Command Palette
Search for a command to run...
QuanBench+: A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation
QuanBench+: A Unified Multi-Framework Benchmark for LLM-Based Quantum Code Generation
Ali Slim Haydar Hamieh Jawad Kotaich Yehya Ghosn Mahdi Chehimi Ammar Mohanna Hasan Abed Al Kader Hammoud Bernard Ghanem
Abstract
Large Language Models (LLMs) are increasingly used for code generation, yet quantum code generation is still evaluated mostly within single frameworks, making it difficult to separate quantum reasoning from framework familiarity. We introduce QuanBench+, a unified benchmark spanning Qiskit, PennyLane, and Cirq, with 42 aligned tasks covering quantum algorithms, gate decomposition, and state preparation. We evaluate models with executable functional tests, report Pass@1 and Pass@5, and use KL-divergence-based acceptance for probabilistic outputs. We additionally study Pass@1 after feedback-based repair, where a model may revise code after a runtime error or wrong answer. Across frameworks, the strongest one-shot scores reach 59.5% in Qiskit, 54.8% in Cirq, and 42.9% in PennyLane; with feedback-based repair, the best scores rise to 83.3%, 76.2%, and 66.7%, respectively. These results show clear progress, but also that reliable multi-framework quantum code generation remains unsolved and still depends strongly on framework-specific knowledge.
One-sentence Summary
To evaluate LLM-based quantum code generation, the authors introduce QuanBench+, a unified benchmark spanning Qiskit, PennyLane, and Cirq that utilizes 42 aligned tasks and executable functional tests to demonstrate that while feedback-based repair improves Pass@1 and Pass@5 scores, reliable multi-framework quantum reasoning remains an unsolved challenge.
Key Contributions
- This work introduces QuanBench+, a unified benchmark that evaluates quantum code generation across three distinct frameworks: Qiskit, PennyLane, and Cirq. The benchmark consists of 42 aligned tasks covering quantum algorithms, gate decomposition, and state preparation to differentiate between portable quantum reasoning and framework-specific knowledge.
- The researchers implement an executable functional evaluation method that defines correctness based on task success through measurement statistics. This approach utilizes Pass@k metrics and KL-divergence-based acceptance for probabilistic outputs to ensure that functionally equivalent but syntactically different circuits are correctly identified as valid.
- The study provides a comprehensive analysis of model performance through both one-shot generation and feedback-based repair. Results demonstrate that while one-shot scores reach up to 59.5% in Qiskit, the application of feedback-based repair significantly improves performance, with the highest scores rising to 83.3% in Qiskit, 76.2% in Cirq, and 66.7% in PennyLane.
Introduction
As quantum computing moves toward practical software applications, Large Language Models (LLMs) are increasingly used to automate code generation across various ecosystems like Qiskit, PennyLane, and Cirq. Current benchmarks typically focus on a single framework, which makes it difficult to determine if a model's failure stems from poor quantum reasoning or a simple lack of familiarity with a specific API. The authors introduce QuanBench+, a unified multi-framework benchmark that holds task intent constant across 42 aligned tasks to isolate these two failure modes. By utilizing executable functional tests and KL-divergence based acceptance for probabilistic outputs, the authors provide a standardized way to evaluate whether models possess portable quantum reasoning or merely framework-specific knowledge.
Dataset
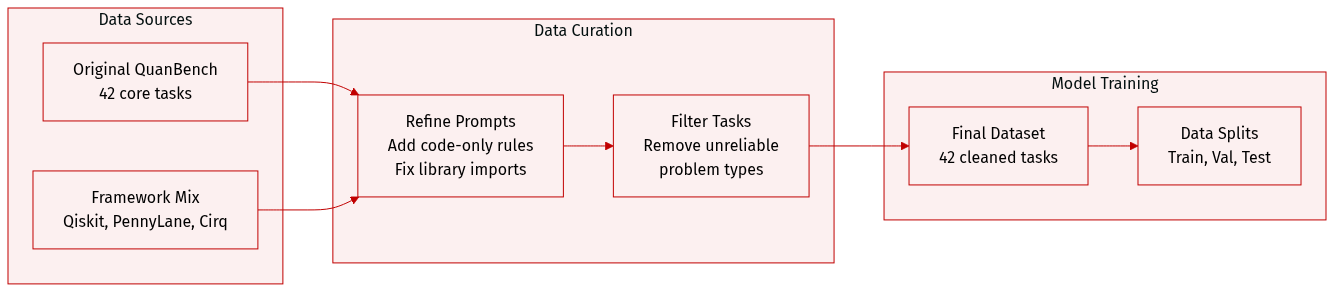
The authors utilize QuanBench+, a dataset derived from the original QuanBench task set. The dataset is structured as follows:
- Composition and Categories: The benchmark consists of 42 tasks organized into three distinct categories: Quantum Algorithms, Gate Decomposition, and State Preparation.
- Sources and Adaptation: The authors adapted the original tasks to three specific quantum computing frameworks: Qiskit, PennyLane, and Cirq. This adaptation involved modifying prompts to align with framework-specific APIs and library conventions.
- Filtering and Refinement: To ensure reliable cross-framework grading, the authors removed two tasks from the original benchmark that did not meet the necessary criteria for consistent evaluation.
- Prompt Engineering and Processing:
- All prompts were modified to ensure the correct libraries are imported for each respective framework.
- A strict constraint was added to the beginning of each prompt requiring models to return code only. This removes accompanying explanations to improve execution efficiency and grading consistency.
Method
The authors leverage a modular pipeline for evaluating quantum code generation, structured around a framework that integrates multiple quantum computing platforms. The process begins with the selection of a framework to test—specifically Qiskit, Pennylane, or Cirq—each of which is accessed via a unified API interface managed by OpenRouter. This setup allows for consistent interaction with different quantum development environments while abstracting low-level implementation differences.

As shown in the figure below, the selected framework is used to generate quantum code, which is then sent as API requests to the backend system. The responses are parsed to extract the generated code, which is subsequently executed in an isolated sandbox environment to ensure safety and reproducibility. The output is validated against canonical solutions to assess correctness. For deterministic tasks, validation involves checking whether the generated program satisfies a fixed correctness criterion under a predefined harness. For probabilistic tasks, correctness is determined by the agreement of measurement outcome distributions with a reference distribution.
To handle probabilistic tasks, the authors calibrate a global acceptance threshold based on the inherent variability of canonical circuit executions. For each task, the reference distribution is computed as the normalized mean of 1000 repeated executions of the canonical circuit. The within-canonical variability is quantified using the Kullback-Leibler (KL) divergence between the empirical distributions and the reference distribution. A global threshold is then derived from the 99.7th percentile of the pooled KL divergence values across all tasks, resulting in a threshold of τ=0.05, which is used consistently across the evaluation. This calibration ensures that the acceptance criterion accounts for natural shot noise and variability in quantum measurements.
Experiment
The QuanBench+ benchmark evaluates a diverse set of frontier and open-weight large language models on their ability to generate functional quantum code across three frameworks: Qiskit, Cirq, and PennyLane. The evaluation utilizes Pass@k metrics and compares one-shot generation against settings involving prompt prefilling and iterative feedback-based repair. Results reveal a significant asymmetry in framework difficulty, with Qiskit being the easiest and PennyLane the most challenging, suggesting that model performance is heavily tied to framework-specific API familiarity. While feedback loops effectively recover many surface-level implementation and interface errors, they do not fully close the performance gap or resolve the deeper semantic and reasoning mistakes that persist across all frameworks.
The bar chart shows Pass@1 scores across different models and frameworks, with Qiskit achieving the highest performance and PennyLane the lowest. Feedback-based repair significantly improves scores across all frameworks, but the relative ranking and performance gap between frameworks remain consistent. Qiskit consistently achieves the highest Pass@1 scores across models PennyLane consistently has the lowest Pass@1 scores across models Feedback-based repair improves performance across all frameworks and reduces the gap between models
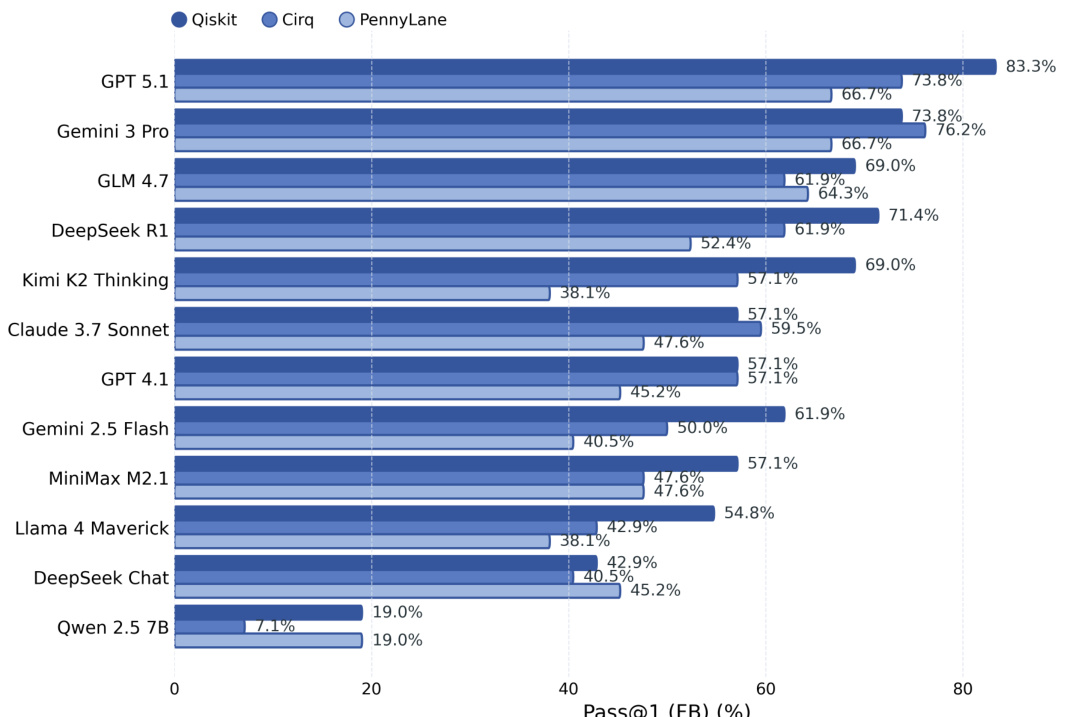
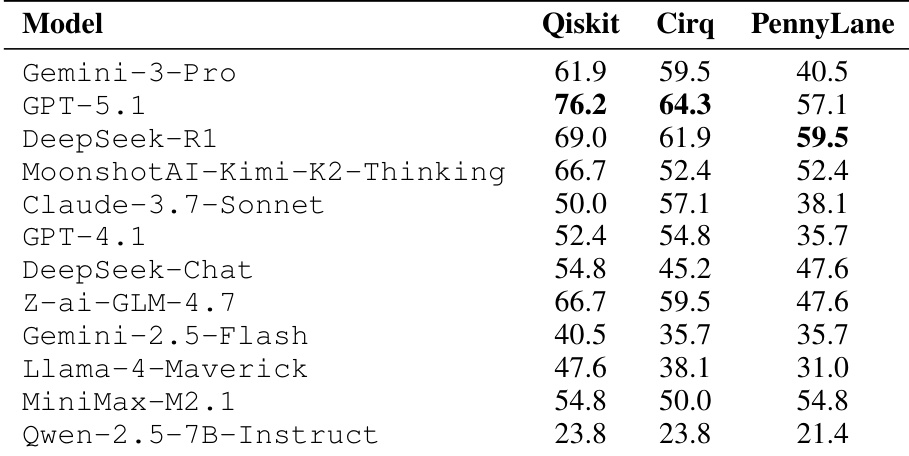
The authors compare model performance across three quantum computing frameworks, showing consistent differences in difficulty. Results indicate that Qiskit is the easiest framework, PennyLane the hardest, and that performance varies significantly by model and framework. Qiskit consistently yields the highest performance across models, while PennyLane shows the lowest scores. Model rankings shift across frameworks, with no single model dominating all environments. Performance differences between frameworks persist even after feedback repair, indicating framework-specific challenges.
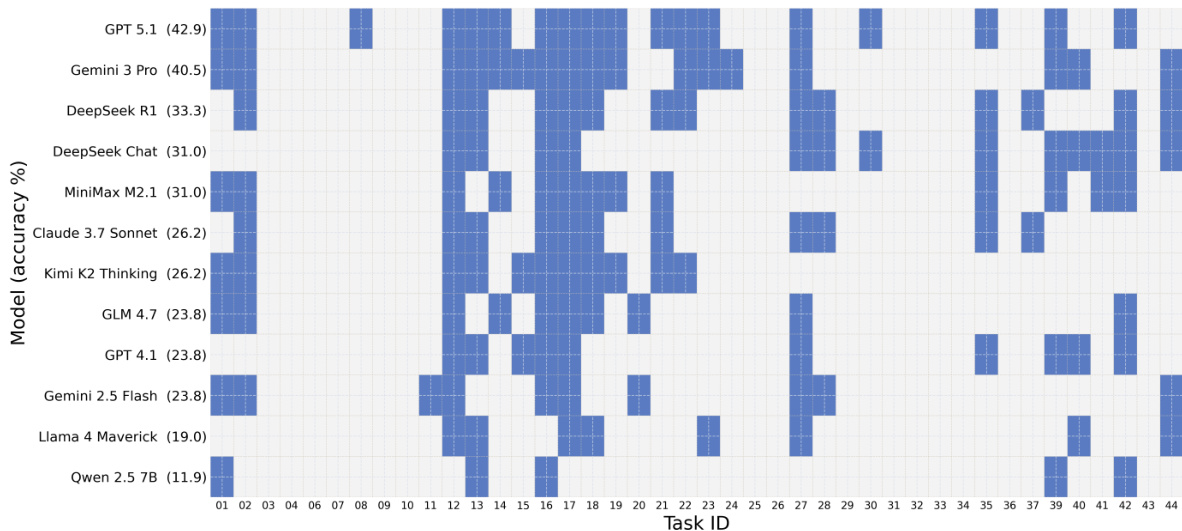
The heatmap visualizes the one-shot correctness of various models across tasks, showing that Qiskit generally yields higher accuracy than PennyLane and Cirq. Models exhibit varying performance across tasks, with some achieving broad success and others showing more scattered results. Qiskit consistently shows higher accuracy compared to PennyLane and Cirq across models. Model performance varies significantly across tasks, with some models achieving broad success and others showing more scattered results. The heatmap reveals differences in model capabilities, with stronger models demonstrating more consistent success across tasks.
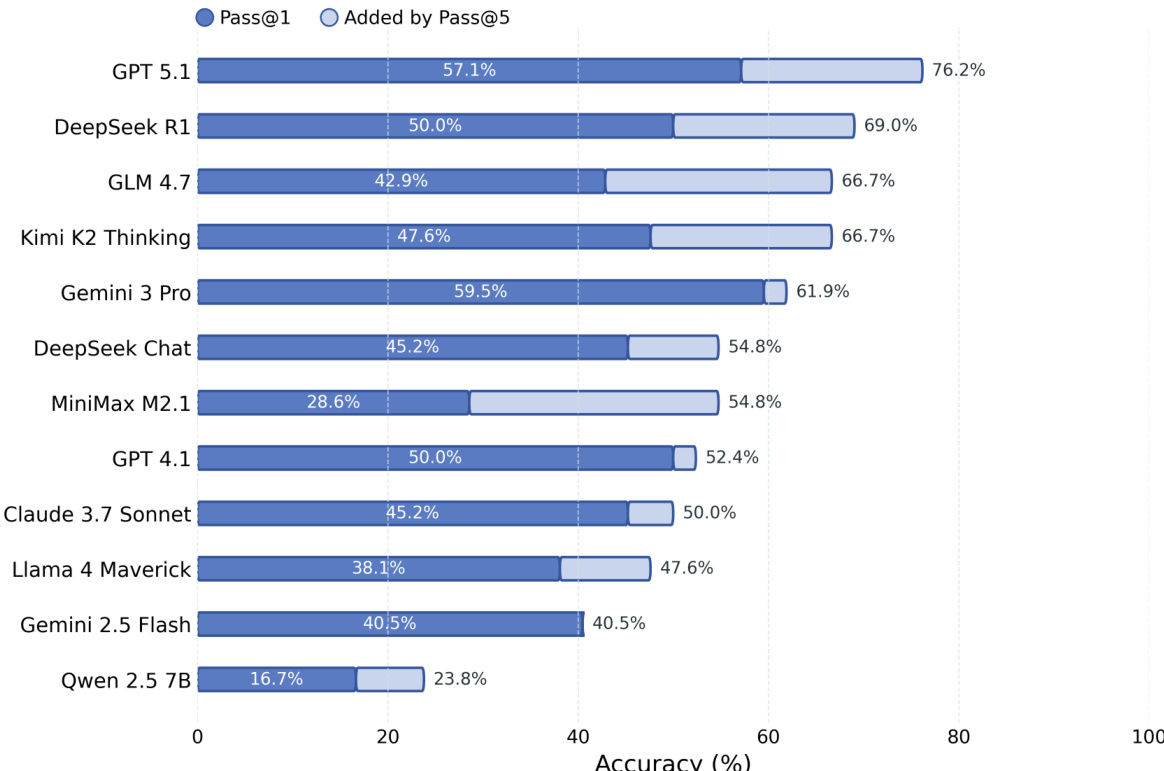
The bar chart compares the Pass@1 accuracy of various models with the additional correctness achieved by Pass@5. Results show that most models gain significantly from generating multiple samples, with GPT 5.1 achieving the highest overall accuracy and Qwen 2.5 7B showing the smallest improvement from Pass@5. Pass@5 substantially improves accuracy for most models compared to Pass@1 GPT 5.1 achieves the highest Pass@1 and Pass@5 scores Qwen 2.5 7B shows the smallest gain from Pass@5
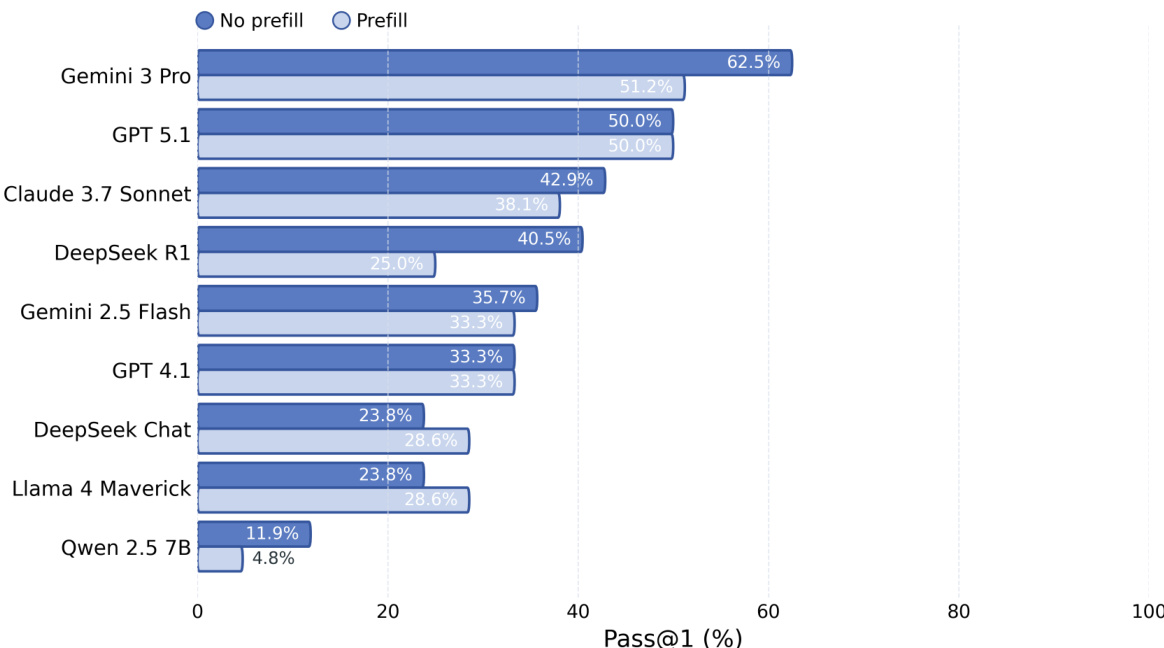
The authors compare Pass@1 performance between no-prefill and prefill settings across multiple models. Results show that prefill consistently improves performance, with larger gains observed for models and frameworks where boilerplate code is more error-prone. The strongest models benefit less from prefill, suggesting it primarily reduces setup-related errors rather than core reasoning challenges. Prefill improves Pass@1 across all models, with larger gains for weaker models and frameworks with complex setup The largest performance gains occur in frameworks where boilerplate is easy to miss Stronger models benefit less from prefill, indicating it mainly addresses surface-level coding errors rather than reasoning
These experiments evaluate model performance across different quantum computing frameworks, repair strategies, and prompting settings to identify key drivers of coding accuracy. The results demonstrate that Qiskit is consistently the most accessible framework while PennyLane presents the greatest difficulty, with performance gaps persisting regardless of feedback-based repairs. Additionally, while multiple sampling and prefill techniques significantly enhance accuracy by mitigating boilerplate errors and setup challenges, the most capable models show less sensitivity to these improvements.