Command Palette
Search for a command to run...
Reinforcement Learning via Self-Distillation
Reinforcement Learning via Self-Distillation
Abstract
Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
One-sentence Summary
Researchers from ETH Zurich, Max Planck, MIT, and Stanford propose SDPO, a self-distillation method that turns rich textual feedback into dense training signals for LLMs, improving sample efficiency and accuracy in code and math tasks by enabling models to learn from their own in-context error analysis without external teachers.
Key Contributions
- SDPO introduces a novel reinforcement learning framework for verifiable domains that leverages rich textual feedback—like runtime errors or judge comments—to overcome the credit-assignment bottleneck of scalar reward-only methods, formalizing this as Reinforcement Learning with Rich Feedback (RLRF).
- The method uses the current model as a self-teacher: after receiving feedback, it re-evaluates its own rollout token-by-token and distills its feedback-conditioned next-token predictions back into the policy, enabling dense, logit-level learning without external teachers or reward models.
- Evaluated on LiveCodeBench v6 across scientific reasoning, tool use, and competitive programming, SDPO improves sample efficiency and final accuracy over RLVR baselines, and even boosts performance in scalar-reward settings by repurposing successful rollouts as implicit feedback, while also reducing test-time attempts by 3× compared to best-of-k sampling.
Introduction
The authors leverage reinforcement learning with rich feedback—where environments provide tokenized explanations like runtime errors or judge comments—to overcome the credit assignment bottleneck of scalar reward methods like GRPO. Prior approaches either rely on sparse rewards or require external teachers for dense supervision, limiting scalability and practicality in online learning. Their main contribution is Self-Distillation Policy Optimization (SDPO), which uses the model itself as a self-teacher: after receiving feedback, it re-evaluates its own rollout in-context and distills corrected next-token predictions back into the policy. This enables dense, logit-level credit assignment without external supervision, improving sample efficiency and final accuracy across reasoning and coding tasks—even in scalar-reward settings—while being implementable as a drop-in replacement in existing RLVR pipelines.
Method
The authors leverage a self-distillation framework, Self-Distillation Policy Optimization (SDPO), which repurposes the same policy model to serve dual roles: as a student generating initial responses and as a self-teacher that retrospectively evaluates those responses using rich feedback. This architecture enables dense, token-level credit assignment by comparing the student’s per-token probability distribution against the teacher’s distribution, conditioned on both the original question and the feedback received.
The core mechanism begins with sampling a question x and generating a rollout y∼πθ(⋅∣x) from the student policy. The environment then provides feedback f, which may include runtime errors, sample solutions from prior rollouts, or task-specific instructions. The self-teacher, defined as πθ(⋅∣x,f), is prompted with the same question augmented by this feedback, allowing it to reassess the student’s output with additional context. As shown in the framework diagram, this creates a closed-loop training signal where the teacher’s evaluation guides the student’s parameter updates.

The training objective minimizes the KL-divergence between the student’s next-token distribution and the teacher’s distribution at each timestep t, with the teacher’s parameters detached from the gradient computation to prevent degeneration. The loss is formulated as:
LSDPO(θ):=t∑KL(πθ(⋅∣x,y<t)∣∣stopgrad(πθ(⋅∣x,f,y<t)))This gradient is derived via the score function estimator and corresponds to a logit-level policy gradient where the advantage for each token y^t is given by logπθ(y^t∣x,f,y<t)πθ(y^t∣x,y<t). Positive advantages indicate tokens the teacher deems more likely than the student, while negative advantages flag tokens where the student overconfidently diverged from the teacher’s refined judgment.
To manage computational cost, the authors approximate the full KL divergence by restricting distillation to the top-K tokens predicted by the student at each position, appending a tail term to account for the remaining probability mass. This reduces memory overhead without sacrificing performance, as most vocabulary tokens are irrelevant at any given timestep.
Training stability is enhanced through two key modifications. First, the self-teacher is regularized either via an exponential moving average (EMA) of the student’s parameters or by interpolating the current teacher with an initial reference teacher, effectively enforcing a trust region in distribution space. Second, the symmetric Jensen-Shannon divergence is adopted for the distillation loss, which has been shown to improve convergence in similar distillation settings.
The SDPO gradient can be extended to off-policy data using PPO-style clipped importance sampling, where the per-token advantage is weighted by the ratio of old and new policy probabilities. This generalization allows SDPO to leverage experience replay while maintaining the dense, feedback-driven credit assignment that distinguishes it from scalar-reward methods like GRPO.
As illustrated in the training pipeline, SDPO iteratively refines the policy: each rollout generates feedback, which is used to compute teacher log-probabilities, and the resulting per-token advantages drive the parameter update. This process repeats, with the teacher improving alongside the student, enabling the model to progressively internalize the feedback signal and correct its own errors at a granular level.

Experiment
- SDPO outperforms GRPO in reasoning and coding tasks, achieving higher accuracy with significantly shorter response lengths, indicating more efficient reasoning.
- In environments without rich feedback, SDPO uses successful attempts within a batch as implicit feedback, enabling faster learning and up to 10× speedup in training time on some tasks.
- With rich feedback (e.g., coding environments), SDPO leverages dense credit assignment to improve final accuracy and reaches GRPO’s performance in 4× fewer generations, with gains amplifying as model scale increases.
- SDPO enables test-time self-distillation, accelerating solution discovery for hard binary-reward questions by 3× compared to sampling or multi-turn baselines, even when initial success rates are near zero.
- The self-teacher in SDPO improves during training, allowing bootstrapping from weak to strong performance, and regularization stabilizes learning without freezing the teacher.
- SDPO avoids catastrophic forgetting better than off-policy baselines, maintaining prior capabilities while learning new tasks.
- SDPO’s efficiency stems from sparse, token-level credit assignment that eliminates verbose, circular reasoning patterns common in GRPO.
- Performance is tightly coupled with model scale—stronger models enable more accurate retrospection, making SDPO’s gains emergent with scale.
- Environment feedback and sample solutions are complementary; excluding the student’s original attempt during reprompting improves exploration and diversity.
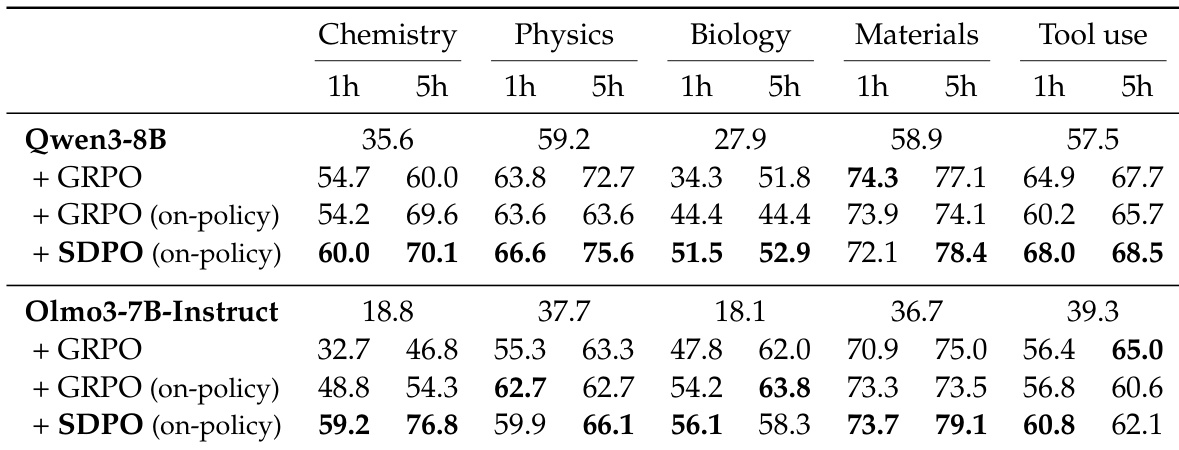
The authors use SDPO to train models on reasoning tasks without rich environment feedback, treating successful attempts within a batch as feedback for failed ones. Results show SDPO consistently outperforms GRPO across subjects and model sizes, achieving higher accuracy in less time—sometimes matching GRPO’s 5-hour performance in under an hour—and producing significantly shorter, more efficient responses. This improvement holds even when both methods use on-policy training, suggesting SDPO’s self-distillation mechanism enhances learning efficiency without requiring off-policy updates.
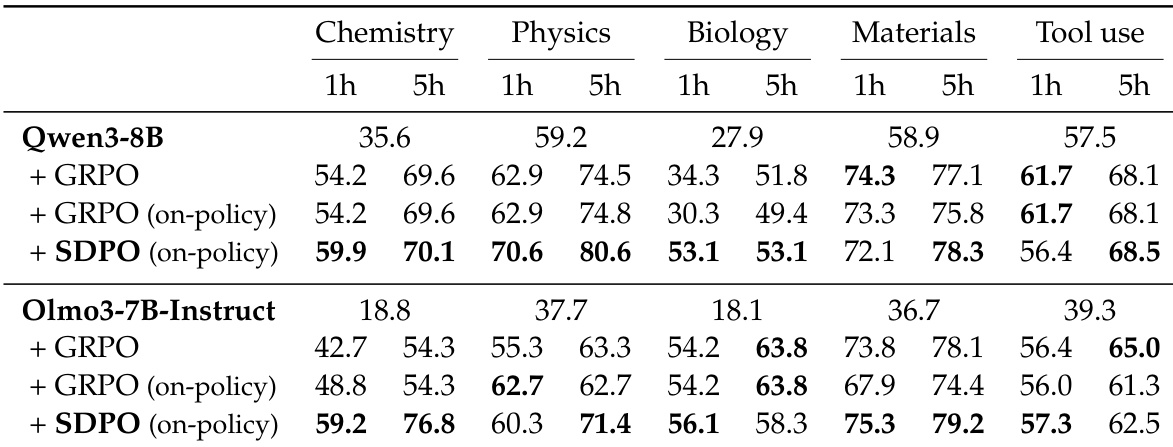
The authors use SDPO to train models on reasoning tasks without rich environment feedback, treating successful attempts within a batch as feedback for failed ones. Results show SDPO consistently outperforms GRPO across subjects and model sizes, achieving higher accuracy in less time and with significantly shorter response lengths, indicating more efficient reasoning. This improvement is especially pronounced on Chemistry, where SDPO reaches GRPO’s 5-hour performance in under an hour.
The authors use SDPO to significantly reduce response lengths compared to GRPO while maintaining or improving accuracy, with both Qwen3-8B and Olmo3-7B-Instruct showing a consistent 3.2× reduction in generation length. This efficiency gain reflects SDPO’s ability to produce concise, non-repetitive reasoning by leveraging dense token-level credit assignment rather than relying on verbose exploration. Results confirm that effective reasoning does not require longer outputs, and SDPO’s self-teaching mechanism enables more focused, accurate generation.

The authors use SDPO to improve performance on coding tasks with rich feedback, achieving higher final accuracy than GRPO and other baselines. Results show SDPO not only reaches GRPO’s final accuracy in fewer generations but also scales more effectively with larger models, indicating that self-teaching becomes more powerful as the base model’s in-context learning ability improves.

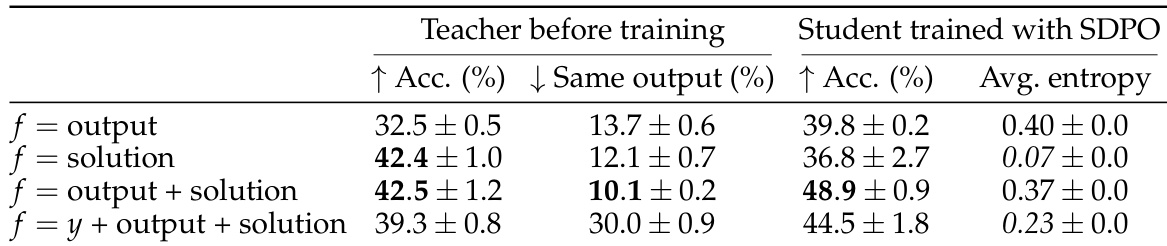
The authors use SDPO to evaluate how different types of feedback influence self-teaching during training, finding that combining environment output and sample solutions yields the highest student accuracy and lowest entropy. Results show that while initial teacher performance varies by feedback type, the student consistently improves beyond the teacher’s starting level, with the most effective feedback enabling the strongest gains. The self-teacher’s ability to refine its own outputs during training supports iterative policy improvement even when initial accuracy is low.