Command Palette
Search for a command to run...
How Far Can Unsupervised RLVR Scale LLM Training?
How Far Can Unsupervised RLVR Scale LLM Training?
Abstract
Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
One-sentence Summary
Researchers from Tsinghua University and collaborating institutes reveal that intrinsic unsupervised RLVR methods inevitably cause model collapse by sharpening initial distributions, proposing the Model Collapse Step metric to predict trainability while advocating external rewards for scalable LLM training.
Key Contributions
- The paper establishes a taxonomy for unsupervised RLVR and provides a unified theoretical framework showing that all intrinsic reward methods converge toward sharpening the model's initial distribution rather than discovering new knowledge.
- Extensive experiments reveal that intrinsic URLVR consistently follows a rise-then-fall pattern where performance collapses when the model's initial confidence misaligns with correctness, regardless of specific engineering choices.
- The authors propose the Model Collapse Step metric to predict RL trainability and demonstrate that intrinsic rewards remain effective for test-time training on small datasets, while external rewards grounded in computational asymmetries offer a potential path to escape these scaling limits.
Introduction
Large language models currently rely on reinforcement learning with verifiable rewards to enhance reasoning, but this approach faces a critical bottleneck as obtaining human-verified ground truth labels becomes prohibitively expensive and infeasible for superintelligent systems. Unsupervised RLVR aims to solve this by deriving rewards without labels, yet prior work relying on intrinsic model signals suffers from a fundamental rise-then-fall pattern where training initially improves performance before collapsing due to reward hacking and model degradation. The authors provide a comprehensive theoretical and empirical analysis revealing that intrinsic methods merely sharpen the model's initial distribution, which fails when confidence misaligns with correctness, while proposing the Model Collapse Step as a practical metric to predict trainability and advocating for external reward methods that leverage computational asymmetries to achieve scalable, stable improvement.
Dataset
- The training dataset consists of M prompt-answer pairs, where each entry includes a prompt xi and its corresponding ground-truth answer ai∗.
- For every prompt in the set, the authors generate N rollout responses using the current policy πθ.
- Each generated response contains a full reasoning trajectory and an extracted answer derived from that trajectory.
- The data serves as the foundation for training, where the model learns from the relationship between the initial prompts, the generated trajectories, and the verified ground-truth answers.
Method
The authors leverage a framework for Unsupervised Reinforcement Learning with Verifiable Rewards (URLVR) that eliminates the need for ground-truth labels by utilizing proxy intrinsic rewards generated solely by the model. This approach distinguishes between two primary paradigms for constructing rewards: Certainty-Based and Ensemble-Based methods.
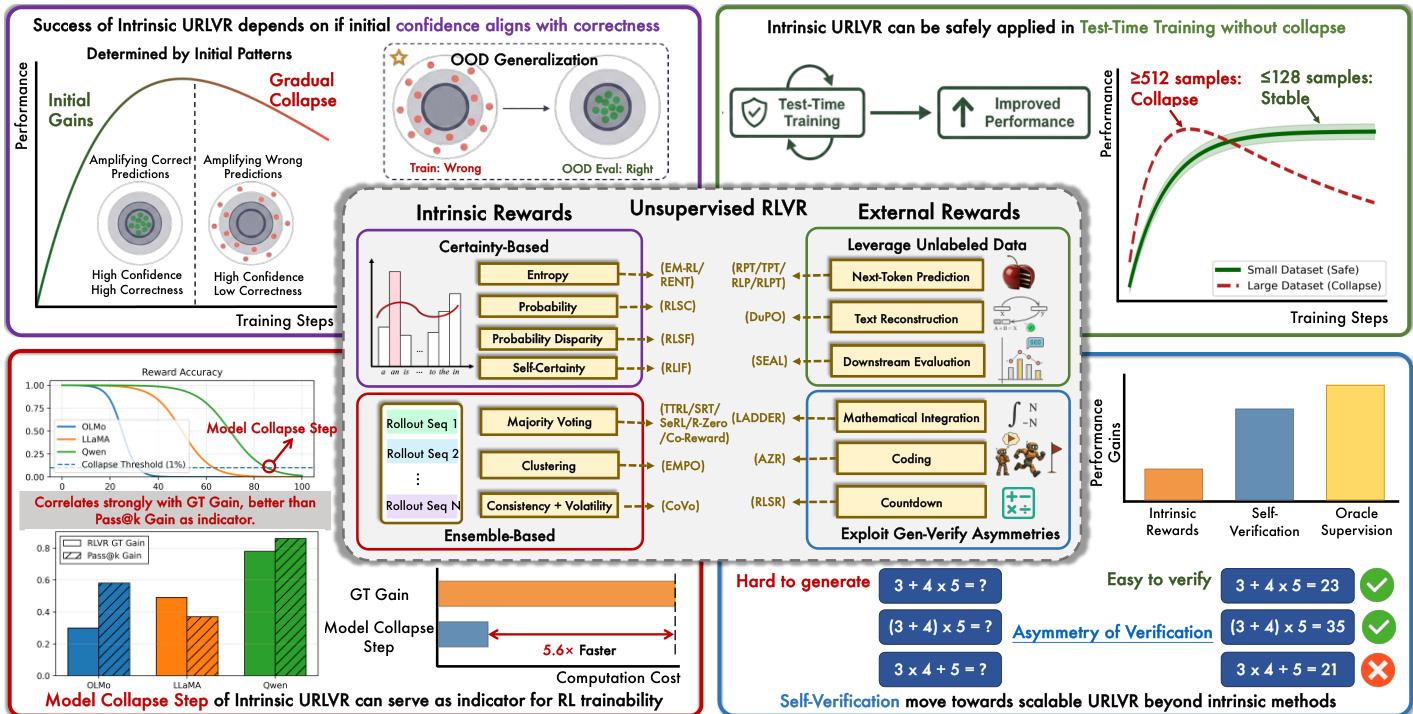
Certainty-Based rewards derive signals from the policy's confidence, such as logits or entropy, operating on the assumption that higher confidence correlates with correctness. These methods include estimators like Self-Certainty, which measures the KL divergence from a uniform distribution, and Token-Level Entropy, which penalizes uncertainty at each generation step. Conversely, Ensemble-Based rewards leverage the wisdom of the crowd by generating multiple rollouts for the same prompt. They assume that consistency across these diverse candidate solutions, often formalized through majority voting or semantic clustering, serves as a robust proxy for correctness.
The underlying mechanism driving these methods is a sharpening process where the model converges towards its initial distribution. Theoretically, the training dynamics follow a KL-regularized RL objective. The optimal policy for this objective has the closed form:
πθ∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))where Z(x) is the partition function and β controls regularization strength. For intrinsic rewards like majority voting, this creates a "rich-get-richer" dynamic. If the model's initial confidence aligns with correctness, the sharpening mechanism amplifies these correct predictions, leading to performance gains. However, if the initial confidence is misaligned, the same mechanism systematically reinforces errors, leading to a gradual collapse in performance.
To monitor this stability, the authors introduce the Model Collapse Step as an indicator of trainability. This metric tracks the training step where reward accuracy drops below a specific threshold, such as 1%. Models with stronger priors sustain intrinsic URLVR for longer periods before collapsing, allowing for efficient base model selection without the computational cost of full reinforcement learning training. This framework highlights the critical dependency of intrinsic URLVR success on the alignment between initial confidence and correctness.
Experiment
- Intrinsic URLVR methods universally exhibit a rise-then-fall pattern where early gains from aligning confidence with correctness eventually collapse into reward hacking, regardless of hyperparameter tuning or specific reward design.
- Fine-grained analysis reveals that training primarily amplifies the model's initial preferences rather than correcting errors on specific problems, yet this sharpening can still generalize to improve performance on unseen out-of-distribution tasks if initial confidence aligns with correctness.
- Model collapse is prevented when training on small, domain-specific datasets or during test-time training, as these conditions induce localized overfitting rather than the systematic policy shifts that cause failure in large-scale training.
- The "Model Collapse Step," measuring when reward accuracy drops during intrinsic training, serves as a rapid and accurate predictor of a model's potential for RL gains, outperforming static metrics like pass@k.
- External reward methods leveraging generation-verification asymmetry, such as self-verification, offer a more scalable path than intrinsic rewards by providing signals grounded in computational procedures rather than the model's internal confidence.