Command Palette
Search for a command to run...
Learning to Retrieve from Agent Trajectories
Learning to Retrieve from Agent Trajectories
Yuqi Zhou Sunhao Dai Changle Qu Liang Pang Jun Xu Ji-Rong Wen
Abstract
Information retrieval (IR) systems have traditionally been designed and trained for human users, with learning-to-rank methods relying heavily on large-scale human interaction logs such as clicks and dwell time. With the rapid emergence of large language model (LLM) powered search agents, however, retrieval is increasingly consumed by agents rather than human beings, and is embedded as a core component within multi-turn reasoning and action loops. In this setting, retrieval models trained under human-centric assumptions exhibit a fundamental mismatch with the way agents issue queries and consume results. In this work, we argue that retrieval models for agentic search should be trained directly from agent interaction data. We introduce learning to retrieve from agent trajectories as a new training paradigm, where supervision is derived from multi-step agent interactions. Through a systematic analysis of search agent trajectories, we identify key behavioral signals that reveal document utility, including browsing actions, unbrowsed rejections, and post-browse reasoning traces. Guided by these insights, we propose LRAT, a simple yet effective framework that mines high-quality retrieval supervision from agent trajectories and incorporates relevance intensity through weighted optimization. Extensive experiments on both in-domain and out-of-domain deep research benchmarks demonstrate that retrievers trained with LRAT consistently improve evidence recall, end-to-end task success, and execution efficiency across diverse agent architectures and scales. Our results highlight agent trajectories as a practical and scalable supervision source, pointing to a promising direction for retrieval in the era of agentic search.
One-sentence Summary
To address the misalignment between human-centric retrieval models and agentic search, researchers from Renmin University of China and the Chinese Academy of Sciences propose LRAT, a framework that optimizes retrievers by mining high-quality supervision from agent trajectories—specifically through browsing actions, unbrowsed rejections, and post-browse reasoning traces—to enhance evidence recall, task success, and execution efficiency across diverse agent architectures and scales.
Key Contributions
- This work formalizes a new training paradigm called learning to retrieve from agent trajectories, which derives supervision directly from multi-step agent interaction data rather than human-centric logs.
- The paper introduces LRAT, a framework that converts agent trajectories into high-quality retrieval supervision by mining behavioral signals such as browsing actions, unbrowsed rejections, and post-browse reasoning traces.
- Extensive experiments on in-domain and out-of-domain deep research benchmarks demonstrate that LRAT improves evidence recall, end-to-end task success, and execution efficiency across various agent architectures and scales.
Introduction
As large language model (LLM) powered agents increasingly perform complex, multi-turn reasoning tasks, retrieval has shifted from a standalone service for humans to a core component of autonomous agent loops. Traditional retrieval models are trained on human centric data, such as clicks and dwell time, which creates a fundamental mismatch because agent queries are driven by intermediate reasoning objectives rather than immediate informational needs. To bridge this gap, the authors propose a new training paradigm called Learning to Retrieve from Agent Trajectories (LRAT). The authors leverage multi-step agent interaction data to mine high-quality supervision signals, such as browsing actions, unbrowsed rejections, and post-browse reasoning traces. This framework allows for the training of retrievers that are directly aligned with agent behaviors, improving evidence recall and task success across various architectures.
Dataset
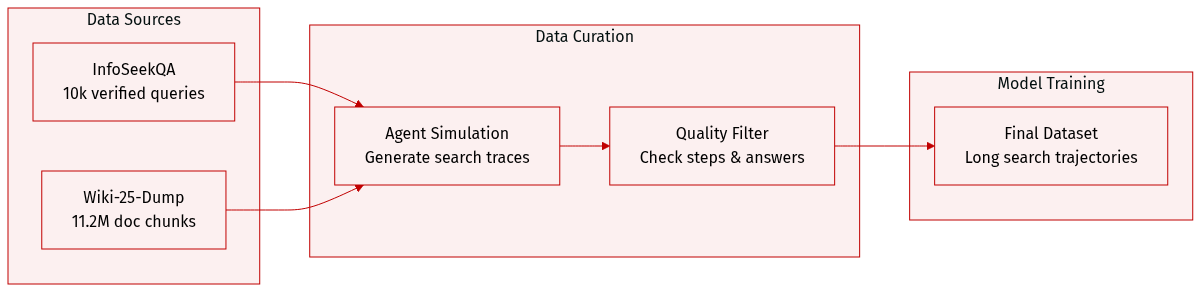
The authors construct a specialized dataset of agent trajectories designed to model sustained search and browsing behavior through the following process:
- Dataset Composition and Sources: The authors utilize InfoSeekQA as the foundational seed dataset. This benchmark contains over 50,000 question-answer pairs that require hierarchical reasoning and iterative information acquisition. For the underlying knowledge base, they use the Wiki-25-Dump corpus, which consists of more than 11.2 million document chunks.
- Subset Details and Filtering: From the initial InfoSeekQA pool, the authors select a seed set of the top 10,000 queries that feature verified ground-truth answers. To ensure data quality, they filter out any generated trajectories that exceed the maximum step limit or result in incorrect final answers. Answer correctness is validated by comparing agent outputs against the ground truth using the Qwen3-30B-A3B-Thinking-2507 model.
- Data Processing and Trajectory Generation: The authors generate trajectories by executing a search agent on each seed query within a simulated environment. During execution, the agent produces reasoning traces and performs [Search] or [Browse] actions. For the corpus, document chunks are truncated to a fixed length of 512 tokens.
- Model Usage: The resulting trajectories, which capture deep search processes and long interaction sequences, serve as the primary data for the authors' analysis.
Method
The authors leverage a framework for training retrieval models directly from deep research agent trajectories, referred to as LRAT. This approach is designed to capture the nuanced ways in which agents interact with external information systems, using these interactions to generate high-quality, utility-aware training signals. The overall framework operates in three key stages: relevance signal mining, reasoning-aware positive filtering, and intensity-aware training.
The process begins with the generation of deep research agent trajectories. As shown in the figure below, an agent starts with an initial user query q and proceeds through a series of iterative reasoning and action steps. At each turn t, the agent produces a reasoning state rt, which guides its action at. The agent can perform either a [Search] action, generating an intermediate query qt and receiving a ranked list of candidate documents Dt, or a [Browse] action, which retrieves the full content of a previously identified document dt. The agent's reasoning state is updated with the observed information ot from the retrieval system. This cycle continues until the agent determines that sufficient information has been gathered to generate a final answer y. The trajectory captures the agent's decision-making process, including its information needs, retrieval choices, and information consumption.
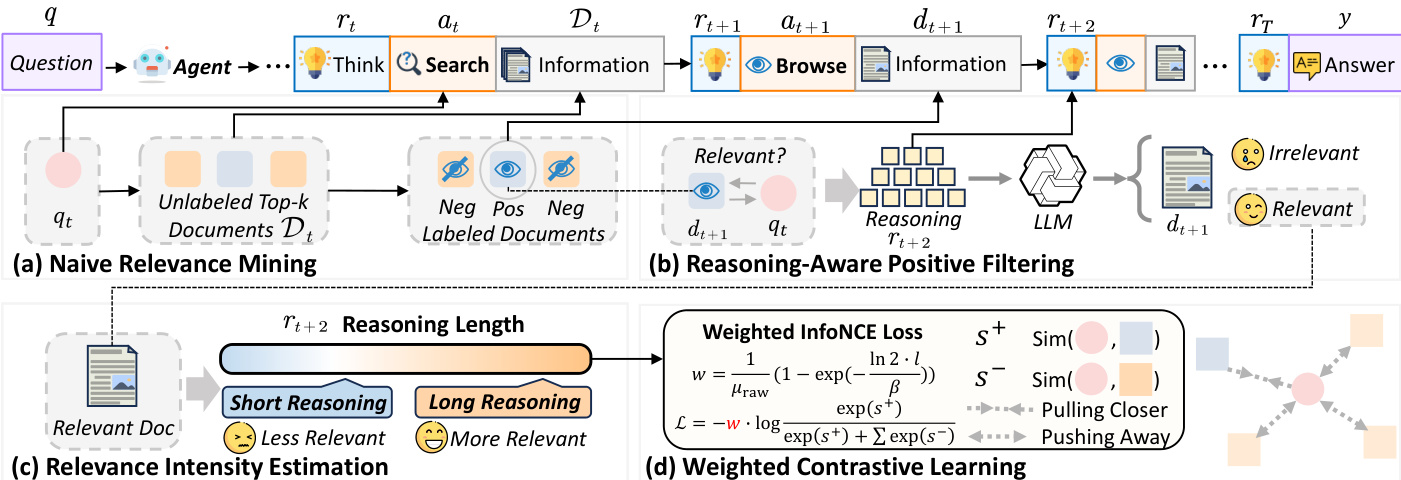
The first stage of the LRAT framework is relevance signal mining. The authors start by constructing coarse supervision from the agent's [Search] → [Browse] transitions. For a search turn t, if the agent subsequently browses a document dt+1 at turn t+1, that document is considered a naive positive sample. All other documents in the same retrieved set that are not browsed are treated as naive negatives, forming a training instance (qt,dt+1,Nt). However, browsing actions are imperfect indicators of relevance, as agents may browse documents that ultimately prove unhelpful. To refine these positives, the authors introduce a reasoning-aware filtering step. They use a large language model (LLM) as a judge to analyze the agent's reasoning trace rt+2 immediately following the browsing action. The LLM determines whether the reasoning explicitly uses the content of the browsed document to make progress on the task, thereby filtering out noisy, browsed-but-unhelpful documents while preserving high-quality positive examples.
The final stage of the framework is intensity-aware training. The authors recognize that agent trajectories not only indicate relevance but also reveal the intensity of relevance. They propose an estimation scheme based on the length of the agent's post-browse reasoning trace. The analysis shows that longer reasoning chains following a browsing action are strongly correlated with higher document usefulness, analogous to human dwell time in search. To model this, they use an exponential saturation function to map the reasoning length l to a bounded utility score. The relevance intensity weight w is computed as w=μraw1(1−exp(−βln2⋅l)), where β is the median reasoning length across all trajectories and μraw is the global mean of the unnormalized scores. This weight is then used in a weighted contrastive learning objective, where the loss function penalizes the model more heavily for incorrectly ranking documents with high relevance intensity. The overall process involves updating the retriever model iteratively based on these intensity-weighted signals, resulting in a retrieval system that is better aligned with the actual utility of documents in the context of complex information-seeking tasks.
Experiment
The researchers evaluate the LRAT framework by analyzing deep research agent trajectories to determine how browsing behavior and post-browse reasoning indicate document utility. By training retrievers using these trajectory-derived signals, the study validates that browsing is a necessary condition for task success and that reasoning length serves as a reliable proxy for relevance. Experimental results across diverse agent architectures and benchmarks demonstrate that this approach consistently improves evidence recall, increases task success rates, and enhances execution efficiency by reducing unnecessary interaction steps.
The authors evaluate the LRAT framework on multiple agent backbones, showing consistent improvements in success rate when using both correct and incorrect trajectories for training. Results indicate that leveraging agent interaction data enhances retrieval quality and task performance across different models. LRAT improves success rates across all evaluated agents using both correct and incorrect trajectories. Training with incorrect trajectories still yields significant gains, suggesting useful supervision from failed interactions. The improvements are consistent across different agent scales, indicating broad effectiveness of the approach.

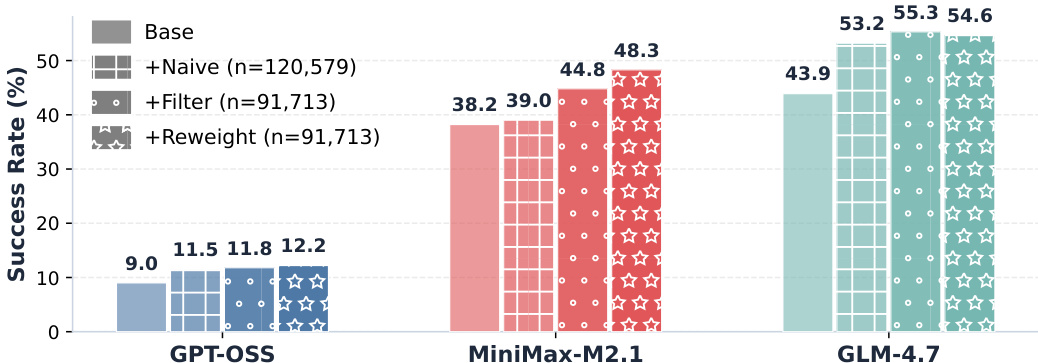
The authors compare the success rates of different large language models when using various retrieval methods. Results show that the proposed method consistently improves success rates across all models, with the most significant gains observed in the MiniMax-M2.1 and GLM-4.7 systems. The improvements are attributed to enhanced retrieval quality and more efficient agent execution. The proposed method consistently improves success rates across all evaluated models. The largest gains are observed in the MiniMax-M2.1 and GLM-4.7 systems. Improved performance is attributed to better retrieval quality and more efficient agent execution.
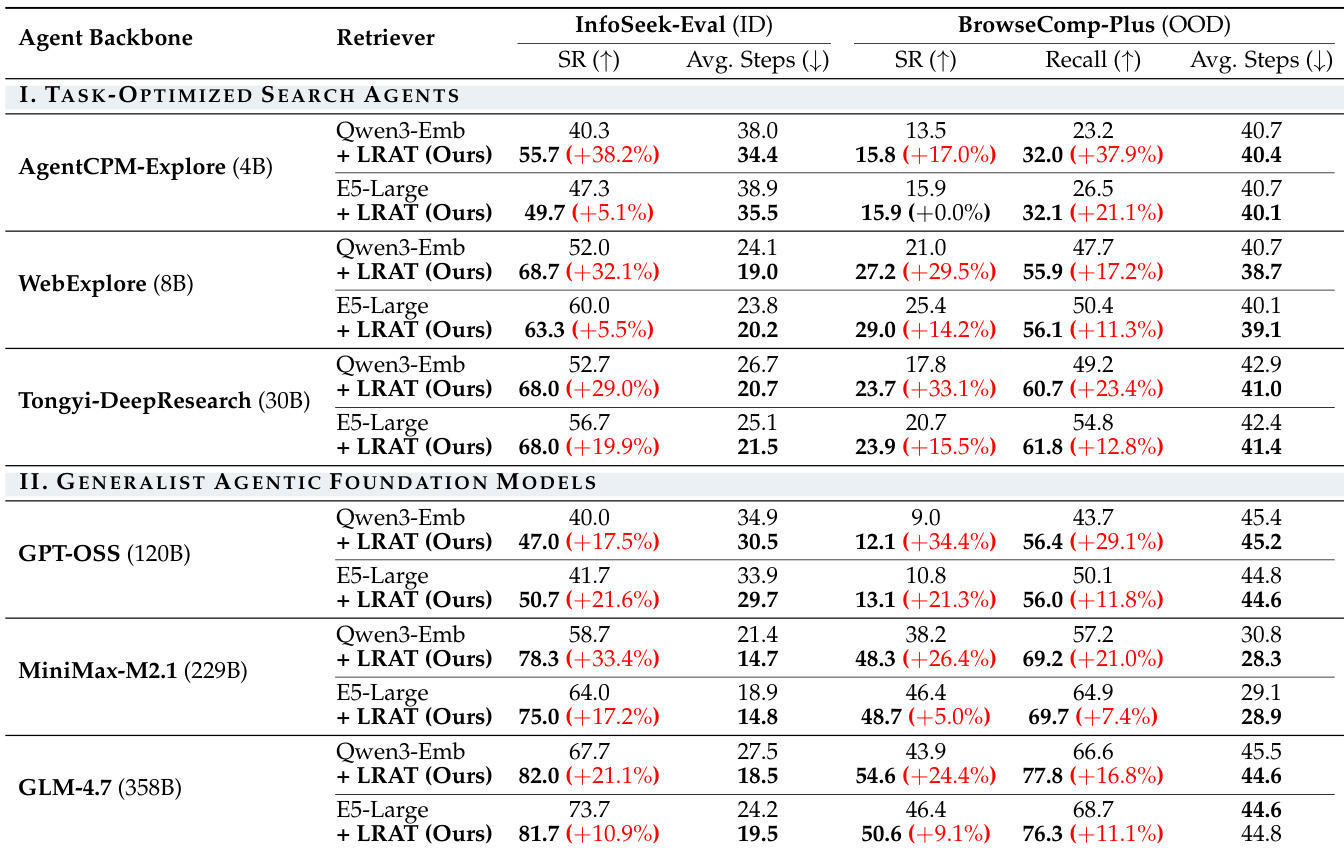
The authors evaluate the LRAT framework on multiple search agents and retrievers, showing consistent improvements in task success and retrieval quality. Results demonstrate that the approach enhances performance across different agent scales and retrieval models, particularly in in-domain and out-of-domain benchmarks. LRAT consistently improves success rate and evidence recall across all agent and retriever configurations. The framework reduces the average number of steps required for task completion, indicating more efficient agent execution. Performance gains are observed across diverse architectures, including both task-optimized and generalist agents.
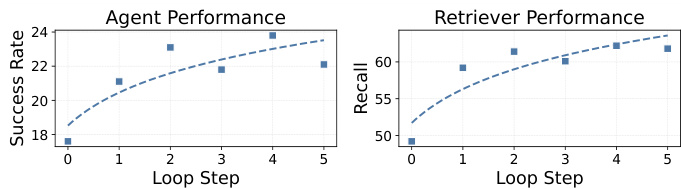
The graphs show performance trends as the number of interaction loops increases. Agent success rate improves with more steps, while retriever recall also increases, indicating better evidence retrieval over time. Both metrics show consistent gains across loop steps, suggesting that additional interaction contributes to better outcomes. Agent success rate increases with more interaction loops Retriever recall improves as the number of loops increases Both agent and retriever performance show consistent gains over multiple steps
The authors compare the success rates of various agents using different retrievers, showing that the proposed LRAT method consistently improves performance across all agents. Results indicate that LRAT enhances task success, reduces the number of required steps, and improves evidence retrieval, with gains observed in both in-domain and out-of-domain benchmarks. LRAT consistently improves success rates across all agents on both benchmarks. The method reduces the average number of interaction steps required to complete tasks. LRAT enhances evidence retrieval quality, leading to better end-to-end performance.
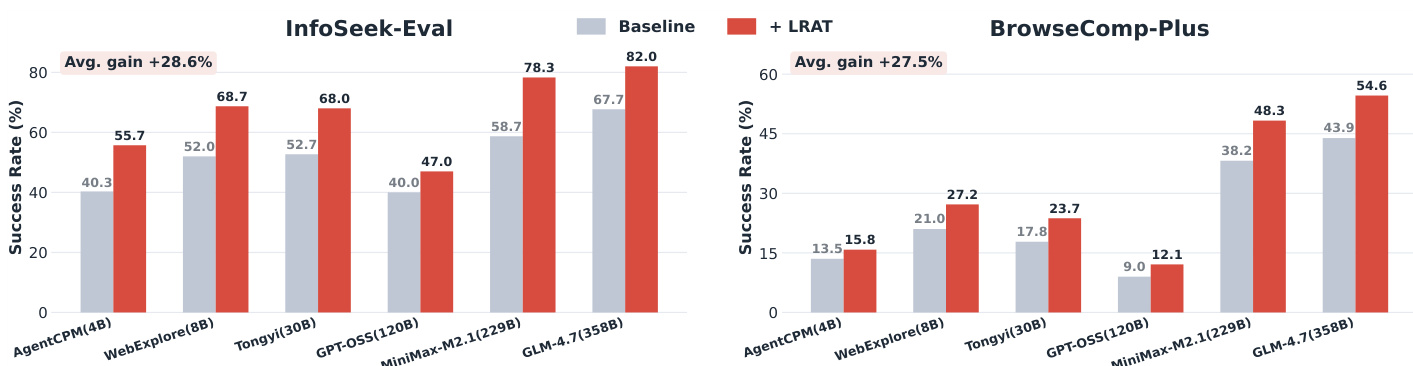
The authors evaluate the LRAT framework across various agent backbones, retriever configurations, and task domains to validate its effectiveness in enhancing task success and retrieval quality. The results demonstrate that leveraging both correct and incorrect interaction trajectories consistently improves performance and reduces the number of steps required for task completion. Ultimately, the framework shows broad applicability across different agent scales and architectures, providing significant gains in both in-domain and out-of-domain benchmarks.