Command Palette
Search for a command to run...
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Abstract
With the rapid advancement of video understanding, existing benchmarks are becoming increasingly saturated, exposing a critical discrepancy between inflated leaderboard scores and real-world model capabilities. To address this widening gap, we introduce Video-MME-v2, a comprehensive benchmark designed to rigorously evaluate the robustness and faithfulness of video understanding. To systematically evaluate model capabilities, we design a progressive tri-level hierarchy that incrementally increases the complexity of video comprehension, ranging from multi-point visual information aggregation, to temporal dynamics modeling, and ultimately to complex multimodal reasoning. Besides, in contrast to conventional per-question accuracy, we propose a group-based non-linear evaluation strategy that enforces both consistency across related queries and coherence in multi-step reasoning. It penalizes fragmented or guess-based correctness and assigns credit only to answers supported by valid reasoning. To guarantee data quality, Video-MME-v2 is constructed through a rigorously controlled human annotation pipeline, involving 12 annotators and 50 independent reviewers. Backed by 3,300 human-hours and up to 5 rounds of quality assurance, Video-MME-v2 aims to serve as one of the most authoritative video benchmarks. Extensive experiments reveal a substantial gap between current best model Gemini-3-Pro and human experts, and uncover a clear hierarchical bottleneck where errors in visual information aggregation and temporal modeling propagate to limit high-level reasoning. We further find that thinking-based reasoning is highly dependent on textual cues, improving performance with subtitles but sometimes degrading it in purely visual settings. By exposing these limitations, Video-MME-v2 establishes a demanding new testbed for the development of next-generation video MLLMs.
One-sentence Summary
To bridge the gap between inflated leaderboard scores and real-world capabilities, the Video-MME Team introduces Video-MME-v2, a comprehensive benchmark that utilizes a progressive tri-level hierarchy of increasing complexity and a novel group-based non-linear evaluation strategy to rigorously assess the robustness, consistency, and reasoning coherence of video understanding models.
Key Contributions
- This work introduces Video-MME-v2, a comprehensive benchmark designed to evaluate the robustness and faithfulness of video multimodal large language models through a progressive tri-level hierarchy. This hierarchy incrementally increases task complexity from multi-point visual information aggregation to temporal dynamics modeling and complex multimodal reasoning.
- The paper presents a group-based non-linear evaluation strategy that replaces conventional per-question accuracy to assess both consistency across related queries and coherence in multi-step reasoning. This method penalizes fragmented or guess-based answers and only assigns credit to responses supported by valid reasoning.
- The researchers developed a high-quality dataset using a rigorously controlled human annotation pipeline involving 12 annotators and 50 independent reviewers. The construction process included 3,300 human-hours and up to five rounds of quality assurance to ensure the benchmark serves as an authoritative evaluation standard.
Introduction
As video multimodal large language models (MLLMs) advance, existing benchmarks are becoming saturated, leading to inflated leaderboard scores that do not reflect real-world performance. Current evaluation methods often focus on narrow, domain-specific tasks or elementary capabilities, failing to deeply investigate the connection between perception and complex reasoning. To address these gaps, the authors introduce Video-MME-v2, a rigorous benchmark featuring a progressive tri-level hierarchy that scales from basic visual information aggregation to complex multimodal reasoning. The authors also propose a group-based non-linear evaluation strategy that penalizes fragmented or guess-based answers by requiring consistency across related queries and coherence in multi-step reasoning.
Dataset

-
Dataset Composition and Sources The authors constructed Video-MME-v2 using 800 videos sourced from the internet. To ensure high quality, they applied a view-count thresholding strategy, filtering out low-exposure content; specifically, 84.3% of the videos have over 10,000 views. The content is organized into four top-level domains: Sports and Competition, Lifestyle and Entertainment, Art and Literature, and Knowledge and Education, which are further divided into 31 fine-grained subcategories.
-
Hierarchical Capability Levels The dataset is structured into three progressive levels of difficulty:
- Level 1 (Visual Information Aggregation): Focuses on foundational tasks like visual recognition, cross-modal consistency (audio-visual alignment), and basic counting.
- Level 2 (Temporal Dynamics): Evaluates the ability to analyze action and motion, determine sequential ordering, and perform causal reasoning.
- Level 3 (Complex Reasoning): Requires high-level cognitive skills including narrative understanding, social dynamics analysis, and physical world reasoning.
-
Data Processing and Decontamination To prevent pre-training leakage and ensure the benchmark tests true reasoning rather than memorization, the authors employed several strategies:
- Recency-Oriented Curation: Over 80% of the videos were published in 2025 or later, with nearly 40% published after October 2025.
- Manual Decontamination: Annotators manually screened and excluded classic films, television works, and flagship influencer content.
- Text-Only Baseline Testing: The authors used frontier models in text-only mode to identify and remove questions that could be solved without visual information, ensuring strong multimodal dependence.
-
Annotation and Question Design The dataset was developed through 3,300 human-hours of work involving 12 annotators and 50 reviewers. Each video is paired with 4 questions, and each question features an 8-option multiple-choice format to reduce random guessing probability to 12.5%. The authors implemented a group-based construction where question and answer lengths progressively increase from Q1 to Q4 to create logical chains of increasing depth. To prevent models from exploiting statistical shortcuts, the word count across all eight options is kept highly consistent. Additionally, each question includes at least one adversarial distractor designed to challenge fine-grained perception.
Method
The authors design a comprehensive evaluation framework that organizes video understanding tasks into structured question groups to assess both consistency and coherence in model reasoning. The framework is structured into three hierarchical levels: L1, L2, and L3, each capturing different aspects of video comprehension. At the core of the evaluation is the L1 level, labeled "Retrieval & Aggregation," which focuses on foundational perception tasks such as object localization, visual recognition, and basic counting. This level serves as the baseline for retrieving and aggregating visual and auditory information from the input video.
Extending from L1, the L2 level, "Temporal Understanding," encompasses more complex spatio-temporal reasoning, including action and motion analysis, order inference, and change detection. This level evaluates a model’s ability to track events across time and understand temporal dependencies, such as the sequence of actions in a fitness tutorial or the progression of a character’s movement. The L3 level, "Complex Reasoning," represents the highest tier of comprehension, integrating higher-order cognitive tasks such as physical world reasoning, social behavior analysis, and narrative understanding. This layer assesses reasoning capabilities that require synthesizing multiple cues across the video, such as inferring intent from behavioral patterns or analyzing the logic of a plot.
The framework is further enriched by two types of question groups: consistency-based and coherence-based. Consistency-based groups are designed to evaluate a model's reliability across different question formulations within the same domain, ensuring robustness in reasoning. These groups span two dimensions: breadth, which introduces diverse question types within a single domain to assess multiple reasoning aspects (e.g., object localization and relative motion in spatial understanding), and granularity, which varies the spatio-temporal scale of questions to test both holistic and fine-grained comprehension. This dual-dimensional design enables a systematic evaluation of a model’s understanding across different levels of detail.
Coherence-based groups, on the other hand, are structured to assess the logical progression of a model’s reasoning in complex tasks. These groups are constructed to mirror the step-by-step reasoning process a human would use, with questions arranged in a hierarchical sequence that begins with clue localization, proceeds to anomaly verification, and culminates in a final conclusion. For example, in a plot analysis task involving deception, the questions guide the model through identifying visual cues of a staged death, detecting inconsistencies, inferring the motive behind the act, and finally drawing a conclusion based on the accumulated evidence. This structured progression ensures that the model demonstrates genuine, interpretable reasoning rather than relying on superficial pattern matching.
Experiment
The Video-MME-v2 benchmark evaluates video multimodal large language models through a multi-level hierarchy and a group-based evaluation strategy designed to measure capability consistency and reasoning coherence. Experiments across commercial and open-source models reveal a significant performance gap compared to human experts and identify a hierarchical bottleneck where failures in low-level perception and temporal modeling cascade into poor high-level reasoning. Findings suggest that while larger scales and thinking modes can improve performance, current models often over-rely on language priors and lack the robust, integrated capabilities required for complex, real-world video comprehension.
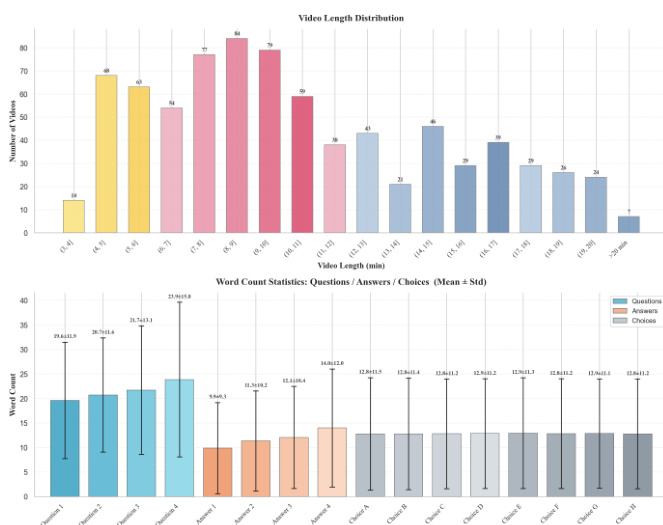
The chart displays the distribution of video lengths and word counts for questions, answers, and choices in the benchmark. Results show that videos vary significantly in duration, with a peak in the 2-3 minute range, and that questions and answers have similar average word counts, while choices are shorter. Video lengths vary widely, with a concentration in the 2-3 minute range. Questions and answers have comparable average word counts, while choices are shorter. The dataset includes videos of different durations, indicating diverse content complexity.
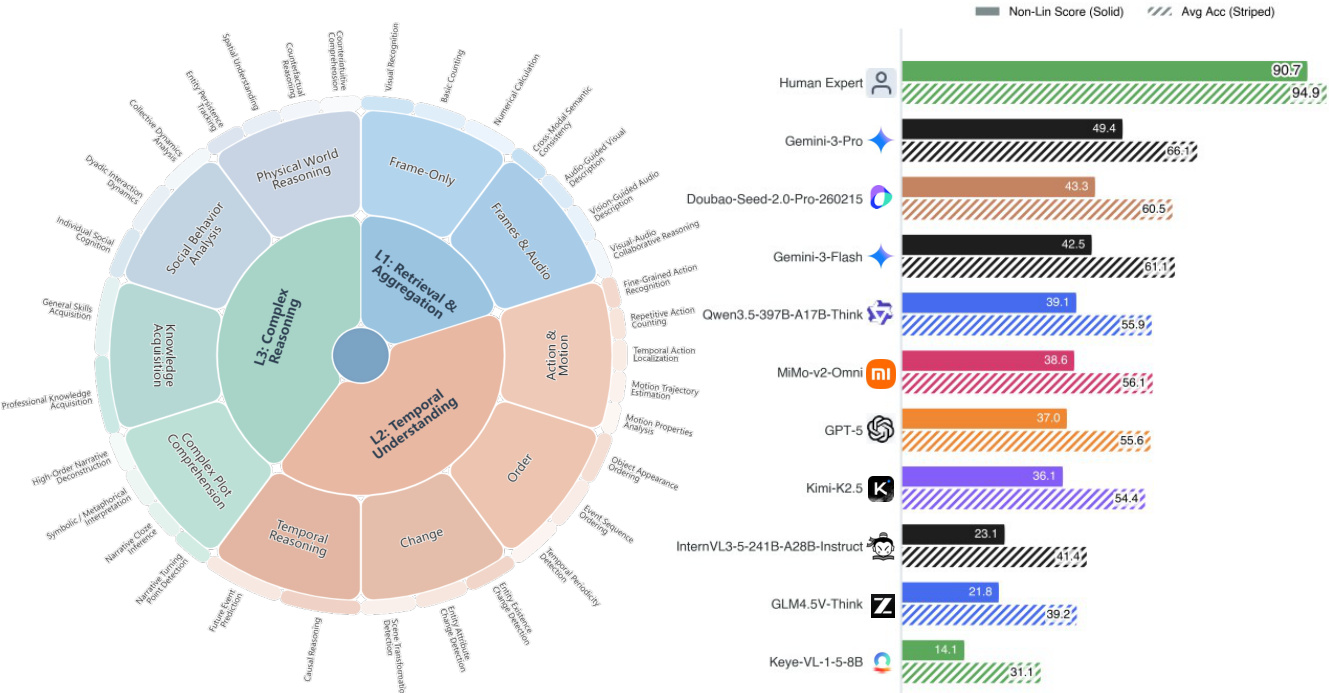
The authors present a comprehensive evaluation of video multimodal large language models using the Video-MME-v2 benchmark, which employs a multi-level hierarchy and group-based scoring to assess robustness and faithfulness. Results show a significant performance gap between human experts and current models, with the best models achieving only about half of the human score, and a clear hierarchical bottleneck where lower-level failures impede higher-level reasoning. The best-performing model achieves a score substantially lower than human experts, highlighting a significant gap in robust video understanding. Performance degrades monotonically across the evaluation hierarchy, indicating that errors in foundational perception and temporal modeling propagate to complex reasoning. Models exhibit a large discrepancy between per-question accuracy and group-based nonlinear scores, suggesting a lack of consistent performance across correlated queries.
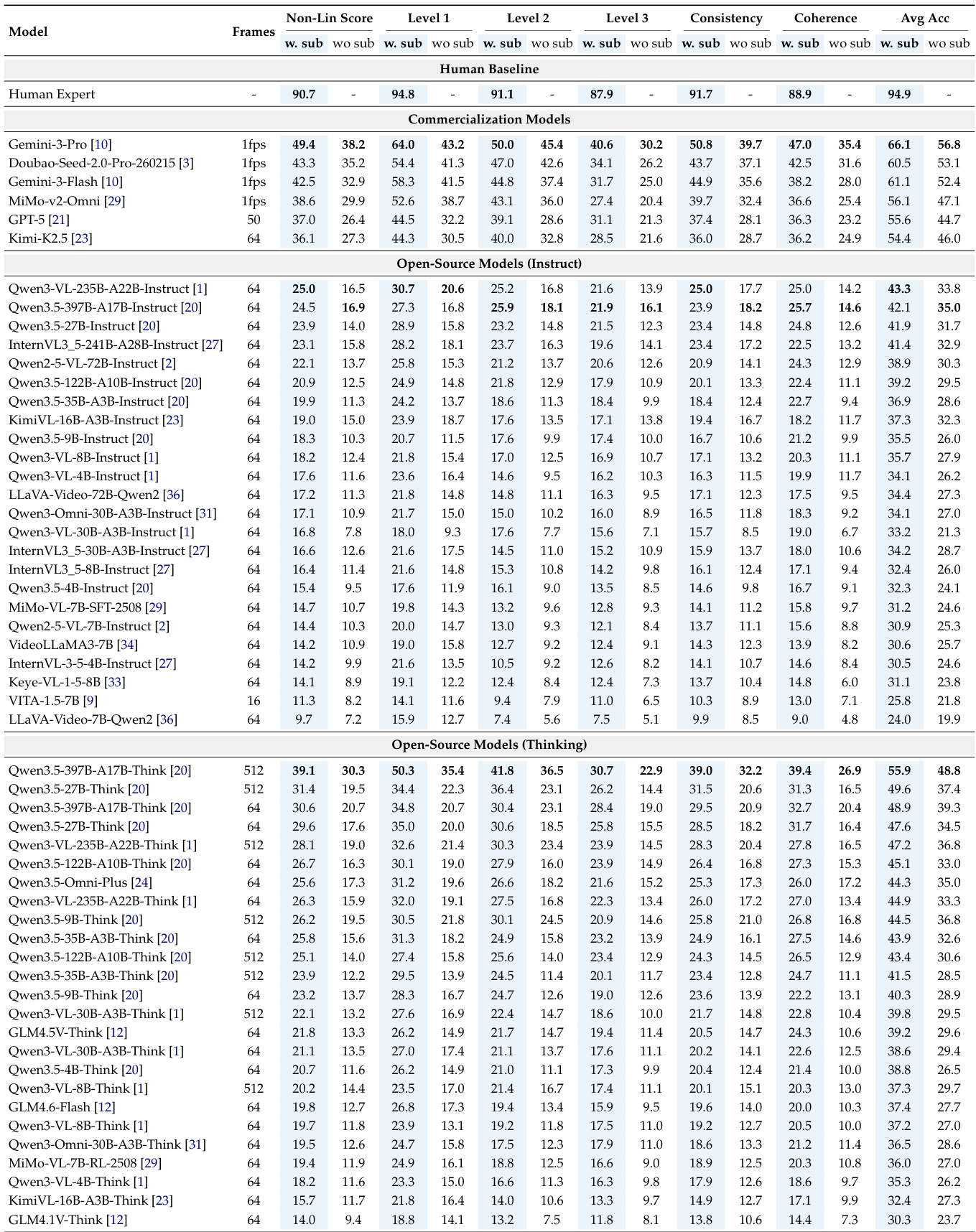
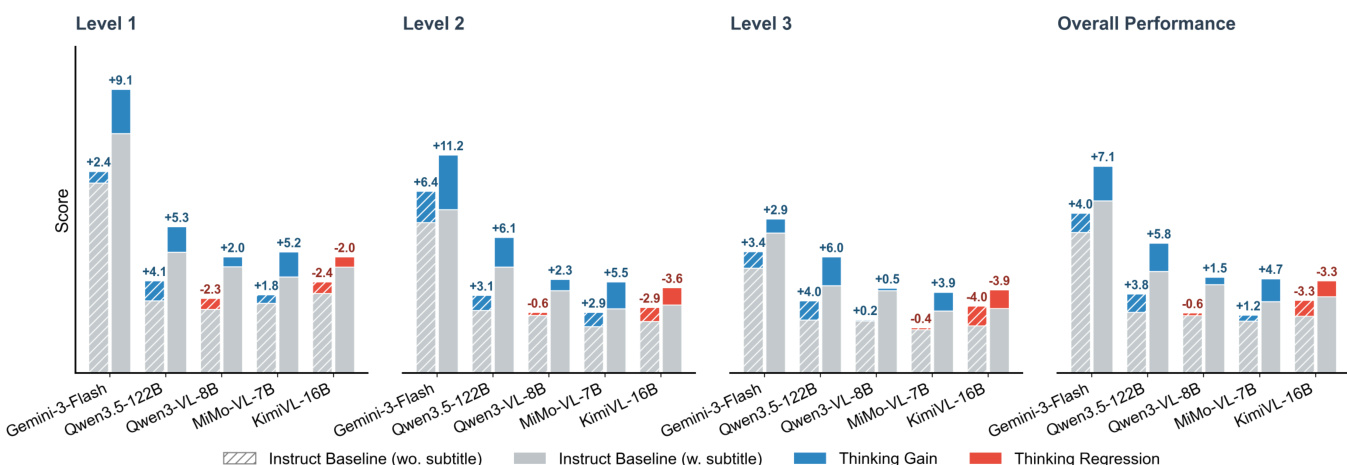
The experiment evaluates video MLLMs across three progressive levels of understanding, from basic information aggregation to complex reasoning. Results show a consistent performance drop from Level 1 to Level 3, with significant gaps between models and human experts, highlighting hierarchical bottlenecks in video comprehension. The overall performance is influenced by capability consistency and reasoning coherence, where models often struggle with sustained logical chains. Performance degrades monotonically from Level 1 to Level 3 across all models, indicating hierarchical bottlenecks in video understanding. The best-performing model shows a substantial gap compared to human experts, particularly in complex reasoning tasks. Enabling thinking mode improves performance with subtitles but can cause regression without textual cues, revealing over-reliance on language priors.
The authors evaluate state-of-the-art video MLLMs using a comprehensive benchmark that includes both per-question accuracy and a group-based nonlinear score to assess capability consistency and reasoning coherence. Results show a significant performance gap between models and human experts, with the best model achieving a nonlinear score of 49.4 compared to a human baseline of 90.7, and highlight that even top models struggle with consistent performance across related questions. The best-performing model achieves a nonlinear score of 49.4, significantly below the human baseline of 90.7, indicating a substantial gap in robust video comprehension. Per-question accuracy overestimates model capability, as evidenced by the large drop in nonlinear scores for top models, revealing inconsistent performance across related questions. The performance gap between models and humans is most pronounced in complex reasoning tasks, with all models showing substantial room for improvement in advanced video understanding.
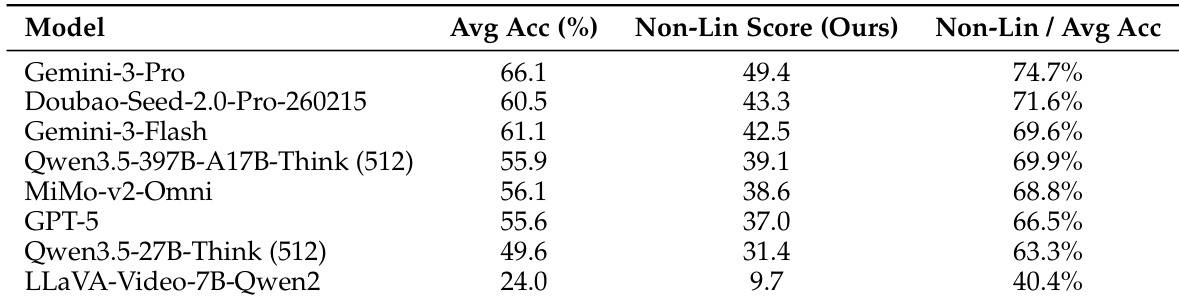
The authors present a comprehensive evaluation of video multimodal large language models using a multi-level framework that assesses foundational perception, temporal modeling, and complex reasoning. Results show significant performance gaps between models and human experts, with the best model achieving a nonlinear score of 49.4, indicating substantial room for improvement in robust and consistent video understanding. The best-performing model achieves a nonlinear score of 49.4, highlighting a large gap compared to human experts at 90.7. Models with complete capability profiles across omni-modal perception, long-context modeling, and complex reasoning generally perform better. Increasing frame count improves performance, underscoring the importance of long-context processing for complex video understanding.
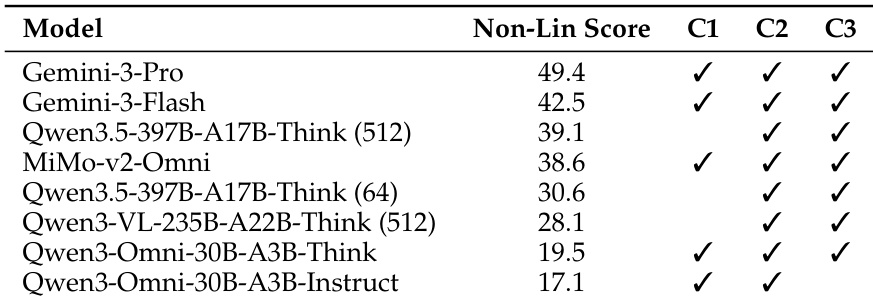
The evaluation utilizes the Video-MME-v2 benchmark to assess video multimodal large language models across varying video lengths and hierarchical levels of understanding, ranging from basic perception to complex reasoning. Results reveal a significant performance gap between current models and human experts, characterized by a monotonic decline in accuracy as task complexity increases. The findings highlight a hierarchical bottleneck where failures in foundational temporal modeling impede higher-level reasoning, while also exposing an over-reliance on language priors and a lack of consistency across related queries.