Command Palette
Search for a command to run...
LLM Safety From Within: Detecting Harmful Content with Internal Representations
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Difan Jiao Yilun Liu Ye Yuan Zhenwei Tang Linfeng Du Haolun Wu Ashton Anderson
Abstract
Guard models are widely used to detect harmful content in user prompts and LLM responses. However, state-of-the-art guard models rely solely on terminal-layer representations and overlook the rich safety-relevant features distributed across internal layers. We present SIREN, a lightweight guard model that harnesses these internal features. By identifying safety neurons via linear probing and combining them through an adaptive layer-weighted strategy, SIREN builds a harmfulness detector from LLM internals without modifying the underlying model. Our comprehensive evaluation shows that SIREN substantially outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters. Moreover, SIREN exhibits superior generalization to unseen benchmarks, naturally enables real-time streaming detection, and significantly improves inference efficiency compared to generative guard models. Overall, our results highlight LLM internal states as a promising foundation for practical, high-performance harmfulness detection.
One-sentence Summary
By identifying safety neurons through linear probing and combining them via an adaptive layer-weighted strategy, the lightweight guard model SIREN leverages internal LLM representations to outperform state-of-the-art open-source models across multiple benchmarks while using 250× fewer trainable parameters and enabling superior generalization and real-time streaming detection.
Key Contributions
- The paper introduces SIREN, a lightweight and plug-and-play guard model that detects harmfulness by leveraging internal neuron representations of LLMs instead of relying solely on terminal-layer outputs.
- The method identifies safety-relevant neurons through L1-regularized linear probing and aggregates these features across multiple layers using an adaptive, performance-weighted combination strategy.
- Experimental results demonstrate that SIREN outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters and providing superior generalization to unseen datasets and real-time streaming detection.
Introduction
As large language models (LLMs) scale, implementing robust guardrails to detect harmful user prompts and model responses has become essential for safe deployment. Current state of the art guard models typically treat safety detection as a generative task by relying solely on terminal layer representations. This approach overlooks the rich, safety-relevant features distributed across the internal layers of the model and incurs high computational costs due to autoregressive token generation. The authors leverage these internal representations to introduce SIREN, a lightweight, plug-and-play framework that identifies safety neurons via linear probing and aggregates them using an adaptive layer-weighted strategy. SIREN outperforms existing generative guard models across multiple benchmarks while using 250 times fewer trainable parameters and providing superior inference efficiency.
Method
The authors leverage a two-stage framework for content safety classification that operates entirely on the internal representations of a transformer-based language model (LLM), without modifying its weights. This approach, termed SIREN, is designed to identify and aggregate safety-relevant neurons across layers to construct a robust feature representation for harmfulness detection. The overall architecture consists of two primary stages: safety neuron identification and adaptive neuron aggregation.
Refer to the framework diagram  . In the first stage, the internal representations of each layer are extracted from the LLM for a given input sequence s of length T. These representations, denoted as xl=LLMl(s)∈RT×D for layer l, are derived from either residual streams or feedforward network activations. To capture the overall semantic content of the sentence, a mean pooling operation is applied to the token-level representations, resulting in a pooled representation xl∗∈RD. A layer-wise linear probe is then trained on these pooled representations using a classification task with ground-truth harmfulness labels y. The objective is to minimize the cross-entropy loss with L1 regularization on the probe weights Wl, which is justified by the linear representation hypothesis that semantic concepts are often linearly encoded in LLMs. The magnitude of the trained weights wl,j for each neuron j in layer l is used to determine its relevance to harmfulness detection. These weights are normalized, and the top-ranked neurons whose cumulative normalized magnitude exceeds a threshold η are selected as the safety neurons for that layer, forming the set Sl.
. In the first stage, the internal representations of each layer are extracted from the LLM for a given input sequence s of length T. These representations, denoted as xl=LLMl(s)∈RT×D for layer l, are derived from either residual streams or feedforward network activations. To capture the overall semantic content of the sentence, a mean pooling operation is applied to the token-level representations, resulting in a pooled representation xl∗∈RD. A layer-wise linear probe is then trained on these pooled representations using a classification task with ground-truth harmfulness labels y. The objective is to minimize the cross-entropy loss with L1 regularization on the probe weights Wl, which is justified by the linear representation hypothesis that semantic concepts are often linearly encoded in LLMs. The magnitude of the trained weights wl,j for each neuron j in layer l is used to determine its relevance to harmfulness detection. These weights are normalized, and the top-ranked neurons whose cumulative normalized magnitude exceeds a threshold η are selected as the safety neurons for that layer, forming the set Sl.
In the second stage, the framework aggregates the identified safety neurons across all layers to form a more comprehensive feature representation. The authors note that LLMs exhibit a hierarchical learning structure where representations evolve from low-level patterns to high-level semantics, motivating the aggregation of safety-relevant features from multiple layers. To account for the varying contribution of each layer to the task, an adaptive weighting strategy is introduced. The weight αl for layer l is computed based on its validation F1 score fl from the linear probe, normalized between the maximum and minimum F1 scores across all layers. This assigns higher weights to more informative layers. The safety neuron activations from each layer are extracted, weighted by their respective αl, and concatenated to form the final feature vector z. This aggregated feature z is then fed into a multi-layer perceptron (MLP) classifier for harmfulness prediction. The MLP learns to combine the complementary signals from the cross-layer features, and the αl values serve as a prior on layer importance rather than a final feature weighting.
The framework is designed to be plug-and-play, operating on top of any transformer-based LLM without requiring architectural changes. It is also transferable to token-level attribution tasks. By removing the mean pooling operation, the same safety neurons and classifier can be applied to each token's hidden representation, directly producing per-token harmfulness scores. This capability is demonstrated in the visualization of token-level streaming detection results  , where the model processes a sequence incrementally, extracting features for each prefix and applying the classifier to generate a continuous harmfulness score at every token position. This streaming evaluation is achieved by re-evaluating the feature extractor on prefix-restricted internal states, enabling a zero-shot assessment of how safety information manifests in early generation stages.
, where the model processes a sequence incrementally, extracting features for each prefix and applying the classifier to generate a continuous harmfulness score at every token position. This streaming evaluation is achieved by re-evaluating the feature extractor on prefix-restricted internal states, enabling a zero-shot assessment of how safety information manifests in early generation stages.
Experiment
SIREN is evaluated against state-of-the-art specialized guard models by training on the internal representations of general-purpose LLM backbones across multiple safety benchmarks. The results demonstrate that SIREN achieves superior detection performance, maintains higher policy consistency, and generalizes effectively to unseen reasoning traces and streaming detection tasks. Furthermore, the approach offers significant advantages in both training and inference efficiency due to its sparse parameter usage and the elimination of autoregressive generation.
The authors compare SIREN, a lightweight classifier trained on internal representations of general-purpose LLMs, against safety-specialized guard models across multiple benchmarks. Results show that SIREN achieves higher average performance and more consistent detection across different datasets compared to guard models, while also demonstrating strong generalization to unseen benchmarks and streaming detection. SIREN is significantly more computationally efficient during inference due to its reliance on a single forward pass through the base model. SIREN outperforms guard models across all backbone pairs and maintains consistent precision-recall tradeoffs across diverse benchmarks. SIREN generalizes effectively to unseen benchmarks and streaming detection without additional training or architectural changes. SIREN achieves substantial inference efficiency by operating on precomputed internal representations, requiring far fewer computational operations than autoregressive guard models.
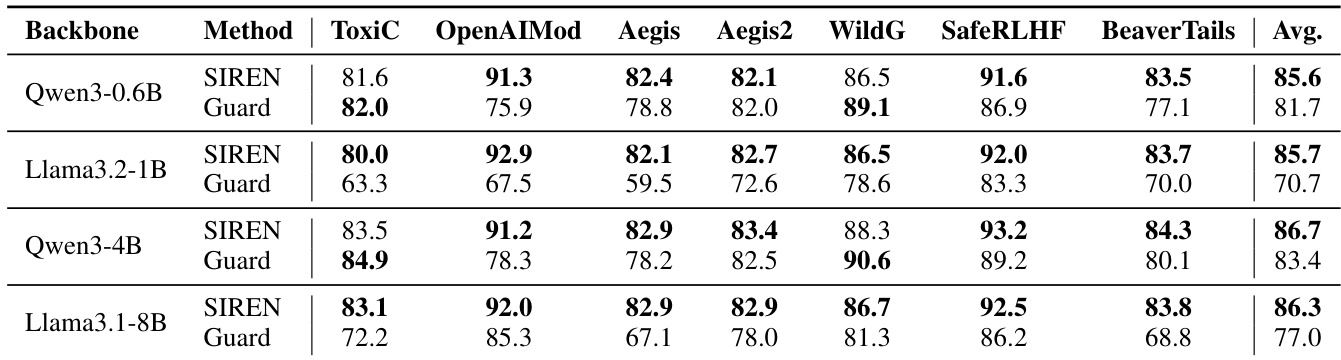
The authors evaluate SIREN, a method that leverages internal representations of general-purpose LLMs for harmfulness detection, against safety-specialized guard models across multiple benchmarks. Results show that SIREN achieves higher detection performance and maintains more consistent precision-recall trade-offs across datasets compared to guard models, which exhibit significant variance in their classification behavior. SIREN also demonstrates robust generalization to unseen benchmarks and streaming detection tasks without additional training, while requiring substantially fewer parameters and computational resources during inference. SIREN achieves higher and more consistent detection performance across benchmarks compared to guard models, which show large variance in precision and recall. SIREN generalizes effectively to unseen benchmarks and streaming detection tasks without additional training or architectural modifications. SIREN requires significantly fewer parameters and computational resources during inference than guard models, which rely on autoregressive generation.
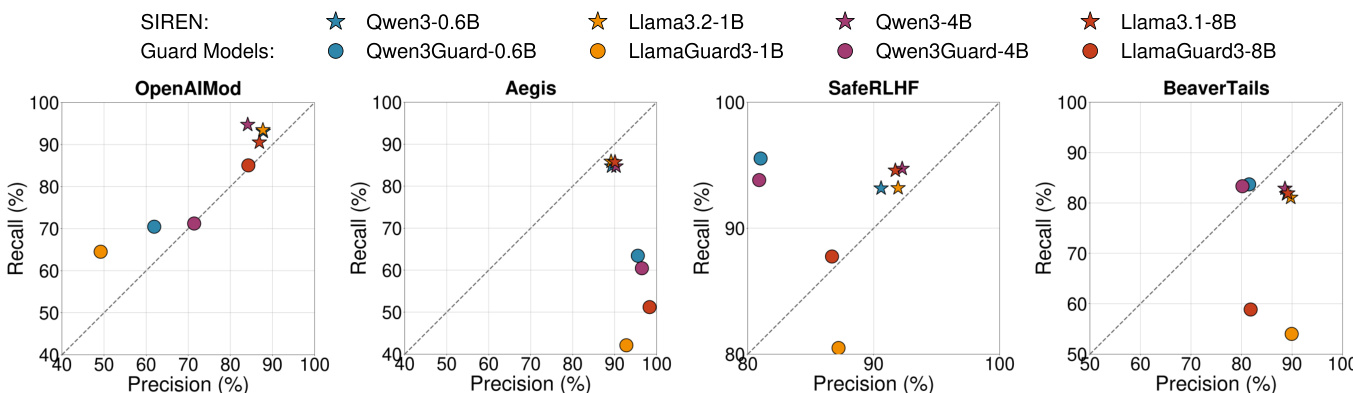
The authors compare SIREN with safety-specialized guard models across different detection latency positions, showing that SIREN consistently achieves higher detection rates than the guard models. SIREN maintains strong performance across all latency stages, while guard models exhibit lower detection rates, particularly in earlier stages. The results indicate that SIREN's approach to harmfulness detection is more effective and stable under varying detection latencies. SIREN achieves higher detection rates than guard models across all detection latency positions. SIREN maintains consistent performance across different latency stages, while guard models show lower detection rates, especially in early stages. SIREN outperforms guard models in timely detection, indicating better real-time harmful content identification.
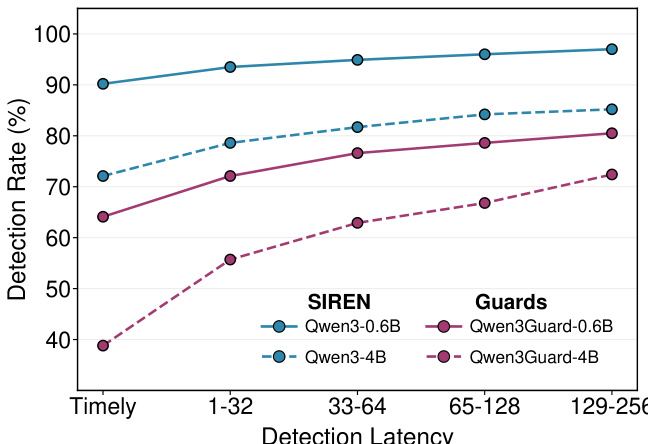
The authors conduct ablation studies to analyze key design choices in SIREN, focusing on hyperparameter sensitivity and internal safety encoding. The results show that SIREN's performance is stable across a range of regularization strengths and neuron selection thresholds, with optimal settings found through grid search. The model leverages internal representations from multiple layers, with middle layers contributing most to safety detection, and cross-layer aggregation improves performance over single-layer probes. The training process uses a lightweight MLP classifier on extracted neurons, with hyperparameters selected to balance performance and efficiency. SIREN's performance is stable across a range of regularization strengths and neuron selection thresholds, with optimal settings found through grid search. Middle layers of the LLM contribute most to safety detection, and cross-layer aggregation improves performance over single-layer probes. The training process uses a lightweight MLP classifier on extracted neurons, with hyperparameters selected to balance performance and efficiency.
The authors evaluate SIREN, a lightweight classifier that operates on internal representations of language models, against safety-specialized guard models across multiple benchmarks. Results show that SIREN achieves higher detection performance than guard models, maintains consistent policy behavior across datasets, and generalizes effectively to unseen and streaming detection tasks. SIREN also demonstrates significant training and inference efficiency due to its reliance on sparse neuron selection and minimal parameter updates. SIREN outperforms safety-specialized guard models across all evaluated benchmarks and model sizes. SIREN maintains consistent precision and recall across different datasets, indicating stable safety policy learning. SIREN generalizes well to unseen benchmarks and streaming detection without additional training, while requiring significantly fewer parameters and computational resources than guard models.
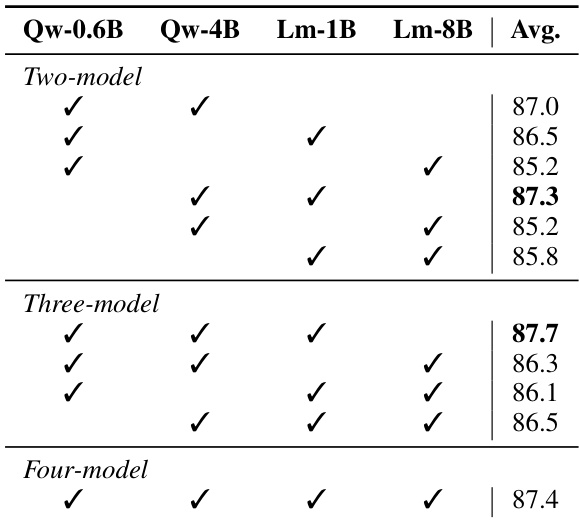
The authors evaluate SIREN, a lightweight classifier utilizing the internal representations of general-purpose LLMs, by comparing it against specialized guard models across various benchmarks, latency stages, and ablation configurations. SIREN demonstrates superior detection performance and more stable precision-recall tradeoffs than guard models, while also showing robust generalization to unseen benchmarks and streaming tasks. Furthermore, the method achieves significant computational efficiency and benefits from cross-layer aggregation, particularly by leveraging safety information encoded in the middle layers of the backbone model.