Command Palette
Search for a command to run...
Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
Harshit Joshi Priyank Shethia Jadelynn Dao Monica S. Lam
Abstract
Real-world document question answering is challenging. Analysts must synthesize evidence across multiple documents and different parts of each document. However, any fixed LLM context window can be exceeded as document collections grow. A common workaround is to decompose documents into chunks and assemble answers from chunk-level outputs, but this introduces an aggregation bottleneck: as the number of chunks grows, systems must still combine and reason over an increasingly large body of extracted evidence. We present SLIDERS, a framework for question answering over long document collections through structured reasoning. SLIDERS extracts salient information into a relational database, enabling scalable reasoning over persistent structured state via SQL rather than concatenated text. To make this locally extracted representation globally coherent, SLIDERS introduces a data reconciliation stage that leverages provenance, extraction rationales, and metadata to detect and repair duplicated, inconsistent, and incomplete records. SLIDERS outperforms all baselines on three existing long-context benchmarks, despite all of them fitting within the context window of strong base LLMs, exceeding GPT-4.1 by 6.6 points on average. It also improves over the next best baseline by ~19 and ~32 points on two new benchmarks at 3.9M and 36M tokens, respectively.
One-sentence Summary
Researchers from Stanford University propose SLIDERS, a framework for scalable question answering over long document collections that replaces text concatenation with structured reasoning via a relational database and a data reconciliation stage using provenance, extraction rationales, and metadata to ensure global coherence, ultimately outperforming existing baselines on three long-context benchmarks and two new benchmarks.
Key Contributions
- The paper introduces SLIDERS, a framework for question answering over long document collections that utilizes structured reasoning by extracting salient information into a relational database.
- This work presents a data reconciliation stage that leverages provenance, extraction rationales, and metadata to detect and repair duplicated, inconsistent, or incomplete records to ensure global coherence.
- Experimental results demonstrate that the framework outperforms all baselines on three existing long-context benchmarks, exceeding GPT-4.1 by an average of 6.6 points, and shows significant improvements of approximately 19 and 32 points on two new benchmarks.
Introduction
Effective question answering over large document collections is critical for complex analytical tasks, yet it remains difficult because document sets often exceed the fixed context windows of large language models. While existing approaches attempt to solve this by chunking documents and aggregating local outputs, they suffer from an aggregation bottleneck where the volume of extracted evidence eventually overwhelms the model. The authors propose SLIDERS, a framework that overcomes this limitation by converting document chunks into a structured relational database. By utilizing a data reconciliation stage to resolve inconsistencies and leveraging LLM-generated SQL for reasoning, SLIDERS enables scalable, auditable, and coherent question answering across millions of tokens.
Dataset
The authors evaluate their model using several specialized benchmarks designed to test long-context reasoning, multi-document retrieval, and complex aggregation:
-
Benchmark Composition and Sources
- FinanceBench: A single-document financial question-answering benchmark consisting of 150 questions regarding publicly traded companies, with evidence sourced from public filings.
- Loong: A multi-document benchmark covering finance (English and Chinese), law (Chinese), and academic research (English). Each instance contains an average of approximately 11 documents.
- Oolong: A long-context reasoning benchmark focused on aggregation tasks. The authors specifically utilize the Oolong-Synth subset for experiments, evaluating at a 256K context window.
-
Data Processing and Metadata Construction
- Context-Aware Chunking: To ensure every chunk is self-contained for faithful extraction, the authors retain raw text alongside structural metadata. This includes the document title, document description, chunk index, and the full heading path (e.g., Header 1 to Header 1.1.3).
- Information Extraction and Normalization: The authors use SLIDERS to extract structured information, which is then manually verified. Data undergoes normalization, such as converting currency magnitudes (e.g., $1.23B to 1230 million USD) and enforcing type safety through coercion to declared data types.
- Primary Key Management: To handle extraction errors and duplicate rows from unstructured sources like PDFs, the authors identify semantic primary keys. This allows them to group, merge, and canonicalize rows that represent the same real-world observation.
-
Benchmark Creation and Usage
- Question Generation: Questions are derived from seed queries (such as WikiCeleb100 or FinQ100) and expanded by recombining extracted information through temporal cohorts or aggregate financial properties.
- Gold Answer Annotation: The authors manually reconcile extracted tables to create consolidated database representations and author SQL queries for each question. For each benchmark, five questions are specifically retained that cannot be solved via SQL alone.
- Evaluation Frameworks: The authors employ an LLM-as-a-judge setup for non-numeric questions to assess correctness based on justifications. For numeric aggregation in Oolong, they use a metric that rewards predictions with smaller deviations from the ground truth.
Method
The SLIDERS framework processes long document collections by transforming unstructured text into a coherent, structured relational database, enabling accurate and auditable question answering. The overall architecture consists of five sequential tasks that address key challenges in scaling language models to large-scale, multi-document reasoning.
The process begins with Contextualized Chunking, where the input document set is decomposed into semantically and structurally coherent chunks. Each document is augmented with metadata that includes a global description and local structural signals such as section headers, tables, and figure captions. This enriched representation ensures that chunks are locally self-contained and preserve context, avoiding issues like detached headers or orphaned paragraphs. The chunks are then processed independently, forming the basis for subsequent extraction.
Following chunking, the Schema Induction task derives a structured schema from the question and document metadata. This schema specifies the entities, attributes, and relationships to be extracted, providing a blueprint for the information extraction process. The schema is designed with strict type requirements and normalization rules, ensuring that extracted values are standardized across all chunks.
The core of the system is the Structured Extraction task, which extracts information from each chunk according to the induced schema. To minimize hallucinations, a two-stage process is employed: a relevance gate first determines if the chunk contains evidence relevant to the schema, and extraction only proceeds if the gate passes. This prevents the injection of false positives into the database. The extraction model, implemented with in-context learning, generates structured output as JSON objects, capturing values, provenance, and extraction rationales. The extraction process scales efficiently by processing one chunk at a time and leveraging parallelism across chunks.
The extracted tables are then subjected to Data Reconciliation, which resolves conflicts, redundancy, and inconsistencies across the entire document set. This task exploits the relational structure of the extracted data: rows are grouped by a primary key, which is identified through an LLM agent that analyzes the schema and sample rows. Within each group, a reconciliation agent iteratively applies operations such as deduplication, conflict resolution, aggregation, and canonicalization, using provenance and rationale to guide decisions. The agent generates SQL programs to execute these operations, ensuring the process remains auditable. The reconciliation process is designed to handle cases where the same entity is described differently across documents, such as variations in names or dates, by first resolving these variations through canonicalization before integrating the information.
Finally, the Question Answering task synthesizes the answer by generating and executing SQL queries over the reconciled database. An SQL-coding agent iteratively generates queries, executes them, and refines the query if needed until a satisfactory answer is produced. This approach ensures that the answer is derived from a globally coherent and consistent database, rather than being directly generated from unstructured text, which can be error-prone.
Experiment
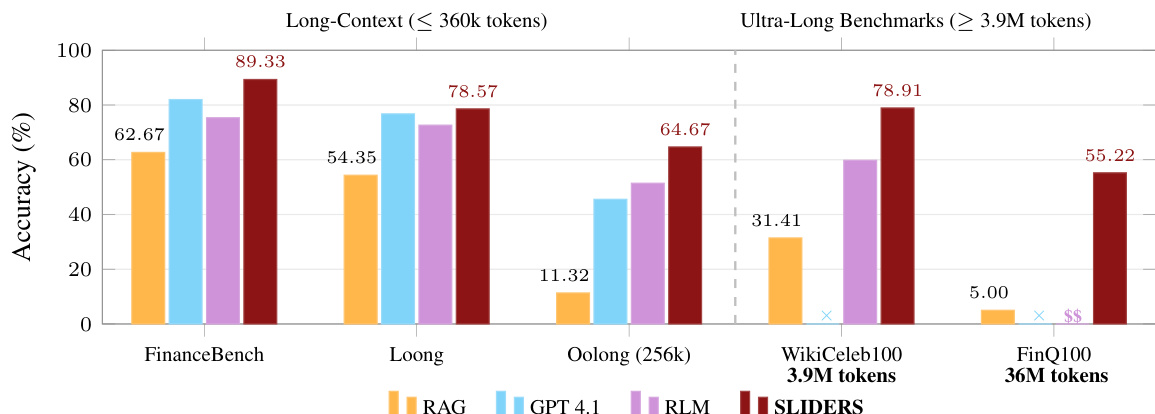
SLIDERS is evaluated against several strong baselines, including frontier models like GPT-4.1 and various RAG-based approaches, across both context-bounded and ultra-long document benchmarks. The experiments demonstrate that SLIDERS significantly outperforms existing methods by utilizing structured reasoning and data reconciliation to overcome the aggregation bottleneck. Ultimately, the framework proves highly scalable and cost-effective, maintaining high accuracy even as input sizes reach tens of millions of tokens.
The authors evaluate SLIDERS, a framework for structured reasoning over long document collections, on both long-context and ultra-long benchmarks. Results show that SLIDERS outperforms various baselines, including retrieval-augmented generation and recursive language models, across all benchmarks, demonstrating consistent gains even when inputs fit within the context window of frontier models. The framework achieves high accuracy on ultra-long document sets, exceeding the performance of other methods and maintaining scalability with increasing document size. SLIDERS outperforms all baselines on long-context and ultra-long benchmarks, achieving higher accuracy than GPT-4.1 and other methods. SLIDERS maintains high accuracy on ultra-long document sets, even when inputs exceed the context limits of frontier models. The framework's structured reasoning approach enables scalable and reliable aggregation of evidence across large document collections.
The authors compare SLIDERS against several baselines, including RLM and GPT-based models, on long-document question-answering tasks. Results show that SLIDERS outperforms all baselines across both benchmarks, with significant improvements in accuracy, particularly in scenarios requiring aggregation over large contexts. The framework's structured reasoning approach enables consistent performance even as input size increases, demonstrating scalability beyond the context limits of individual models. SLIDERS achieves higher accuracy than all evaluated baselines on both benchmarks, demonstrating superior performance in long-document question answering. The framework maintains consistent performance across increasing input sizes, showing scalability beyond the context limits of individual language models. SLIDERS outperforms baselines by a substantial margin on aggregation-heavy tasks, highlighting the effectiveness of structured reasoning over free-form generation.

The authors evaluate SLIDERS, a framework for structured reasoning over long document collections, on multiple benchmarks that vary in size and complexity. The framework outperforms several baselines, including retrieval-augmented generation and chain-of-agents methods, particularly on tasks requiring aggregation across documents, and demonstrates robustness with open-source language models. SLIDERS maintains consistent performance on ultra-long document sets, achieving high accuracy despite input sizes exceeding the context limits of frontier models. SLIDERS outperforms multiple baselines on long-document question-answering tasks, especially those requiring aggregation across documents. The framework achieves high accuracy on ultra-long document sets, even when inputs exceed the context window of frontier models. SLIDERS maintains strong performance with open-source language models, indicating that its benefits stem from the structured reasoning framework rather than reliance on proprietary models.
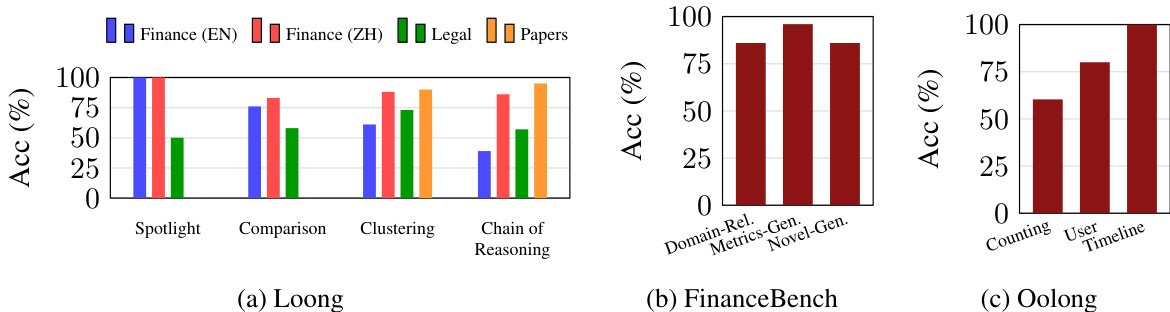
The experiment evaluates the performance of SLIDERS across multiple question-answering benchmarks, comparing it to various baselines. Results show that SLIDERS consistently outperforms all baselines on long-document tasks, even when inputs fit within the context window of frontier models, with significant gains in accuracy observed on aggregation-heavy questions. The framework demonstrates robustness across different question types and domains, with notable improvements on financial and biographical datasets. SLIDERS also maintains high accuracy on ultra-long document sets that exceed model context limits, highlighting its scalability and effectiveness in handling large-scale multi-document reasoning. SLIDERS outperforms all baselines on long-document question-answering tasks, achieving higher accuracy even when inputs fit within the context window of large language models. The framework shows strong performance across diverse question types, with particularly high accuracy on domain-relevant, novel, and timeline questions. SLIDERS maintains high accuracy on ultra-long document sets exceeding model context limits, demonstrating its scalability and effectiveness in large-scale multi-document reasoning.
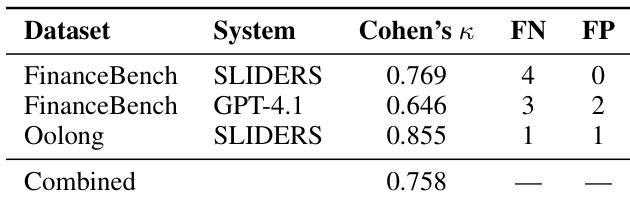
The authors evaluate SLIDERS, a framework for structured reasoning over long documents, by comparing its performance against several baselines on multiple benchmarks. Results show that SLIDERS outperforms all baselines across all benchmarks, achieving higher accuracy even when inputs fit within the context window of frontier models, and demonstrates robust performance on ultra-long document sets that exceed current model limits. SLIDERS outperforms all baselines on all benchmarks, including those where inputs fit within the context window of frontier models. SLIDERS achieves high accuracy on ultra-long document sets that exceed the context limits of current models, demonstrating scalability. The framework's structured reasoning approach enables effective aggregation and reconciliation of evidence across large document collections.
The authors evaluate the SLIDERS framework across various long-context and ultra-long document benchmarks to validate its ability to perform structured reasoning and evidence aggregation. The results demonstrate that SLIDERS consistently outperforms retrieval-augmented generation, recursive models, and frontier models like GPT-4, particularly on tasks requiring complex information synthesis. The framework proves highly scalable and robust, maintaining high accuracy even when document sizes exceed the context limits of individual language models or when utilizing open-source models.