Command Palette
Search for a command to run...
CARE-Edit: Condition-Aware Routing of Experts for Contextual Image Editing
CARE-Edit: Condition-Aware Routing of Experts for Contextual Image Editing
Yucheng Wang Zedong Wang Yuetong Wu Yue Ma Dan Xu
Abstract
Unified diffusion editors often rely on a fixed, shared backbone for diverse tasks, suffering from task interference and poor adaptation to heterogeneous demands (e.g., local vs global, semantic vs photometric). In particular, prevalent ControlNet and OmniControl variants combine multiple conditioning signals (e.g., text, mask, reference) via static concatenation or additive adapters which cannot dynamically prioritize or suppress conflicting modalities, thus resulting in artifacts like color bleeding across mask boundaries, identity or style drift, and unpredictable behavior under multi-condition inputs. To address this, we propose Condition-Aware Routing of Experts (CARE-Edit) that aligns model computation with specific editing competencies. At its core, a lightweight latent-attention router assigns encoded diffusion tokens to four specialized experts--Text, Mask, Reference, and Base--based on multi-modal conditions and diffusion timesteps: (i) a Mask Repaint module first refines coarse user-defined masks for precise spatial guidance; (ii) the router applies sparse top-K selection to dynamically allocate computation to the most relevant experts; (iii) a Latent Mixture module subsequently fuses expert outputs, coherently integrating semantic, spatial, and stylistic information to the base images. Experiments validate CARE-Edit's strong performance on contextual editing tasks, including erasure, replacement, text-driven edits, and style transfer. Empirical analysis further reveals task-specific behavior of specialized experts, showcasing the importance of dynamic, condition-aware processing to mitigate multi-condition conflicts.
One-sentence Summary
Researchers from The Hong Kong University of Science and Technology propose CARE-Edit, a unified diffusion editor that replaces static adapters with a dynamic latent-attention router. This innovation allocates tokens to specialized experts based on multi-modal conditions, effectively eliminating artifacts like color bleeding in complex tasks such as subject replacement and style transfer.
Key Contributions
- Existing unified diffusion editors suffer from task interference and artifacts like color bleeding because they rely on static fusion of multi-modal signals that cannot dynamically prioritize conflicting conditions.
- We propose CARE-Edit, a framework that employs a lightweight latent-attention router to dynamically dispatch diffusion tokens to four specialized experts for text, mask, reference, and base processing based on input conditions and timesteps.
- Experiments on diverse tasks including object erasure, replacement, and style transfer demonstrate that CARE-Edit achieves superior edit faithfulness and boundary cleanliness compared to static-fusion baselines by effectively resolving multi-condition conflicts.
Introduction
Diffusion-based models have revolutionized image editing by enabling tasks like object replacement and style transfer, yet current unified editors struggle when handling multiple, conflicting input signals such as text prompts, masks, and reference images. Existing approaches typically rely on static fusion mechanisms that force all conditions through a shared backbone, which often leads to artifacts like color bleeding, identity drift, or inconsistent behavior because the model cannot dynamically allocate its capacity to prioritize specific signals at different stages of the generation process. To address these limitations, the authors introduce CARE-Edit, a framework that employs condition-aware routing to dynamically dispatch diffusion tokens to specialized heterogeneous experts tailored for text, spatial masks, reference features, and global coherence. This approach utilizes a lightweight router to adaptively select the most relevant experts based on the input conditions and diffusion timestep, while complementary modules like Mask Repaint and Latent Mixture further refine spatial precision and resolve conflicts between competing signals.
Dataset
-
Dataset Composition and Sources The authors construct a training corpus of approximately 120K triplets by aggregating data from four primary sources: MagicBrush and OmniEdit for instruction-based edits, UNO for object removal and replacement tasks, and AnyEdit for style transfer. To address spatial ambiguity in purely instruction-based data, they curate a specialized 20K subset from Subjects200K that focuses on diverse objects and humans with precise identity preservation.
-
Key Details for Each Subset
- Instruction-based: Sourced from MagicBrush and OmniEdit, these samples pair real-world images with rich natural language instructions.
- Removal and Replacement: Derived from a subset of UNO to target specific object manipulation tasks.
- Style Transfer: Enriched using AnyEdit to include fine-grained appearance and style-level instructions.
- Subject-Centric (20K): Built from Subjects200K, this subset provides high-quality foreground masks and reference images on clean white backgrounds to facilitate region-specific editing.
-
Model Usage and Training Strategy The model utilizes a curated mixture of these datasets to teach diverse editing capabilities while maintaining data efficiency. The training pipeline emphasizes a mask-aware, subject-centric curriculum that allows the model to outperform larger baselines despite using significantly fewer training samples. The data is structured to support condition-aware expert routing, where coarse bounding boxes guide the routing mechanism and fine masks provide pixel-accurate supervision.
-
Processing and Metadata Construction
- Mask-Aware Generation: The authors employ a GPT-Image-1 and VLM-based pipeline to synthesize image pairs with consistent backgrounds but varying foregrounds. This process starts with a reference subject and generates diverse scene descriptions to create high-quality pairs annotated with precise segmentation masks.
- Coarse and Fine Masks: For each sample, a high-resolution fine mask is extracted using an off-the-shelf segmentation model and manually filtered. A coarse axis-aligned bounding box is then derived from the fine mask to serve as a spatial prior for expert routing.
- Prompt Taxonomy: The generation process is organized along two axes: category and operation type (e.g., replacement, addition, style change) and scene-level templates. This ensures that background layout, lighting, and camera viewpoints remain similar across paired images while foreground regions change, providing clean supervision for localized editing.
Method
The authors propose CARE-Edit, a diffusion-based editor designed to mitigate task interference in unified image editing. Unlike static fusion approaches that process all conditions with a shared backbone, CARE-Edit performs fine-grained condition-aware routing over a set of heterogeneous experts. This specialize-then-fuse manner allows the model to dynamically allocate computation, prioritize relevant modalities, and mitigate conflicts between competing edit instructions.
The framework unifies diverse editing paradigms, including instruction-based editing (text and base image) and subject-based editing (base and reference image), into a single system capable of handling text, base image, reference image, and mask inputs simultaneously.
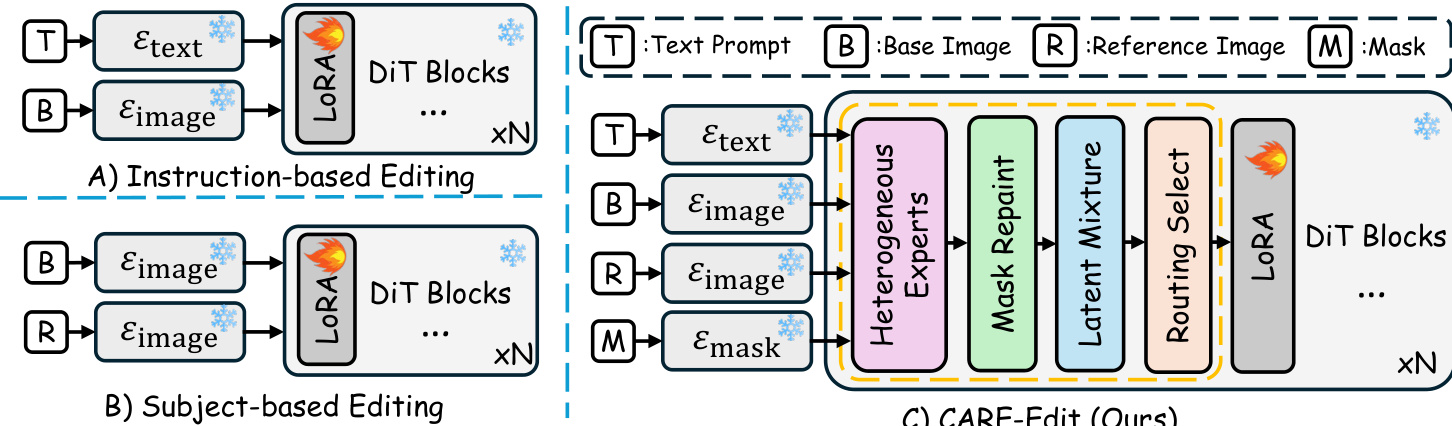
Each input modality is first mapped to a latent token sequence by a specialized, frozen encoder. The text prompt is processed by a Text Encoder Etex(⋅), producing contextual embeddings Cp. The Image Encoder Eimage(⋅) extracts latent representations Zb for the base image and Zr for the reference image. A Mask Encoder Emask(⋅) converts the spatial mask into aligned latent tokens Zm. These latents are projected to a shared embedding space and concatenated to form a unified token sequence h0. This sequence is propagated through a frozen diffusion transformer (DiT) backbone, where LoRA-style fine-tuning is applied to the self-attention and projection layers to adapt the model to multi-modal conditioning without fully retraining the backbone.
The core innovation lies in the Projection Layer with Experts, which introduces four heterogeneous experts corresponding to the text, mask, reference, and base modalities.
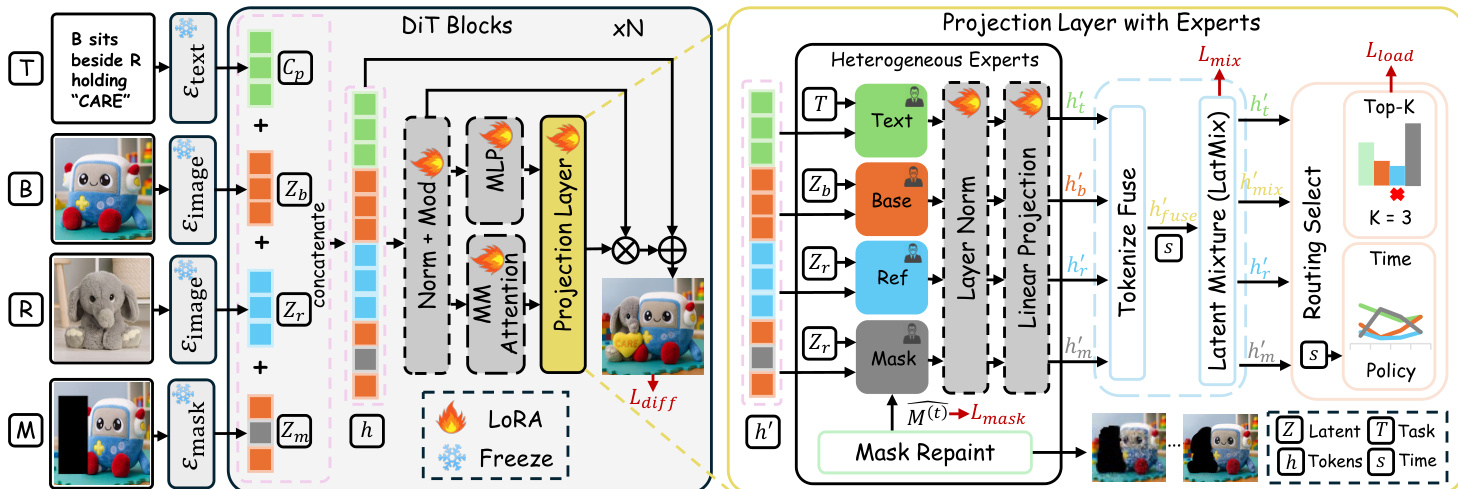
The text expert performs semantic reasoning and object synthesis through cross-attention with text tokens. The mask expert focuses on spatial precision and boundary refinement guided by the edit mask. The reference expert learns identity- and style-consistent transformations from reference features, while the base expert enforces global coherence and background consistency. To determine which modality experts should process each token, CARE-Edit performs token-wise Top-K routing. For every token, a router computes a probability distribution over the four experts by combining local content features and global task context. In practice, K is set to 3, achieving a favorable balance between representational diversity and computational efficiency. This scheme allows each token to adaptively attend to the most relevant experts under spatial-semantic-task joint guidance.
To address the issue where user-defined masks may misalign with object boundaries, the authors incorporate a Mask Repaint module. This module refines the coarse user-provided masks at each diffusion step by exploiting geometric correspondence between the current latent and reference features. It predicts a soft, boundary-aware mask that adapts to object contours, promoting smooth transitions between edited and preserved regions. The refined mask is fed back into the routing process of the next diffusion block, modulating the mask and base experts to ensure progressively sharper boundary control.
Finally, the output of the specialized experts must be coherently aggregated. The authors employ a Latent Mixture module that performs per-token and per-timestep processing based on routing confidence and contextual cues. The fused latent is obtained through a convex combination of expert outputs, where each channel integrates text, semantic, and mask cues according to the router's attention pattern. To maintain global coherence, this fused latent is blended with the base expert's output via a learned, timestep-dependent gate. The model is trained end-to-end by combining the standard diffusion reconstruction loss with auxiliary regularizers for load balancing, mask boundary consistency, and latent mixture smoothness.
Experiment
- Instruction-based editing experiments on EMU-Edit and MagicBrush validate that CARE-Edit produces cleaner, more instruction-faithful results with sharper boundaries and fewer artifacts compared to both task-specific and unified baselines.
- Subject-driven contextual editing tests on DreamBench++ confirm the model's ability to preserve subject identity and structure while effectively integrating objects into complex multi-object scenes.
- Ablation studies demonstrate that dynamic expert routing is essential for handling diverse editing behaviors, while specific components like Latent Mixture and Mask Repaint are critical for aggregating outputs and achieving precise edits.
- Empirical analysis reveals that the model successfully learns to disentangle editing tasks, with a Base Expert maintaining global coherence, a Mask Expert focusing on geometric restructuring, and a Reference Expert handling semantic and stylistic injection.
- Extended qualitative comparisons show robust performance across object removal, addition, replacement, and style transfer, highlighting the model's capacity to maintain structural integrity while applying complex semantic changes.