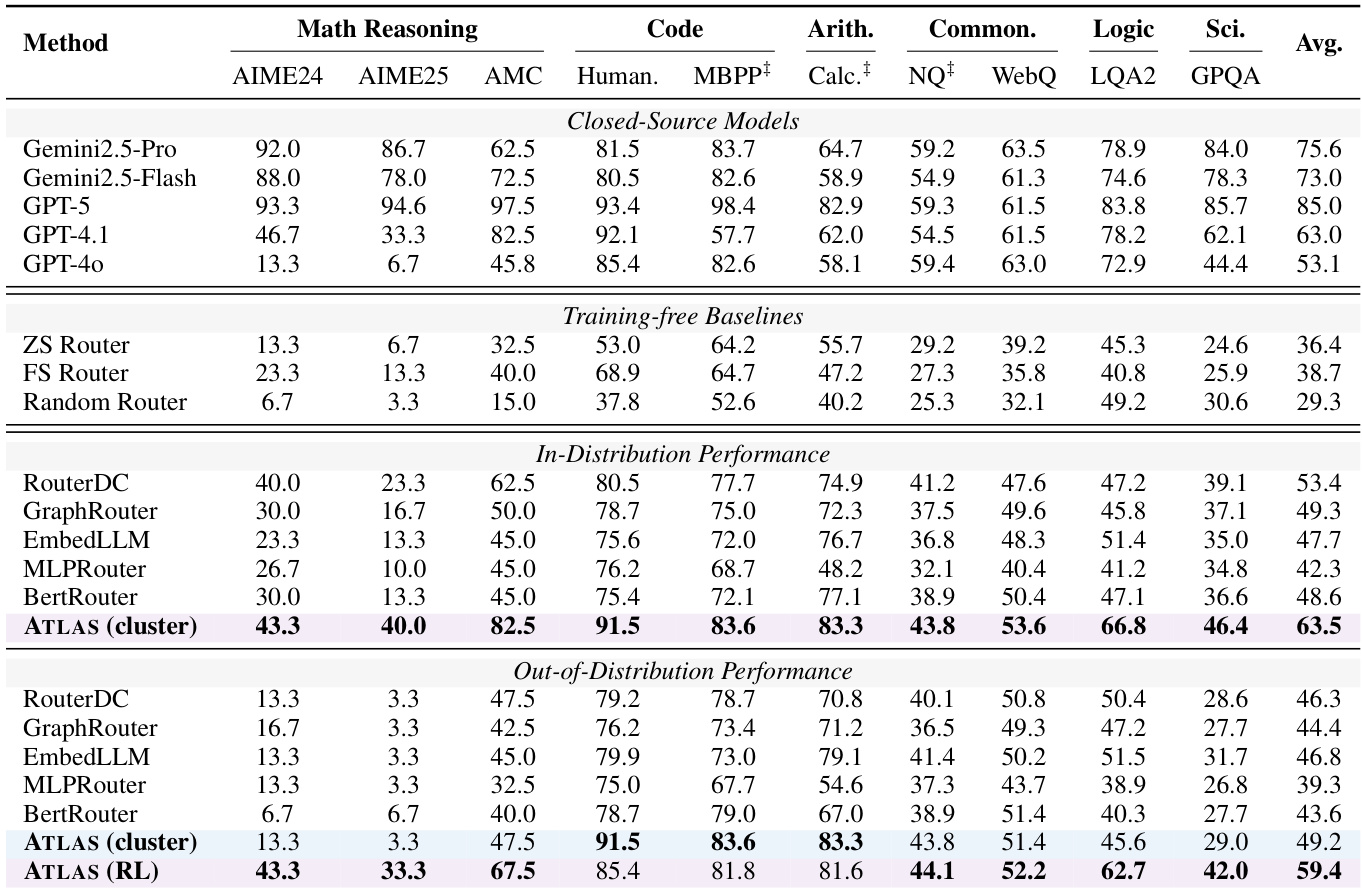
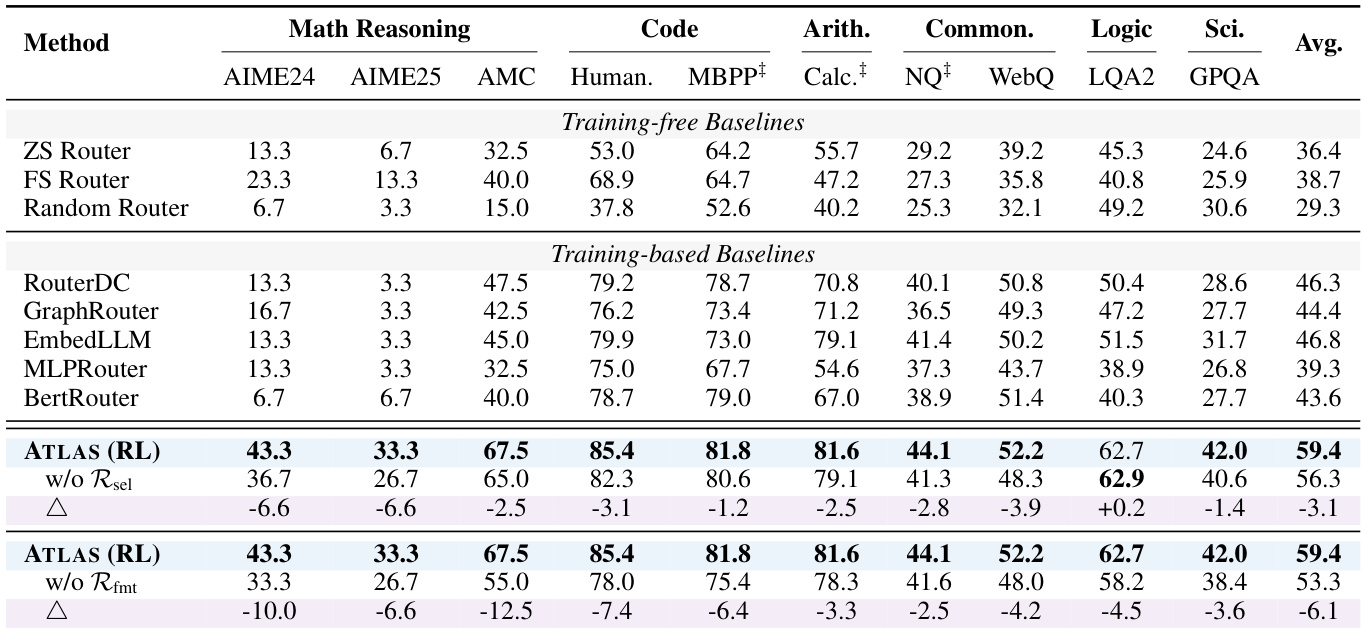
Results show that ATLAS (RL) achieves the highest average accuracy of 59.4% across all tasks, significantly outperforming all training-free and training-based baselines. The ablation studies indicate that both the selection reward and format reward are critical for optimal performance, with their removal leading to substantial drops in accuracy, particularly on mathematical and code generation tasks.
The authors use ATLAS to dynamically route queries among multiple tools and models for multi-modal reasoning tasks, achieving the highest accuracy across all benchmarks compared to single-tool baselines. Results show that ATLAS consistently outperforms individual tools in each task category, demonstrating the effectiveness of adaptive model-tool orchestration in integrating internal reasoning with external tool augmentation.