Command Palette
Search for a command to run...
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Abstract
We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
One-sentence Summary
The StepFun Team introduces Step 3.5 Flash, a 196B MoE model using 11B active parameters with Sliding Window/Full Attention and MTP-3 for efficient agentic reasoning, achieving frontier performance across math, code, and tool tasks while enabling scalable industrial deployment.
Key Contributions
- Step 3.5 Flash introduces a sparse Mixture-of-Experts architecture with 196B total parameters but only 11B active per forward pass, optimized via hybrid 3:1 Sliding Window/Full Attention and Multi-Token Prediction to reduce latency in multi-round agentic interactions.
- The model employs a scalable reinforcement learning framework integrating verifiable signals and preference feedback, ensuring stable off-policy training that drives self-improvement across math, code, and tool-use tasks.
- Evaluated on multiple benchmarks including IMO-AnswerBench (85.4%), LiveCodeBench-v6 (86.4%), and Terminal-Bench 2.0 (51.0%), Step 3.5 Flash matches frontier models like GPT-5.2 xHigh and Gemini 3.0 Pro while enabling efficient industrial deployment.
Introduction
The authors leverage a sparse Mixture-of-Experts (MoE) architecture with only 11B active parameters out of 196B total to deliver frontier-level agentic intelligence while maintaining low inference latency and cost—critical for real-world agent deployment. Prior RL methods for large language models suffer from instability due to high gradient variance, off-policy misalignment, and infrastructure mismatches between training and inference. Their main contribution is a scalable RL framework that integrates verifiable signals and preference feedback, stabilized via MIS-Filtered Policy Optimization (MIS-PO), enabling consistent self-improvement across math, code, and tool use tasks while matching top closed models like GPT-5.2 xHigh and Gemini 3.0 Pro in performance.
Dataset
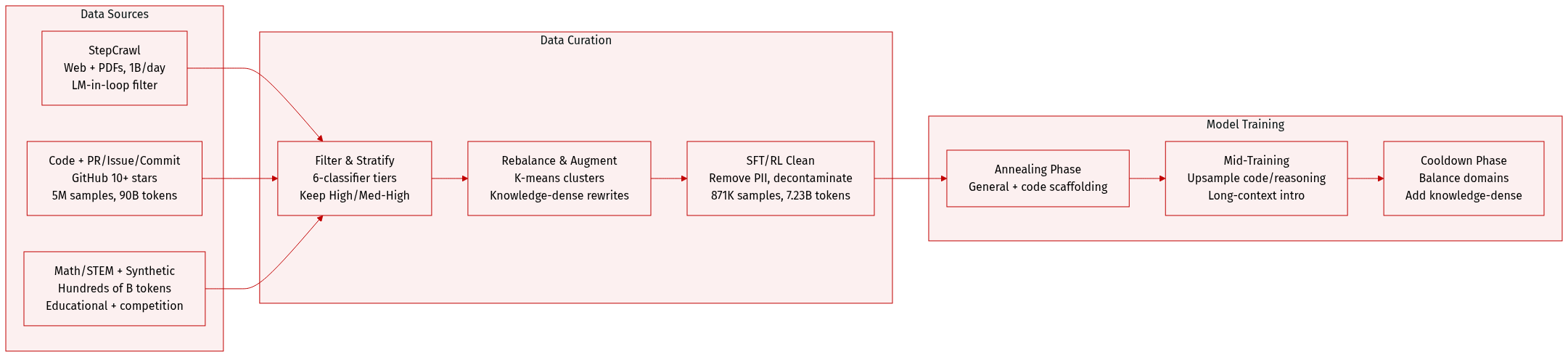
The authors use a highly curated, multi-source training corpus designed to support agentic reasoning, coding, and general knowledge. Below is a concise breakdown:
-
Dataset Composition & Sources
The corpus blends general open-domain data (via StepCrawl), code data (modified OpenCoder pipeline), PR/Issue/Commit data (GitHub repos with 10+ stars), and synthetic/semi-synthetic tool-use and reasoning data. Additional STEM/math data is harvested via StepCrawl and augmented with educational content. -
Key Subset Details
- StepCrawl: In-house crawler harvesting HTML, ePub, PDFs; filters via LM-in-the-loop scoring, deduplication, and sanitization. Processes ~1B pages/day.
- Code Data: Accepts documents with 0–6 heuristic violations (vs. strict zero-tolerance), upsampling during mid-training.
- PR/Issue/Commit Data: 5M samples from GitHub; includes Base (deduplicated vs. SWE-Bench), PR-Dialogue (90B tokens via Agentless templates), Rewritten Reasoning (12B tokens), and Environment-based Seed Data (executable test patches).
- Math/STEM: Hundreds of billions of tokens via StepCrawl + 100M educational samples; filtered via MegaMath-style ensemble + FineMath.
- SFT Data: 871K samples (7.23B tokens) after rule-based + model-based filtering, decontamination, and domain-specific refinement.
- RL Data: Aggregates competition problems (pre-2024), synthetic arithmetic, and reasoning environments; filtered for uniqueness and difficulty.
-
Training Use & Mixture
Data is mixed across phases:- Annealing: Emphasizes general knowledge + code scaffolding.
- Mid-training: Upsamples code, PR-Dialogue, and reasoning data; introduces long-context samples.
- Cooldown: Balances domain sampling probabilities; integrates knowledge-dense augmented samples.
Mixture ratios are tuned via ablations to optimize benchmark performance.
-
Processing & Metadata
- Quality stratification: Documents scored by 6 lightweight classifiers; retain High/Medium-High tiers.
- Embedding rebalancing: K-means clustering (100k+ clusters) to down-sample overrepresented topics.
- Knowledge augmentation: Two-stage pipeline retrieves and transforms high-density passages.
- Metadata: Domain tags, hit counts (code), and execution flags (code/STEM) guide sampling.
- Infrastructure: Runs on hybrid CPU/GPU clusters with Spark/Ray, backed by OSS/HDFS/JuiceFS storage.
- SFT/RL filtering: Removes PII, harmful content, inconsistent language, and decontaminates via n-gram/digit-masked matching.
Method
The authors leverage a co-designed architecture for Step 3.5 Flash that explicitly optimizes for low wall-clock latency in agentic workflows, balancing long-context prefilling with multi-turn interactive decoding. The model’s core design integrates three key innovations: a hybrid attention mechanism, sparse Mixture-of-Experts (MoE) with expert-parallel load balancing, and multi-token prediction (MTP) heads for speculative decoding.
The backbone consists of a 45-layer sparse-MoE Transformer, with the first three layers using dense feed-forward networks (FFNs) and the remaining 42 layers employing MoE FFNs. Each MoE layer activates 8 out of 288 routed experts per token, plus one shared expert, maintaining a total capacity of 196B parameters while limiting per-token activation to 11B. This configuration ensures high knowledge capacity without compromising inference speed. To mitigate straggler effects in distributed deployments, the authors introduce an EP-Group Balanced MoE Routing strategy that explicitly promotes uniform utilization across expert-parallel ranks, defined by a loss function that penalizes imbalanced expert group activation frequencies.
Attention is structured as a hybrid layout, interleaving three Sliding Window Attention (SWA) layers with one Full Attention layer in a 3:1 ratio (S3F1), repeated across the stack. This layout balances long-context efficiency with robust long-range connectivity. To compensate for performance degradation inherent in naive SWA, the authors augment the SWA query-head count from 64 to 96 and integrate head-wise gated attention. The gating mechanism, applied per attention head, dynamically modulates information flow by computing an input-dependent scalar gate, effectively introducing a data-dependent sink token into the attention mechanism. This approach preserves standard attention semantics while improving performance without adding significant FLOPs or latency.
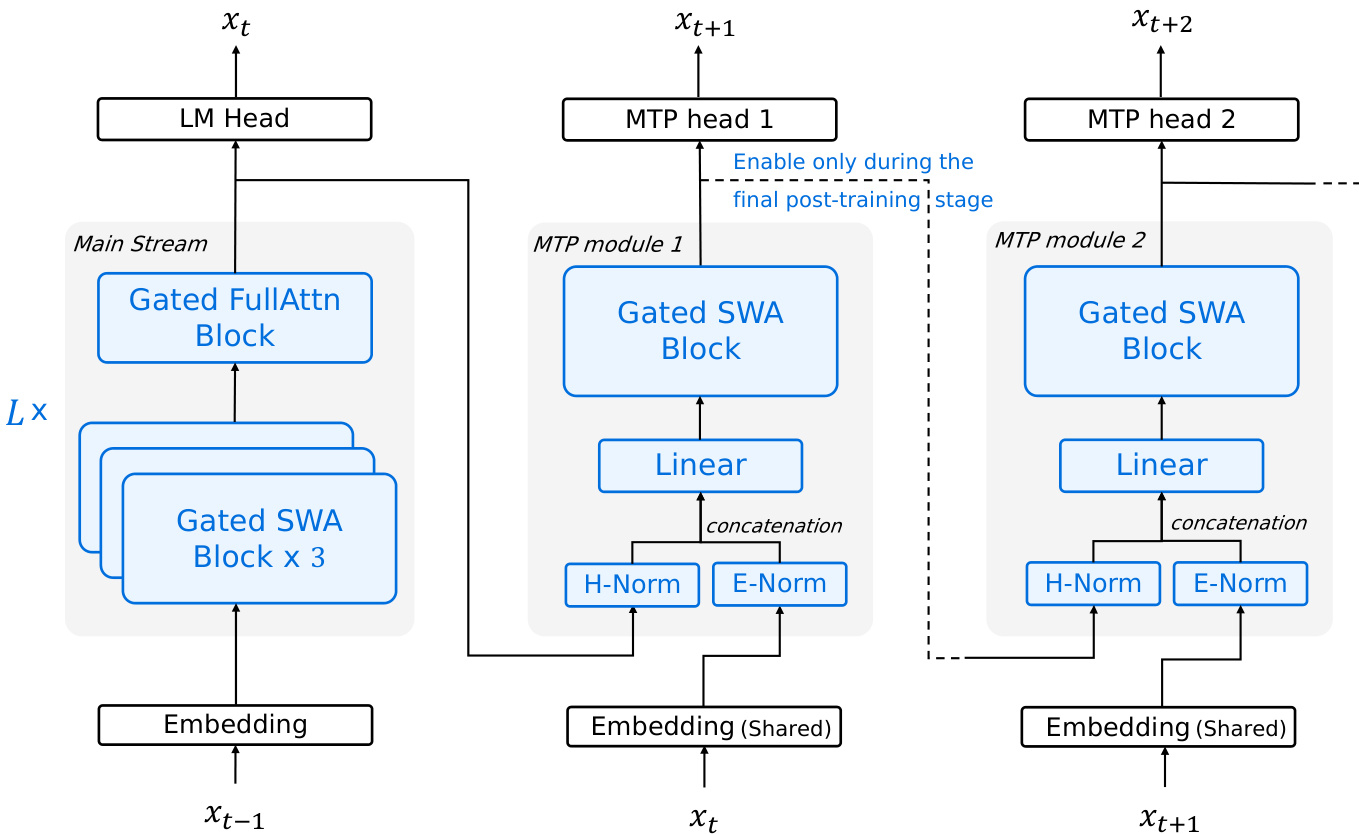
As shown in the figure below, the model also incorporates three lightweight MTP heads, each predicting tokens at offsets xt+2, xt+3, and xt+4 conditioned on the backbone’s hidden states at position t. Each MTP head consists of a gated SWA block followed by a linear layer and normalization modules, sharing embeddings with the main stream. To control training overhead, only MTP-1 is trained during the main pre-training phase; MTP-2 and MTP-3 are cloned from MTP-1 and jointly fine-tuned in a lightweight final post-training stage. This modular design enables aggressive multi-token speculation without proportional latency penalties, particularly beneficial for bandwidth-bound hardware.
The model is constrained to under 200B parameters to fit within the 128GB memory budget of high-end workstations. Training is orchestrated via the Steptron framework, which supports hybrid parallelism including 8-way pipeline parallelism, 8-way expert parallelism, and ZeRO-1 data parallelism. Key engineering optimizations include decoupled parallelization for attention and MoE modules, fabric-aware communication scheduling, and Muon ZeRO-1 resharding to reduce communication overhead. Kernel-level optimizations fuse operators in attention and MoE layers, while fine-grained selective checkpointing reduces peak memory by recomputing only the most memory-intensive components.
Training proceeds through a multi-stage curriculum: initial open-domain pre-training at 4k context, followed by annealing toward code and reasoning-dense data while extending context to 32k, then a mid-training phase expanding context to 128k. Post-training employs a unified SFT pipeline followed by domain-specific RL using MIS-Filtered Policy Optimization (MIS-PO), which stabilizes training by filtering off-distribution samples at both token and trajectory levels. The reward system decouples verifiable and non-verifiable tasks, using rule-based and model-based verifiers for STEM and a generative reward model (GenRM) for preference-based tasks, augmented with MetaRM to penalize spurious reasoning.
Experiment
- Hybrid attention layouts show a clear cost-quality trade-off: S3F1 offers the lowest FLOPs but degrades performance; adding SWA query heads (S3F1+Head) recovers most quality with minimal cost increase and becomes the default for long-context workloads.
- Head-wise gated attention consistently outperforms sink tokens in pretraining at scale, improving average benchmark scores and adopted as the default mechanism.
- Training stability is maintained via a diagnostic stack that surfaces and mitigates three key issues: numerical blow-ups, dead experts, and localized activation explosions—particularly in deep MoE layers—where activation clipping proves more effective than weight clipping.
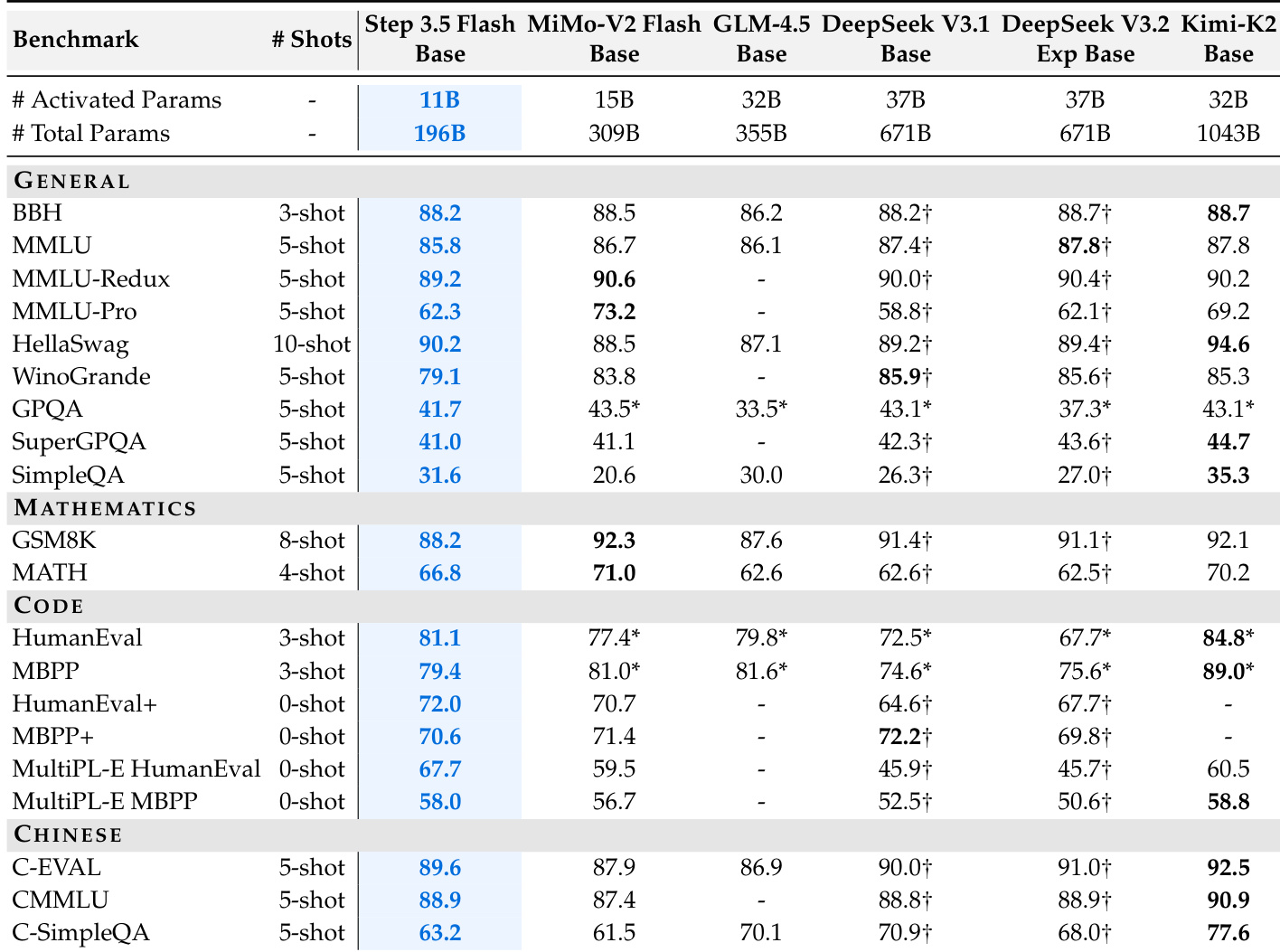
- Despite activating only 11B parameters, Step 3.5 Flash achieves competitive or superior performance across reasoning, math, coding, and Chinese benchmarks compared to much larger models, demonstrating strong capability density.
- Post-training evaluations show strong performance on agentic tasks (e.g., SWE-Bench, Terminal-Bench, GAIA, τ²-Bench), rivaling frontier models like GPT-5.2 and Gemini 3.0 Pro, especially in tool use and long-horizon decision-making.
- RL training with MIS-PO outperforms GSPO in sample efficiency and stability for both dense and MoE models, enabling scalable off-policy training with controlled training-inference mismatch.
- The model excels at leveraging external tools, showing the highest tool-usage gain across benchmarks like GAIA and xbench-DeepSearch, indicating strong retrieval and reasoning integration.
- Context management strategies (e.g., Discard-all, Multi-agent) significantly impact performance on deep search tasks, with multi-agent orchestration yielding the best results by decomposing and parallelizing reasoning.
- In real-world advisory scenarios, Step 3.5 Flash matches Gemini 3.0 Pro in overall score while outperforming in logic and hallucination reduction, making it suitable for high-stakes consulting.
- Edge-cloud collaboration (Step 3.5 Flash + Step-GUI) significantly improves task success on mobile GUI benchmarks compared to edge-only execution, validating the efficacy of distributed agent architectures.
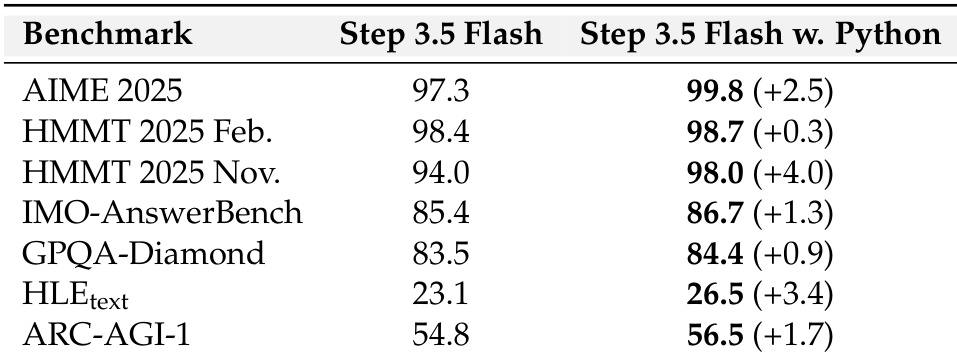
The authors evaluate Step 3.5 Flash with and without Python execution capability across multiple reasoning and agentic benchmarks. Results show that enabling Python execution consistently improves performance, with gains ranging from +0.3 to +4.0 points, indicating that tool integration enhances the model’s ability to solve complex, computation-intensive tasks. The largest improvements occur on math and code-related benchmarks, underscoring the value of external tool use in augmenting reasoning capacity.
Step 3.5 Flash achieves competitive performance on the Consulting and Recommendations Benchmark, scoring 39.6% and matching Gemini 3.0 Pro’s level while operating at lower inference cost. The model outperforms DeepSeek V3.2 and trails slightly behind Claude Opus 4.5 and GPT-5.2, reflecting its strong balance of reasoning quality and efficiency in real-world advisory tasks.

Step 3.5 Flash achieves competitive performance across general, mathematical, coding, and Chinese benchmarks despite activating only 11B parameters out of 196B total, demonstrating strong capability density. The model matches or exceeds larger sparse baselines on key metrics like BBH and SimpleQA, highlighting its efficiency in delivering high performance per parameter. Results confirm that its architecture enables robust reasoning and coding abilities while maintaining a favorable cost-quality trade-off.
The authors evaluate different attention layouts and head configurations in their model, finding that increasing SWA query heads in the S3F1 layout significantly improves performance across multiple benchmarks while maintaining efficiency. Results show that the S3F1+Head variant outperforms the full-attention baseline on several key metrics, including MMLU and SimpleQA, and achieves the highest average pre-training score. This configuration strikes the best balance between computational cost and model quality, making it the preferred choice for long-context workloads.

The authors evaluate attention efficiency in Step 3.5 Flash under varying SWA head counts and gating strategies, finding that increasing SWA heads slightly raises FLOPs but has minimal latency impact due to IO-bound behavior. Head-wise gating introduces negligible overhead compared to no gating, confirming its lightweight nature. Overall, the S3F1 layout with head-wise gating and 96 SWA heads offers the best balance of efficiency and performance for long-context workloads.