Command Palette
Search for a command to run...
PhyCritic: Multimodal Critic Models for Physical AI
PhyCritic: Multimodal Critic Models for Physical AI
Tianyi Xiong Shihao Wang Guilin Liu Yi Dong Ming Li Heng Huang Jan Kautz Zhiding Yu
Abstract
With the rapid development of large multimodal models, reliable judge and critic models have become essential for open-ended evaluation and preference alignment, providing pairwise preferences, numerical scores, and explanatory justifications for assessing model-generated responses. However, existing critics are primarily trained in general visual domains such as captioning or image question answering, leaving physical AI tasks involving perception, causal reasoning, and planning largely underexplored. We introduce PhyCritic, a multimodal critic model optimized for physical AI through a two-stage RLVR pipeline: a physical skill warmup stage that enhances physically oriented perception and reasoning, followed by self-referential critic finetuning, where the critic generates its own prediction as an internal reference before judging candidate responses, improving judgment stability and physical correctness. Across both physical and general-purpose multimodal judge benchmarks, PhyCritic achieves strong performance gains over open-source baselines and, when applied as a policy model, further improves perception and reasoning in physically grounded tasks.
One-sentence Summary
Tianyi Xiong et al. from Carnegie Mellon and NVIDIA introduce PhyCritic, a multimodal critic optimized for physical AI via RLVR training, enhancing perception and reasoning through self-referential finetuning, outperforming baselines in physical and general judge benchmarks while boosting policy performance in grounded tasks.
Key Contributions
- PhyCritic addresses the lack of physics-aware evaluation in multimodal critics by introducing a two-stage RLVR pipeline that first warms up physical reasoning skills, then trains the critic to generate its own prediction as a reference before judging responses, improving stability and physical correctness.
- The model introduces self-referential critic finetuning, where internal predictions ground judgments in physical reality, enabling more accurate assessments of causal validity and visual grounding compared to general-purpose critics trained on captioning or QA tasks.
- Evaluated on PhyCritic-Bench—a new benchmark built from embodied datasets like RoboVQA and BridgeData V2—PhyCritic outperforms open-source baselines and enhances perception and reasoning when deployed as a policy model in physically grounded tasks.
Introduction
The authors leverage multimodal critic models to address the growing need for reliable evaluation in physical AI, where systems must reason about perception, causality, and action in real-world contexts. Prior critics, trained mostly on general visual tasks like captioning or QA, lack physics awareness and fail to assess whether responses respect physical plausibility, spatial constraints, or causal sequences. PhyCritic introduces a two-stage RLVR pipeline: first warming up the model on physical reasoning tasks, then finetuning it to generate its own physics-aware prediction before evaluating candidate responses—creating a self-referential, grounded judgment process. This approach improves stability and correctness in physical evaluation, and the authors also release PhyCritic-Bench, a new benchmark with verifiable physical reasoning tasks, demonstrating state-of-the-art performance among open-source 7B/8B models.
Dataset
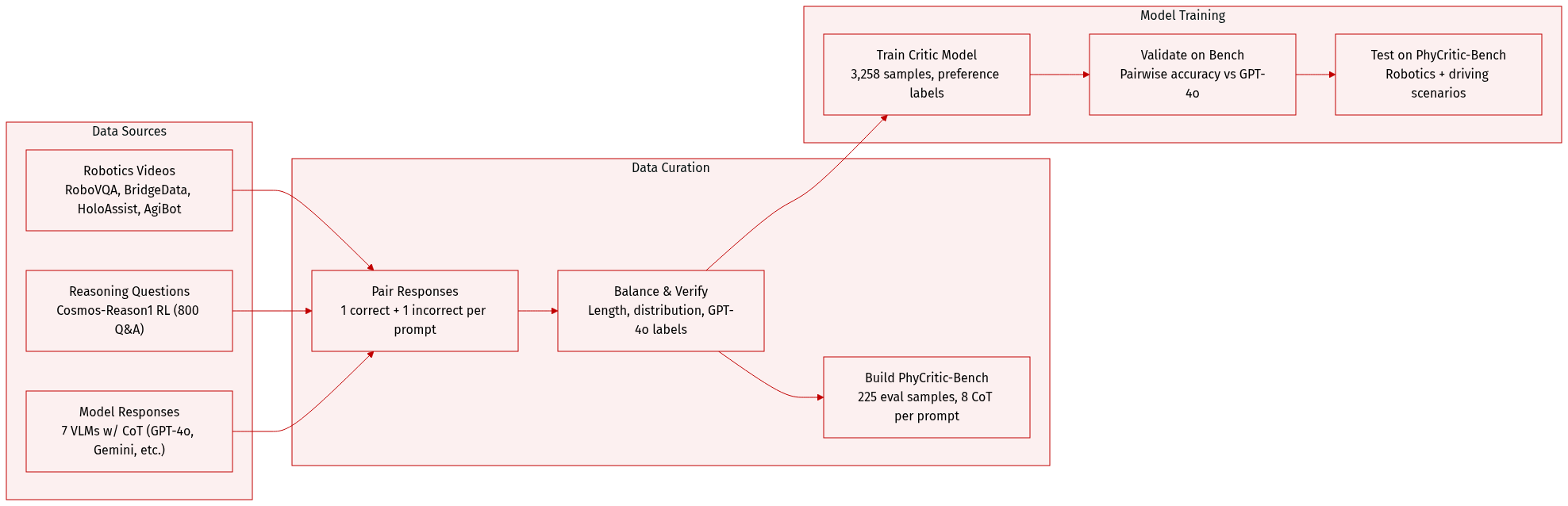
The authors use a custom critic training dataset and a new evaluation benchmark, PhyCritic-Bench, both built for physical AI reasoning tasks. Here’s how they’re structured and used:
-
Dataset Composition and Sources
- Training data comes from four robotics/embodied datasets: RoboVQA, Bridge-Data V2, HoloAssist, and AgiBot World — covering egocentric/third-person views and manipulation tasks (grasping, stacking, etc.) across simulated and real environments.
- Questions are sourced from Cosmos-Reason1 RL, which provides 800 high-quality, reasoning-intensive Q&A pairs.
- Model responses are generated by seven multimodal models: GPT-4o, Gemini-2.5-Flash, Qwen2.5-VL-72B, InternVL3-38B, Cosmos-Reason1-7B, Video-R1, and MiMo-VL-7B — all prompted with Chain-of-Thought to produce reasoning traces.
-
Key Subset Details
- Training Set (3,258 samples): Each sample is a tuple (Q, L_A, L_B, A_Q, P), where Q is a multimodal prompt, L_A/L_B are candidate responses, A_Q is the ground truth, and P indicates the preferred response.
- Responses are paired as one correct (verified by GPT-4o) and one incorrect, then balanced by length and distribution.
- PhyCritic-Bench (225 samples): Evaluates physical AI scenarios — robotics (RoboVQA, BridgeData V2, HoloAssist, AgiBot, RoboFail) and autonomous driving (LingoQA). Questions adapted from CosmosReason1-Bench.
- Each evaluation instance is a tuple (q, l_a, l_b, p), with p being the preference label assigned via GPT-4o verification of 8 CoT responses per prompt (one correct, one incorrect).
-
How the Data Is Used
- The training dataset trains the critic model to distinguish between high- and low-quality responses based on reasoning accuracy and visual grounding.
- PhyCritic-Bench evaluates model performance via pairwise preference accuracy: the model’s choice must match GPT-4o’s correctness-based label.
- Both datasets use GPT-4o for ground-truth labeling — verifying responses against reference answers to assign binary preference scores.
-
Processing Details
- All model responses are generated with Chain-of-Thought prompting.
- Response pairs are constructed to ensure one correct and one incorrect answer per prompt.
- Training data is balanced for response length and distribution.
- No cropping or metadata construction is mentioned — focus is on multimodal prompt-response tuples with preference labels.
Method
The authors leverage a two-stage reinforcement fine-tuning pipeline to endow vision-language models with physics-grounded critic capabilities. The framework is designed to first cultivate foundational physical reasoning and then refine the model’s ability to evaluate competing responses by anchoring its judgments to its own internal predictions. Refer to the framework diagram for an overview of the end-to-end training flow.
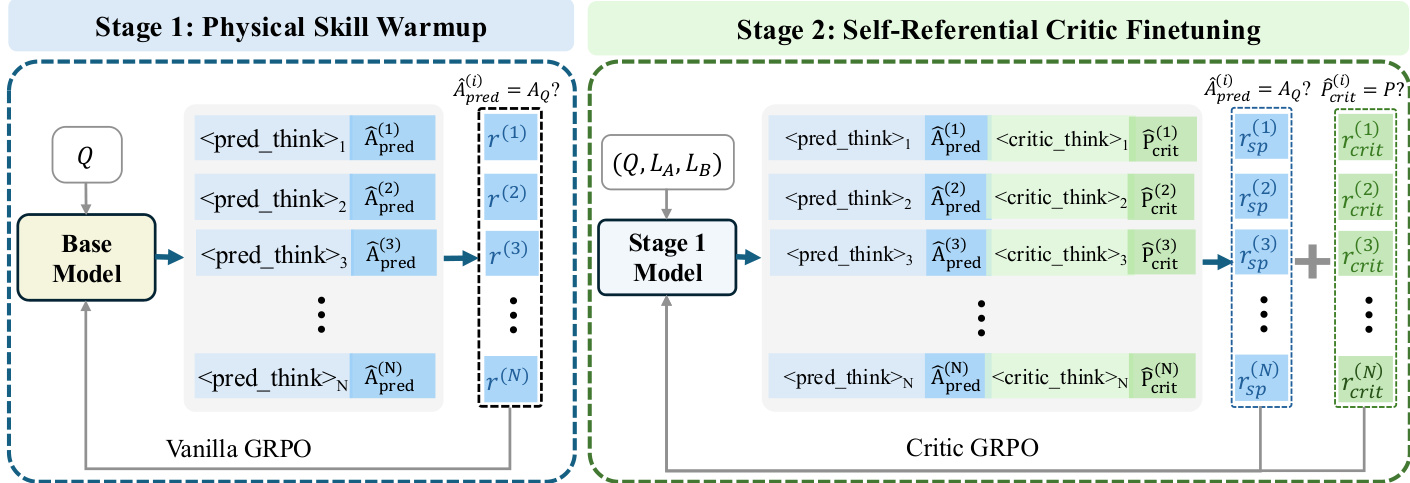
In Stage 1, termed Physical Skill Warmup, the base model is fine-tuned on a verifiable dataset of question-answer pairs (Q,AQ) using a standard reinforcement learning setup. The model generates a self-prediction A^pred for each question Q, and receives a binary accuracy reward:
r=I(A^pred(Q)=AQ)This stage employs Vanilla GRPO to optimize the policy, ensuring the model develops reliable physical reasoning before engaging in critic tasks. The output structure includes a reasoning trace <pred_think> followed by the predicted answer A^pred, which is evaluated against the ground truth.
Stage 2, Self-Referential Critic Finetuning, builds upon the Stage 1 model and introduces a more complex task: evaluating pairs of model responses (LA,LB) to a given question Q. The model is prompted to first generate its own prediction A^pred and then produce a preference judgment P^crit between the two responses, explicitly instructed to ground its critique in its self-prediction. The total reward is composed of an accuracy reward racc and a format reward rform:
rtotal=racc+rform∗αformThe accuracy reward is a weighted sum of two components: self-prediction reward rsp=I(A^pred=AQ) and critic reward rcrit=I(P^crit(Q,LA,LB)=P). These encourage the model to be both a competent solver and a reliable judge. The format reward enforces a structured output that includes <pred_think>, , , and a boxed final decision, ensuring interpretability and consistency.
Optimization in both stages uses Group Relative Policy Optimization (GRPO), which computes advantages by comparing multiple sampled trajectories within a group, eliminating the need for a learned value network. The loss function is:
LGRPO=Eo∼πθ[min(ρoAo,clip(ρo,1−ϵ,1+ϵ)Ao)]−βDKL(πθ∥πref)where ρo=πref(o)πθ(o) and Ao=std(r)ro−rˉ.
The critic prompt, as shown in the figure below, explicitly guides the model to first generate its own reasoning and answer, then use that as a reference to evaluate the two candidate responses. The prompt enforces a strict output format to ensure the model’s critique is grounded, structured, and interpretable.

Experiment
- PhyCritic, trained via a two-stage RL pipeline, establishes state-of-the-art critic performance on physical judgment tasks, outperforming both general-purpose and physical-reasoning VLMs despite minimal training data.
- The model demonstrates strong generalization, excelling not only in physical domains but also in general visual and reasoning benchmarks, indicating that physical grounding enhances broad multimodal judgment.
- PhyCritic improves policy-like physical reasoning capabilities, achieving top or near-top results across multiple embodied and spatial reasoning benchmarks, even surpassing models trained on vastly larger datasets.
- Ablations confirm that both stages of training are complementary: stage one builds foundational physical reasoning, while stage two’s self-referential critic finetuning significantly boosts judgment consistency, reduces overfitting, and enhances generalization.
- Self-referential training—where the model grounds critiques in its own reasoning—proves critical; removing this process degrades performance, validating that “solving before judging” leads to more reliable and grounded evaluations.
- PhyCritic effectively serves as a test-time judge for best-of-N sampling and as a reward signal for downstream policy training, yielding consistent performance gains over baselines.
- Compared to general-domain critics, PhyCritic delivers superior physical judgment and reasoning while maintaining competitive general-domain performance, highlighting the transfer value of physical grounding.
- Qualitative examples show PhyCritic produces grounded, consistent, and justifiable critiques across physical and general visual tasks, avoiding superficial or hallucinated reasoning that plagues baseline models.
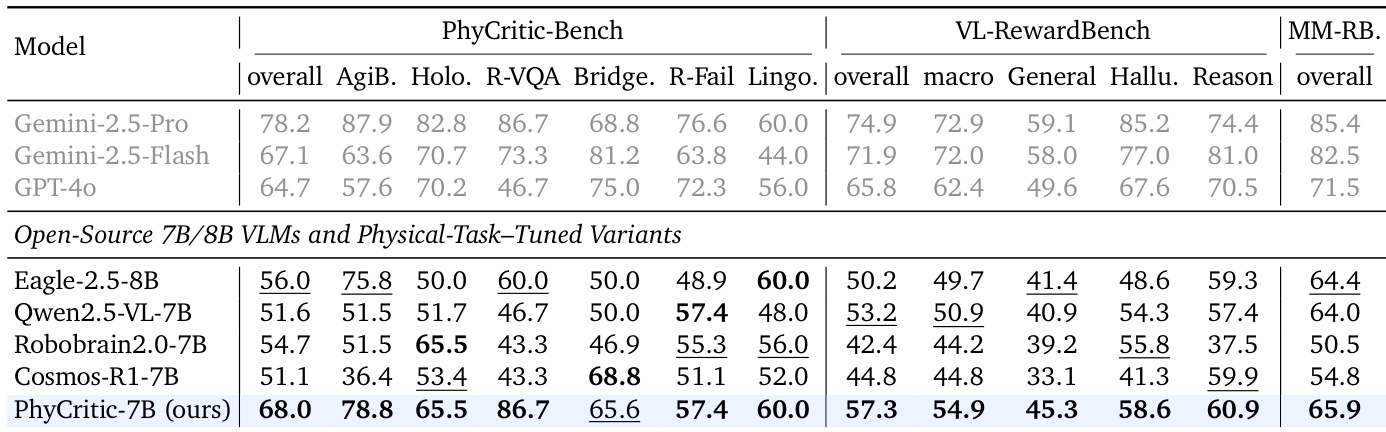
The authors use a two-stage reinforcement learning pipeline to train PhyCritic-7B, combining physical reasoning warmup with self-referential critic finetuning, resulting in a model that outperforms other open-source 7B/8B VLMs on physical judgment and general multimodal evaluation benchmarks. Results show that this approach not only enhances physical reasoning as a policy but also transfers effectively to general-domain judging tasks, despite being trained exclusively on physical contexts. The model’s performance is further supported by ablation studies confirming the necessity of both training stages and the value of self-referential feedback in improving judgment consistency and generalization.
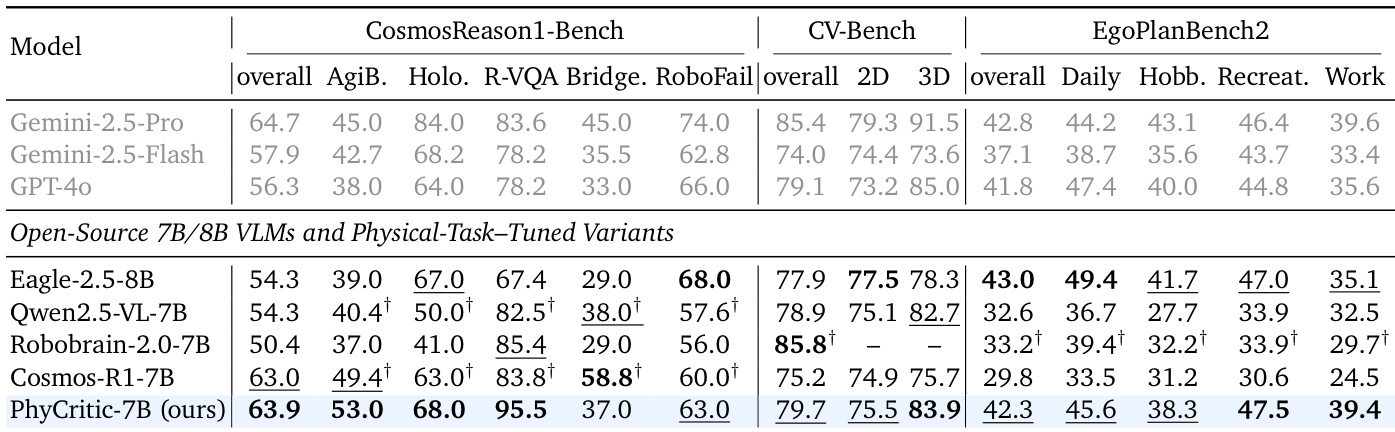
The authors use a two-stage reinforcement learning pipeline to train PhyCritic-7B, which achieves top performance among open-source 7B/8B models on physical reasoning benchmarks, including CosmosReason1-Bench and CV-Bench, while also generalizing effectively to egocentric planning tasks. Results show that the model’s physical critic training enhances both its judgment accuracy and policy-like reasoning, outperforming baselines even when those are trained on larger supervised datasets. The approach demonstrates strong data efficiency, requiring only 4,058 samples and 380 RL steps to deliver consistent gains across physical and general multimodal evaluation domains.
The authors use a two-stage reinforcement learning pipeline to train a physical critic model, which achieves state-of-the-art performance among open-source 7B/8B models on physical judgment and reasoning benchmarks. Results show that this approach not only enhances the model’s ability to evaluate physical reasoning but also improves its general multimodal judging capacity, despite being trained exclusively on physical tasks. The method demonstrates strong data efficiency and generalization, outperforming baselines that rely on larger supervised datasets or general-domain critic training.
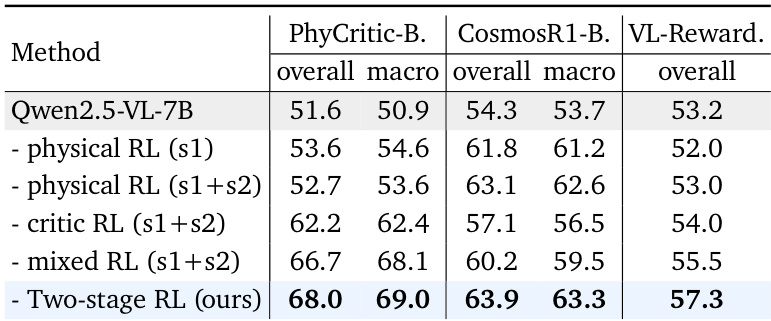
The authors use a structured critic prompt with explicit evaluation criteria to guide reinforcement learning, and removing these criteria leads to measurable drops in performance across physical judgment, reasoning, and general visual reward tasks. Results show that including detailed criteria during training improves the model’s ability to produce consistent, grounded judgments and enhances generalization to unseen domains. This indicates that explicit guidance during critic finetuning is critical for building reliable multimodal evaluation capabilities.
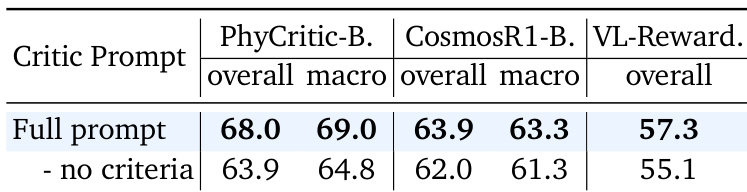
The authors use a two-stage reinforcement learning pipeline to train PhyCritic-7B, which outperforms both general-purpose and physical-reasoning VLMs on physical judgment and reasoning benchmarks. Results show that despite being trained only on physical tasks, PhyCritic generalizes effectively to general multimodal judging, achieving gains over the base model across multiple domains. The model’s self-referential critic training enhances judgment consistency and reasoning quality, enabling it to serve as an effective reward signal for downstream policy improvement.
