Command Palette
Search for a command to run...
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
Difan Jiao Qianfeng Wen Blair Yang Zhenwei Tang Ashton Anderson
Abstract
We introduce ThinkTwice, a simple two-phase framework that jointly optimizes LLMs to solve reasoning problems and refine the answers, based on Group Relative Policy Optimization (GRPO). In each pair of training steps, ThinkTwice first optimizes the model on solving reasoning problems, then optimizes it on refining its own solutions to the same problems, using the same binary correctness reward in both phases without correctness signals or critique annotations. Across five mathematical reasoning benchmarks and two model families including Qwen3-4B and Olmo3-7B, ThinkTwice substantially improves both reasoning and refinement performance over competitive online policy optimization baselines. Specifically, on Qwen3-4B, ThinkTwice outperforms GRPO on AIME by 5 percentage points before refinement and by 11.5 points after one self-refinement step, measured by pass@4. Analysis of the training dynamics of ThinkTwice reveals an implicit rectify-then-fortify curriculum: refinement predominantly corrects errors early in training and naturally shifts toward preserving already-correct solutions as the model improves, yielding a more rectified reward signal. Our work establishes joint training of reasoning and self-refinement as a principled and effective methodology for RLVR.
One-sentence Summary
Researchers from the University of Toronto and Coolwei AI Lab propose ThinkTwice, a two-phase framework that uses Group Relative Policy Optimization to jointly optimize large language models for reasoning and self-refinement without critique annotations, significantly improving mathematical reasoning performance across five benchmarks and two model families including Qwen3-4B and Olmo3-7B.
Key Contributions
- The paper introduces ThinkTwice, a two-phase reinforcement learning framework that jointly optimizes large language models to solve reasoning problems and perform self-refinement using Group Relative Policy Optimization. This method utilizes a shared policy and a single binary correctness reward across both phases, eliminating the need for critique annotations, process labels, or external verifiers.
- The research demonstrates an implicit rectify-then-fortify curriculum during training, where the model initially focuses on correcting errors and subsequently shifts toward preserving correct solutions. This dynamic behavior produces a more rectified reward signal while adding minimal training overhead compared to standard optimization baselines.
- Experimental results across five mathematical reasoning benchmarks and two model families, including Qwen3-4B and Olmo3-7B, show significant performance gains over competitive online policy optimization baselines. For example, on the AIME benchmark, the framework improves Qwen3-4B performance by 11.5 percentage points after one self-refinement step when measured by pass@4.
Introduction
Reinforcement learning with verifiable rewards (RLVR) is a critical technique for enhancing the reasoning capabilities of large language models through outcome-based signals. While existing self-refinement methods often rely on expensive process supervision, critique annotations, or external verifiers, they frequently fail to learn a reusable refinement policy or struggle with unreliable prompt-only corrections. The authors leverage a two-phase framework called ThinkTwice to jointly optimize reasoning and self-refinement using only a simple binary correctness reward. By alternating between optimizing for problem-solving and optimizing for solution refinement, the framework establishes an implicit curriculum that corrects errors early in training and preserves correct solutions as the model improves.
Dataset
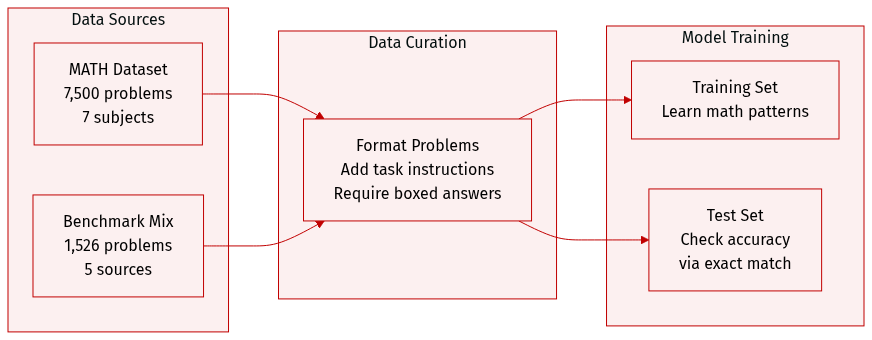
The authors utilize the following datasets for training and evaluation:
- Training Data: The model is trained on the MATH dataset, which contains 7,500 problems categorized into seven subjects and five difficulty levels.
- Evaluation Benchmarks: To assess mathematical reasoning, the authors use a test set of 1,526 problems drawn from five distinct sources:
- MATH500: 500 problems sourced from the MATH test set.
- OlympiadBench: 581 problems from olympiad level competitions.
- Minerva Math: 272 problems from high school math competitions.
- AIME: 90 problems from the AIME 2022 to 2024 period.
- AMC: 83 problems from the AMC 10/12 competitions.
- Data Processing and Evaluation: Each problem is structured with a specific task instruction that directs the model to provide its final answer within a boxed format. Accuracy is measured through exact matching of the boxed content using the Huggingface Math-Verify tool.
Method
The authors leverage Group Relative Policy Optimization (GRPO) as the foundational reinforcement learning algorithm for ThinkTwice, enabling joint optimization of reasoning and self-refinement without external verification signals. GRPO operates by sampling a group of responses for each input and computing advantages through group normalization, which eliminates the need for a separate critic model and enhances training stability. The policy update follows a clipped surrogate objective that balances performance improvement with KL divergence constraints against a reference policy, with rewards derived from outcome-based correctness for mathematical reasoning tasks.

As shown in the figure below, the ThinkTwice framework alternates between two distinct training phases within a unified GRPO structure. In Phase 1, the model generates multiple candidate solutions for a batch of problems using the current policy, evaluates them with correctness rewards, and updates the policy based on these outcomes. This phase focuses on reasoning optimization, where the model learns to generate accurate solutions from scratch. From the generated responses, one base solution is randomly selected per problem to serve as the input for the subsequent refinement phase.
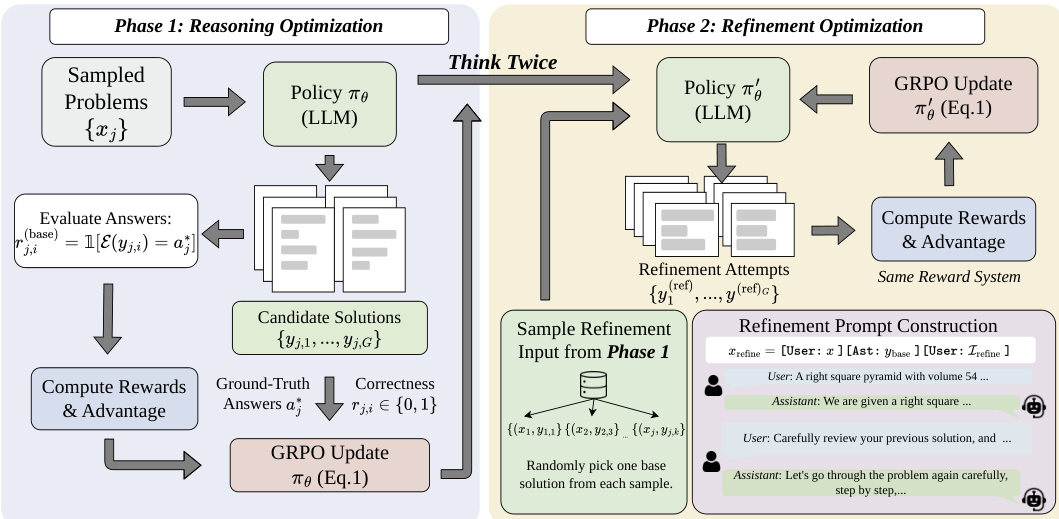
In Phase 2, the model uses the updated policy to generate refinement attempts for the selected base solutions. The refinement prompt is constructed as a multi-turn conversation, conditioning the model on its own prior response and a task-agnostic instruction to review and improve it. The refinement process is also evaluated using the same correctness reward, and the policy is updated again via GRPO, enabling the model to learn self-improvement strategies. This two-phase structure exposes the model to each problem twice—once for initial reasoning and once for refinement—under complementary objectives.
The framework employs a simple random sampling strategy for selecting base solutions, which naturally establishes an emergent curriculum: early in training, refinement primarily addresses incorrect solutions, while later it focuses on polishing correct ones. The refinement process relies solely on the binary correctness reward, allowing the model to develop its own refinement strategies without external constraints. This reward design encourages the model to either detect and correct errors or preserve and enhance correct solutions, aligning with the goal of self-refinement without external signals.
Experiment
The ThinkTwice framework is evaluated through a two-fold protocol that tests both direct reasoning capabilities and multi-turn self-refinement performance across five mathematical reasoning benchmarks. Experiments using Qwen3-4B and OLMo3-7B demonstrate that joint optimization of solving and refining tasks significantly enhances both initial reasoning accuracy and the ability to correct errors. Qualitative analysis reveals an implicit training curriculum where the model transitions from rectifying concrete errors and completing stalled derivations early in training to fortifying and compressing already-correct solutions in later stages.
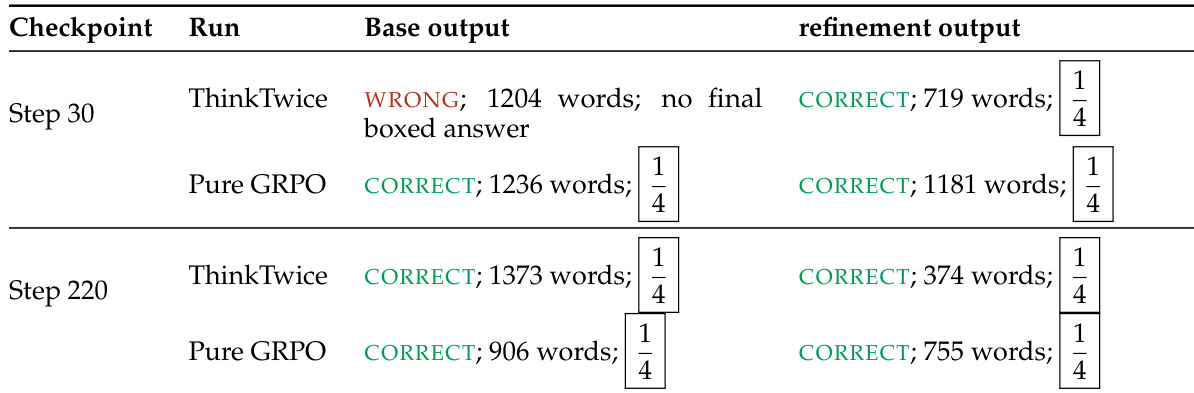
The the the table shows the evolution of ThinkTwice's refinement behavior across training steps. Early in training, ThinkTwice corrects incorrect base outputs, while later it shortens and cleans up already-correct solutions. The refinement process consistently produces correct answers with reduced output length compared to the base generation. Refinement corrects incorrect base outputs early in training Refinement shortens and cleans up correct base outputs later in training Refinement consistently produces correct answers with reduced output length compared to the base generation
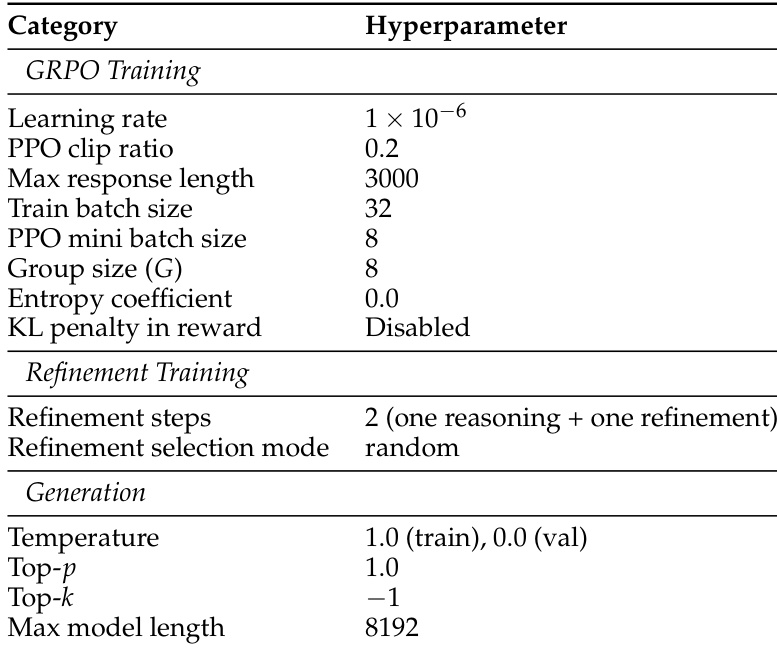
The experiment uses a two-phase training process for ThinkTwice, first optimizing reasoning and then refining solutions. The setup includes hyperparameters for GRPO training, refinement steps, and generation settings, with a focus on controlling response length and sampling during training. ThinkTwice uses a two-phase training process with separate stages for reasoning and refinement. The training includes specific hyperparameters for GRPO and refinement, such as batch size and response length. Generation settings control sampling behavior, with temperature and top-p values set to guide model outputs.
The experiment evaluates a model's ability to refine its own solutions across different training stages. Results show that early refinement corrects structural errors and incomplete derivations, while later refinement shortens correct solutions by removing unnecessary details. This transition from error correction to solution polishing occurs consistently across multiple problems and models. Early refinement corrects structural errors and incomplete derivations Later refinement shortens correct solutions by removing unnecessary details The refinement process shifts from error correction to solution polishing over training

ThinkTwice achieves the highest reasoning and refinement performance across two models, consistently outperforming all baselines on both direct reasoning and self-refinement tasks. The results show that ThinkTwice improves both capabilities within a unified training framework, with gains most pronounced on the most challenging benchmarks. ThinkTwice achieves the highest average performance on both reasoning and refinement across all models and benchmarks. ThinkTwice significantly outperforms all baselines on the most challenging AIME benchmark. ThinkTwice improves both reasoning and self-refinement capabilities without requiring external supervision or critique annotations.
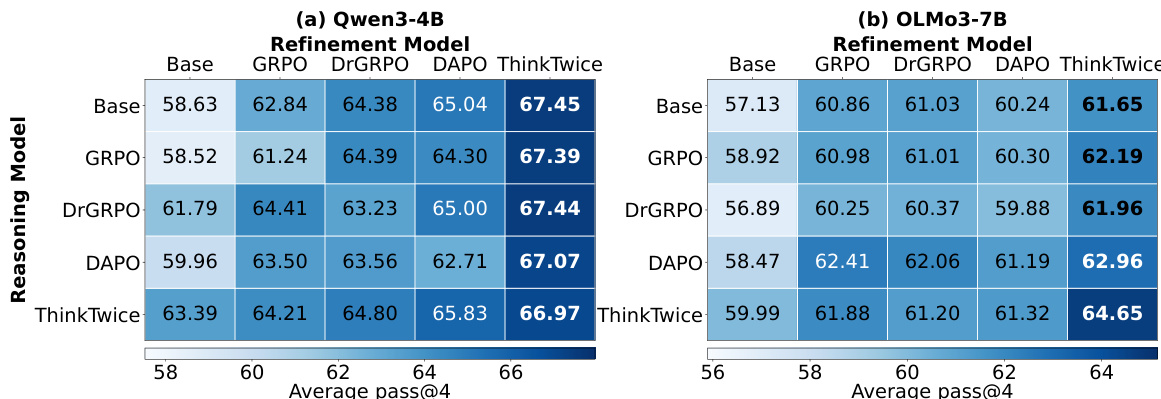
ThinkTwice achieves the highest average performance across multiple mathematical reasoning benchmarks for both Qwen3-4B and OLMo3-7B models, showing improvements over existing methods in both reasoning and self-refinement. The gains are most pronounced on the most challenging AIME benchmark, where ThinkTwice consistently reaches higher scores than other approaches. ThinkTwice achieves the highest average performance on all benchmarks for both models ThinkTwice outperforms all baselines on the AIME benchmark ThinkTwice improves both reasoning and self-refinement capabilities without external supervision
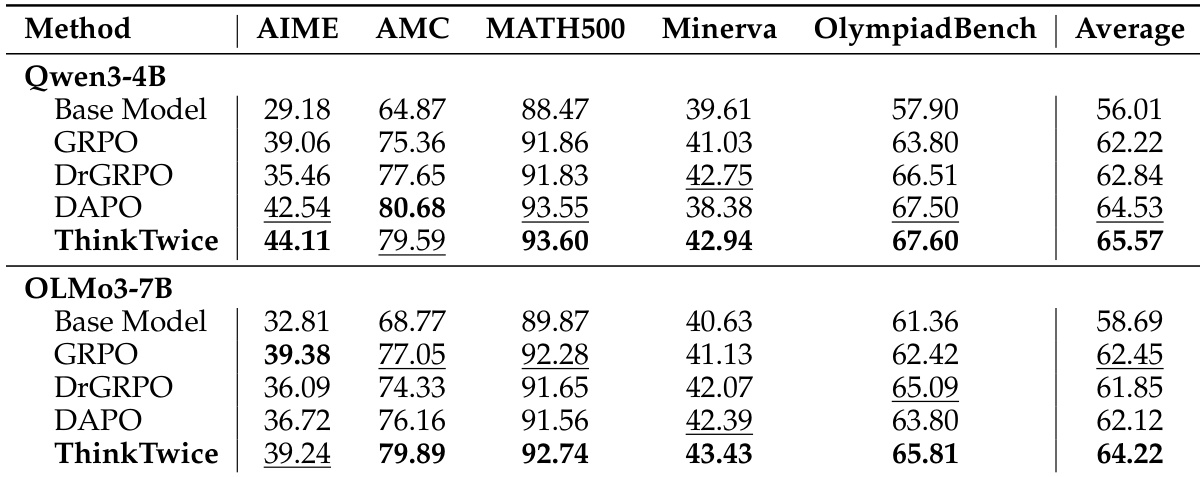
The evaluation employs a two-phase training process to assess how a model develops reasoning and self-refinement capabilities across various mathematical benchmarks. The results demonstrate that the refinement behavior evolves from correcting structural errors in early training stages to polishing and shortening correct solutions in later stages. Ultimately, ThinkTwice consistently outperforms baseline methods in both direct reasoning and self-refinement, showing its most significant improvements on highly challenging tasks without the need for external supervision.