Command Palette
Search for a command to run...
Multi-agent cooperation through in-context co-player inference
Multi-agent cooperation through in-context co-player inference
Marissa A. Weis Maciej Wołczyk Rajai Nasser Rif A. Saurous Blaise Agüera y Arcas João Sacramento Alexander Meulemans
Abstract
Achieving cooperation among self-interested agents remains a fundamental challenge in multi-agent reinforcement learning. Recent work showed that mutual cooperation can be induced between "learning-aware" agents that account for and shape the learning dynamics of their co-players. However, existing approaches typically rely on hardcoded, often inconsistent, assumptions about co-player learning rules or enforce a strict separation between "naive learners" updating on fast timescales and "meta-learners" observing these updates. Here, we demonstrate that the in-context learning capabilities of sequence models allow for co-player learning awareness without requiring hardcoded assumptions or explicit timescale separation. We show that training sequence model agents against a diverse distribution of co-players naturally induces in-context best-response strategies, effectively functioning as learning algorithms on the fast intra-episode timescale. We find that the cooperative mechanism identified in prior work—where vulnerability to extortion drives mutual shaping—emerges naturally in this setting: in-context adaptation renders agents vulnerable to extortion, and the resulting mutual pressure to shape the opponent's in-context learning dynamics resolves into the learning of cooperative behavior. Our results suggest that standard decentralized reinforcement learning on sequence models combined with co-player diversity provides a scalable path to learning cooperative behaviors.
One-sentence Summary
By training sequence model agents against a diverse distribution of co-players, the researchers demonstrate that in-context co-player inference naturally induces cooperative behaviors and best-response strategies without the need for hardcoded learning rules or explicit timescale separation.
Key Contributions
- The paper introduces a decentralized multi-agent reinforcement learning setup where sequence model agents are trained against a diverse pool of co-players to induce in-context co-player inference and cooperation.
- This work presents a new reinforcement learning method that leverages self-supervised learning of predictive sequence models to learn the in-context best-response policies required for mixed-pool training.
- The research demonstrates that training against diverse co-players enables robust cooperation in the Iterated Prisoner's Dilemma by bridging in-context learning with co-player learning awareness without requiring explicit timescale separation or meta-gradient machinery.
Introduction
As autonomous agents based on foundation models move from isolated systems to interacting entities, ensuring cooperation in mixed-motive environments is critical for scalable multi-agent systems. Previous attempts to achieve cooperation through co-player learning awareness often rely on rigid assumptions about an opponent's learning rules or require a strict separation between fast-updating naive learners and slow-updating meta-learners. The authors leverage the in-context learning capabilities of sequence models to bridge this gap, demonstrating that training agents against a diverse distribution of co-players naturally induces in-context best-response strategies. This approach allows agents to function as both naive learners through intra-episode adaptation and learning-aware agents through parameter updates, enabling cooperative behaviors to emerge naturally through mutual extortion dynamics without complex meta-gradient machinery.
Dataset
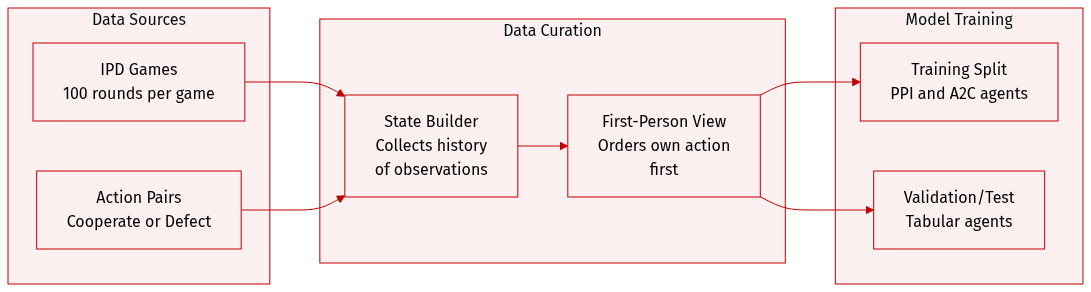
The authors utilize an Iterated Prisoners Dilemma (IPD) environment to evaluate agent performance. The dataset and environment characteristics are summarized below:
- Dataset Composition and Environment Rules: The environment consists of games played over 100 rounds. In each round, two agents choose between two actions: cooperate (C) or defect (D).
- Observation and State Construction: The environment provides five distinct observations. These include the initial state s0 and four subsequent observations based on the action pairs from the previous round: (C, C), (C, D), (D, C), and (D, D). While tabular agents only process the most recent observation ot, the PPI and A2C agents are trained to leverage the full history x≤t.
- Data Processing and Perspective: Agents receive observations from a first person perspective, meaning an agent's own action is always enumerated first in the observation sequence.
- Reward Mechanism: Rewards are assigned to agents at each round based on a specific single round payoff matrix.
Method
The authors propose Predictive Policy Improvement (PPI) agents, which serve as a practical approximation of embedded Bayesian agents. The core of the PPI framework is the integration of a learned sequence model with a planning-based policy improvement mechanism, moving away from the standard reinforcement learning paradigm where a separate critic is used.
Sequence Model Architecture
The PPI agent utilizes a sequence model designed to act simultaneously as a world model and a policy prior. This model is implemented as a Gated Recurrent Unit (GRU) with a 128-dimensional hidden state. The input pipeline processes observations, actions, and rewards through modality-specific linear layers, projecting them into a shared 32-dimensional embedding space. Prior to this projection, observations and actions are one-hot encoded.
The embeddings are fed into the GRU, and the resulting outputs are processed using the Swish activation function. To facilitate multi-modal prediction, distinct linear output heads decode the hidden states to predict future tokens for each specific modality. Specifically, the model predicts:
- Actions pϕ(at∣x≤t) using a categorical distribution.
- Observations pϕ(ot∣x<t,at−1) using a categorical distribution.
- Rewards pϕ(rt∣x<t,at−1,ot) using a normal distribution with fixed variance.
Training Process
The training of the sequence model follows an iterative, multi-phase approach. The authors employ a performative prediction strategy where the model is trained on a dataset D that accumulates interaction histories from all previous and current phases. This ensures more stable training as the agent's own policy influences the data distribution.
In each of the 30 training phases, the model parameters ϕ are re-initialized and optimized to minimize a joint next-token prediction loss: Ltrain=λobsLobs+λactLaction+λrewardLreward
The individual loss components are defined as: Lobs=−NT1∑n=1N∑t=1Tlogpϕ(ot(n)∣x≤t−1(n)) Lreward=−NT1∑n=1N∑t=1Tlogpϕ(rt(n)∣x≤t−1(n),ot(n)) Laction=−NT1∑n=1N∑t=1Tlogpϕ(at(n)∣x≤t−1(n),ot(n),rt(n))
Optimization is conducted using the AdamW optimizer over 10 epochs per phase, with a batch size of 256 and gradient clipping at a norm of 1.0.
Inference and Policy Improvement
During deployment, the agent does not rely on a traditional value function. Instead, it estimates Q values by performing Monte Carlo roll-outs into the future using the learned sequence model as a simulator. By sampling future trajectories from the model, the agent evaluates the expected return of potential actions based on its internal representation of environment dynamics and co-player responses.
The final action selection is performed by a policy π(a∣x≤t) that re-weights the model's prior probability p(a∣x≤t;ϕ) using the estimated value Q^p(x≤t,a) through a Boltzmann distribution: π(a∣x≤t)=Z1p(a∣x≤t;ϕ)exp(βQ^p(x≤t,a))
In this formulation, β acts as an inverse temperature parameter that defines a trust region around the behavioral prior pϕ. This mechanism allows the agent to improve its policy by selecting actions that the sequence model predicts will yield higher cumulative rewards.
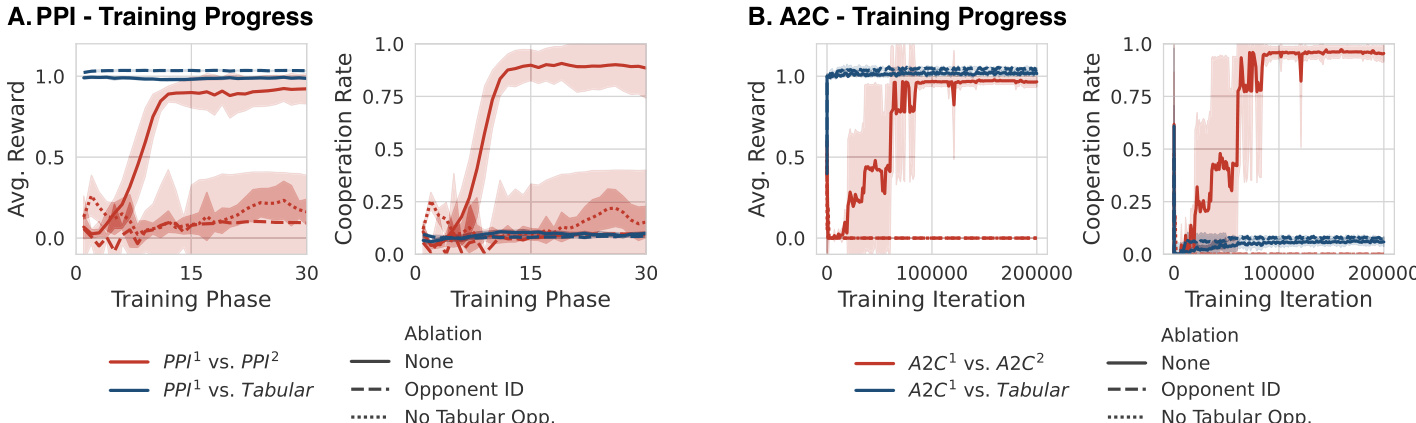
Experiment
The researchers evaluate the emergence of cooperation in the Iterated Prisoner's Dilemma by training agents in a mixed population of learning models and static tabular agents. Using both Predictive Policy Improvement and Independent A2C, the study validates that training against a diverse pool of opponents induces robust in-context inference capabilities. The findings demonstrate a causal chain where diversity drives in-context best-response mechanisms, which in turn creates a vulnerability to extortion that ultimately settles into mutual cooperation through reciprocal shaping.
The the the table lists the hyperparameters used for the A2C algorithm across four different experimental steps. It details various settings including batch size, reward rescaling, and learning rates to ensure consistency or controlled variation throughout the study. Batch sizes increase from the first two steps to the final two steps The reward rescaling factor decreases progressively across the four steps The learning rate is adjusted differently across the steps, with the lowest value appearing in step three
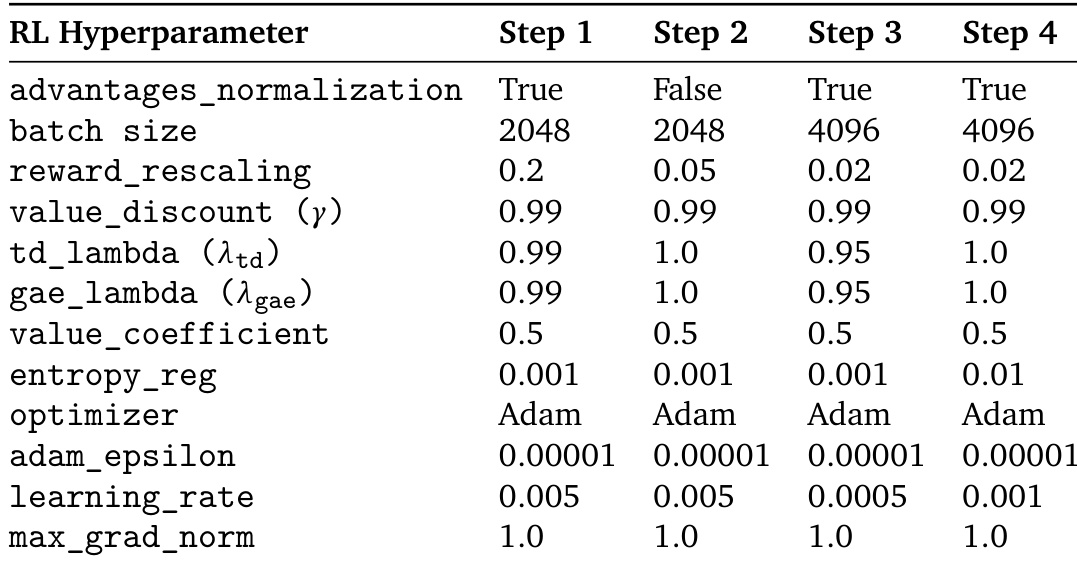
The evaluation utilizes the A2C algorithm across four experimental steps with controlled variations in batch size, reward rescaling, and learning rates. These adjustments are designed to test the impact of different hyperparameter configurations on agent performance. The setup ensures a systematic investigation into how scaling and learning dynamics influence the stability and effectiveness of the reinforcement learning process.