Command Palette
Search for a command to run...
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
Hyunsoo Cha Wonjung Woo Byungjun Kim Hanbyul Joo
Abstract
We present Vanast, a unified framework that generates garment-transferred human animation videos directly from a single human image, garment images, and a pose guidance video. Conventional two-stage pipelines treat image-based virtual try-on and pose-driven animation as separate processes, which often results in identity drift, garment distortion, and front-back inconsistency. Our model addresses these issues by performing the entire process in a single unified step to achieve coherent synthesis. To enable this setting, we construct large-scale triplet supervision. Our data generation pipeline includes generating identity-preserving human images in alternative outfits that differ from garment catalog images, capturing full upper and lower garment triplets to overcome the single-garment-posed video pair limitation, and assembling diverse in-the-wild triplets without requiring garment catalog images. We further introduce a Dual Module architecture for video diffusion transformers to stabilize training, preserve pretrained generative quality, and improve garment accuracy, pose adherence, and identity preservation while supporting zero-shot garment interpolation. Together, these contributions allow Vanast to produce high-fidelity, identity-consistent animation across a wide range of garment types.
One-sentence Summary
Researchers from Seoul National University propose Vanast, a unified framework that generates garment-transferred human animation videos in a single step using large-scale synthetic triplet supervision and a Dual Module architecture for video diffusion transformers to achieve high-fidelity, identity-consistent synthesis across diverse garment types.
Key Contributions
- The paper introduces Vanast, a unified framework that synthesizes garment-transferred human animation videos in a single step using a human image, garment images, and a pose guidance video. This approach avoids the identity drift and garment distortion common in conventional two-stage pipelines by performing the entire process through a single unified step.
- A large-scale triplet supervision dataset is constructed through a specialized data generation pipeline that captures identity-preserving human images, full upper and lower garment triplets, and diverse in-the-wild triplets. This data enables identity-preserving training and overcomes the limitations of existing single-garment-posed video pairs.
- The work presents a Dual Module architecture for video diffusion transformers that separates pose and garment conditioning into independent modules. This design improves garment fidelity, pose adherence, and identity preservation while supporting zero-shot garment interpolation and multi-garment transfer without finetuning.
Introduction
Virtual try-on technology is essential for digital fashion, yet existing two-stage pipelines that separate image-based try-on from pose-driven animation often suffer from identity drift, garment distortion, and temporal inconsistency. These traditional methods also struggle with front-back geometry when animating from a single static image. The authors leverage a unified, single-stage framework called Vanast to synthesize garment-transferred human animation videos directly from a human image, garment images, and a pose guidance video. To support this, they introduce a scalable triplet supervision pipeline that constructs training data from in-the-wild videos and identity-preserving synthetic images. Furthermore, the authors propose a Dual Module architecture for video diffusion transformers to stabilize training and improve garment accuracy, pose adherence, and identity preservation while enabling zero-shot garment interpolation.
Dataset
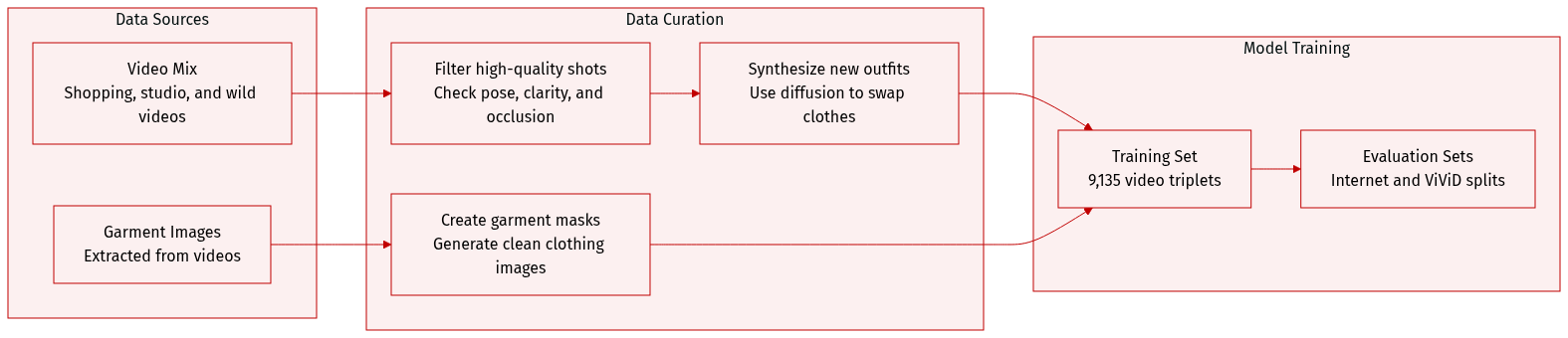
The authors introduce a synthetic triplet dataset generation pipeline to overcome the lack of publicly available data containing the necessary person-garment-video relationships.
-
Dataset Composition and Sources
- The training set consists of 9,135 videos, each between 3 and 10 seconds long.
- Sources include online shopping platforms, a custom-captured studio dataset for multi-garment scenarios, and in-the-wild videos from the ViViD dataset.
- Evaluation is conducted on two disjoint sets: an Internet dataset (shopping mall videos and garment images) and the ViViD test split.
-
Key Details and Processing Subsets
- Synthesized Triplets from Shopping Videos: The authors use a diffusion inpainting model (FLUX) to create target person images (IG′) wearing different garments. This involves selecting representative frames via a Vision-Language Model (VLM) based on face clarity, eye status, and image quality.
- In-the-wild Triplets: To increase diversity, the authors extract triplets directly from unconstrained videos. They generate garment images (G) by segmenting clothing from high-quality frames and applying random translations to prevent positional bias.
- Multi-garment Dataset: A specialized studio-captured dataset is used to support scenarios involving multiple garments for a single person.
-
Processing and Metadata Construction
- Frame Selection: A VLM (Qwen2.5-VL) filters frames based on frontal pose, lack of occlusion, and a quality score of at least 95/100.
- Inpainting Mask Generation: To ensure realistic garment synthesis, the authors avoid following the original garment silhouette. Instead, they use a text-to-image model to synthesize an auxiliary image with a different garment, then extract a mask from that image to guide the inpainting.
- Prompt Engineering: ChatGPT generates diverse garment descriptions, while a VLM ensures gender consistency by classifying the subject before incorporating the description into the prompt.
- Adaptive Cropping: The authors employ a face and body detection model to perform adaptive cropping. They use random linear interpolation between face and body bounding boxes to generate various scales, resulting in a final 9:16 aspect ratio crop.
Method
The authors leverage a dual-module architecture to enable single-stage human animation with garment transfer, designed to handle multiple conditioning inputs efficiently. The framework, named Vanast, takes as input a target garment image or set of garments G, a reference human image IG′ depicting the person wearing a different garment, a motion guidance video K, and a text prompt T. The goal is to generate a temporally coherent animation sequence V={ItG}t=1F, where each frame synthesizes the person wearing the target garments. To achieve this, the model employs a distributed and cascaded structure derived from the backbone text-to-video DiT model, partitioning the processing into two specialized modules: a Human Animation Module (HAM) and a Garment Transfer Module (GTM). This design addresses the limitations of single-context fusion, which can hinder convergence and make balancing multiple conditions difficult.
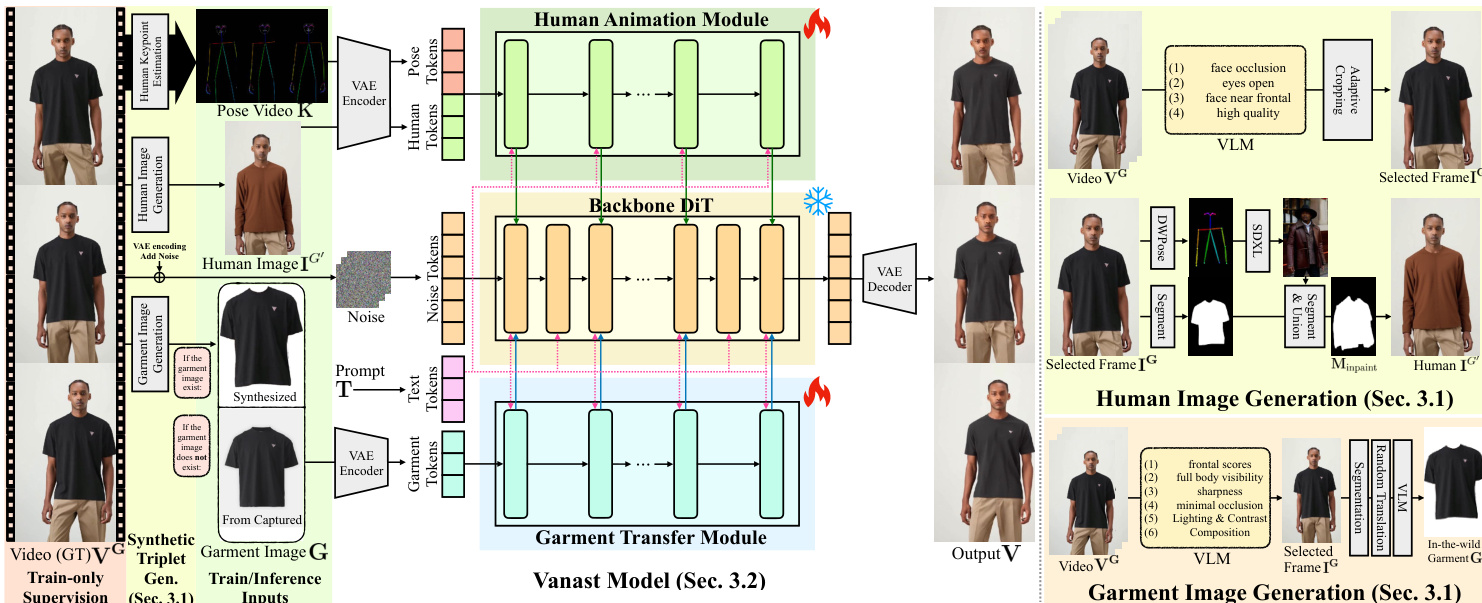
As shown in the figure below, the model architecture consists of a shared backbone DiT, with the HAM and GTM modules integrated at specific layers. The HAM processes human and pose information to generate the animation, while the GTM focuses on garment transfer. Both modules are integrated into the backbone in a cascaded manner, where the output of each transformer block hl is updated based on the backbone block BlT2V and the contributions from HAM and GTM. The integration is defined by the following equation:
hl+1={BlT2V(hl),BlT2V(hl)+α⋅BlHAM(hl)+β⋅BlGTM(hl),if l=2k,if l=2k.Here, l indexes the transformer block, k ranges from 0 to 14, and h represents the hidden state. The scalar values α=0.5 and β=0.5 control the relative contribution of the HAM and GTM modules during feature integration. The backbone DiT is frozen during training, and only the HAM and GTM modules are optimized, which reduces the computational burden and allows for efficient fine-tuning.
Input conditioning is handled through tokenization. The model uses a pretrained VAE encoder EVAE to convert the input components into latent representations. Specifically, zH, zG, and zP denote the encoded latents of the human image IG′, the garment image G, and the motion video K, respectively. For the HAM module, a motion-conditioned appearance context is formed by concatenating zH and zP along the temporal dimension. For the GTM module, the garment latent zG is used directly; to match the temporal dimension of the HAM input, a zero tensor is appended as a placeholder. These concatenated latent volumes are then projected into token embeddings using a 3D convolutional layer.
The framework further supports zero-shot garment interpolation. Given two garments GA and GB from the same category, the model can generate intermediate garments by computing a γ-weighted sum of their GTM outputs at each transformer block. The integration equation for this process is:
hl+1=BlT2V(hl)+α⋅BlHAM(hl)+γ⋅BlGTM(hl;GA)+(1−γ)⋅BlGTM(hl;GB),where γ∈[0,1] controls the interpolation ratio. This enables the generation of smooth and semantically consistent transitions between garments during the animation process. The overall framework is trained on a triplet dataset consisting of a reference human image, a target garment, and a ground truth animation video, with the motion sequence extracted using an off-the-shelf 2D keypoint estimator.
Experiment
The model is evaluated through comparisons against two-stage pipelines involving subject-to-image and virtual try-on baselines, as well as ablation studies to validate its architectural components and synthetic dataset. The results demonstrate that the proposed method achieves superior pose following, garment transfer accuracy, and identity preservation compared to existing approaches. Furthermore, the model exhibits strong versatility in zero-shot applications, including garment interpolation, simultaneous multiple garment transfer, and robust performance with in-the-wild images.
The authors conduct an ablation study to evaluate the impact of different model components and dataset configurations. Results show that the full model outperforms all variants across all metrics, with the single module baseline failing to control pose conditions and other variants struggling with accurate garment transfer. The full model achieves the best performance across all metrics compared to ablation variants. The single module baseline fails to accurately control pose conditions. Variants without synthetic human data or backbone LoRA struggle with accurate garment transfer.

The authors compare their method against various baselines using two datasets, showing superior performance across multiple metrics. Results indicate that their model outperforms all combinations of subject-to-image and animation models, as well as image virtual try-on and animation models, in most cases. Our model achieves the best performance across all metrics compared to baseline combinations. The model outperforms all methods on the Internet Dataset and most metrics on the ViViD Dataset. It shows strong performance in both subject-to-image and virtual try-on-based baselines.
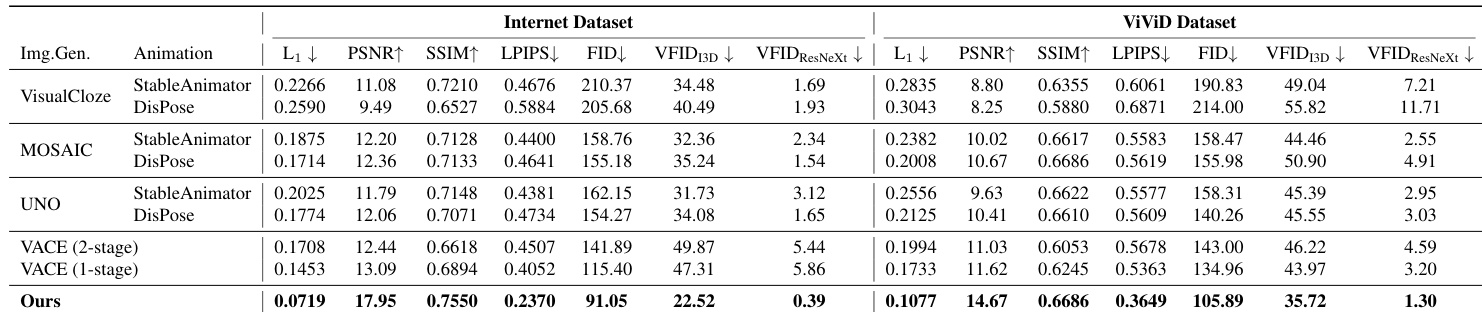
The authors compare their method with various baselines using two-stage pipelines combining image generation and animation models. Results show that their approach outperforms all baselines across multiple metrics on both datasets, achieving the best performance in most evaluations. Our method achieves the best performance across all metrics compared to baseline combinations. The model outperforms baselines on both Internet and ViVid datasets, with consistent improvements in key areas. Qualitative results confirm superior pose following, garment transfer, and identity preservation compared to all baselines.
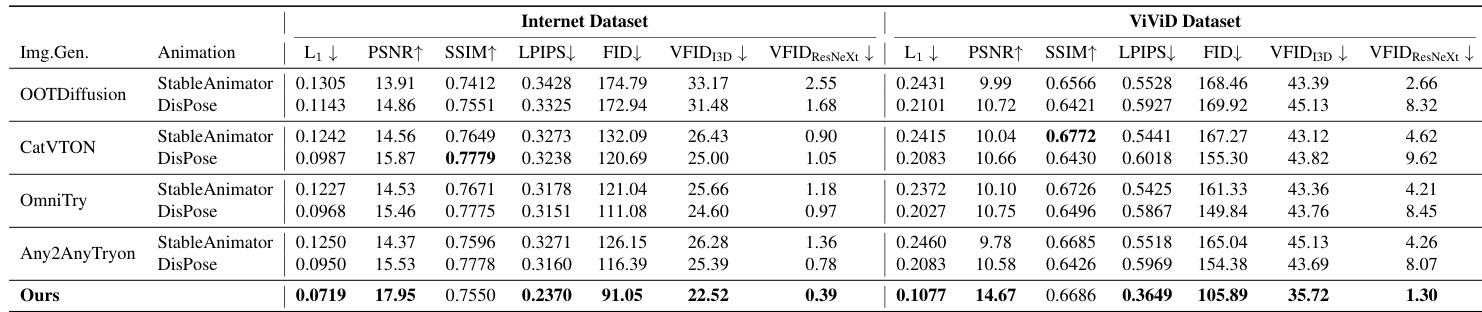
Through ablation studies and comparative evaluations against various baseline combinations, the authors validate the necessity of each model component and the overall effectiveness of their proposed method. The results demonstrate that the full model provides superior control over pose conditions and more accurate garment transfer than individual modules or two-stage pipelines. Ultimately, the approach achieves high performance across multiple datasets, showing significant improvements in pose following, garment transfer, and identity preservation.