Command Palette
Search for a command to run...
Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs from Raw Corpora
Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs from Raw Corpora
Chenkai Pan Xinglong Xu Yuhang Xu Yujun Wu Siyuan Li Jintao Chen Conghui He Jingxuan Wei Cheng Tan
Abstract
Reliably transferring specialized human knowledge from text into large language models remains a fundamental challenge in artificial intelligence. Fine-tuning on domain corpora has enabled substantial capability gains, but the process operates without feedback: when a model fails on a domain task, there is no method to diagnose what is deficient in the training data, and the only recourse is to add more data indiscriminately. Here we show that when a structured knowledge representation extracted from the source corpus serves as the shared foundation for both training data and evaluation, the complete data-engineering lifecycle maps onto the software development lifecycle in a precise and operative way: training data becomes source code specifying what the model should learn, model training becomes compilation, benchmarking becomes unit testing, and failure-driven data repair becomes debugging. Under this correspondence, model failures decompose into concept-level gaps and reasoning-chain breaks that can be traced back to specific deficiencies in the data and repaired through targeted patches, with each repair cycle producing consistent improvements across model scales and architectures without degrading general capabilities. We formalize this principle as Programming with Data and instantiate it across sixteen disciplines spanning the natural sciences, engineering, biomedicine, and the social sciences, releasing a structured knowledge base, benchmark suite, and training corpus as open resources. By demonstrating that the relationship between training data and model behaviour is structurally traceable and systematically repairable, this work establishes a principled foundation for the reliable engineering of human expertise into language models.
One-sentence Summary
The authors propose Programming with Data, a test-driven framework that maps training corpora to source code, benchmarking to unit testing, and failure-driven repair to debugging, enabling the precise diagnosis and targeted patching of concept-level gaps and reasoning-chain breaks across sixteen disciplines while delivering consistent improvements without degrading general language capabilities.
Key Contributions
- The work introduces Programming with Data, a framework that treats domain training data as executable source code derived from structured knowledge representations, mapping the data engineering lifecycle to a software development workflow where training functions as compilation and benchmarking serves as unit testing.
- This closed-loop methodology decomposes model failures into concept-level gaps and reasoning-chain breaks that trace directly to specific data deficiencies, enabling targeted patches that iteratively refine the training corpus while preserving general capabilities.
- Validated across sixteen disciplines in the natural sciences, engineering, biomedicine, and social sciences, the framework consistently improves performance across diverse model scales and architectures and releases a structured knowledge base, benchmark suite, and training corpus as open resources.
Introduction
The authors address the fundamental difficulty of transferring specialized domain knowledge to large language models, where standard fine-tuning operates in an open loop that leaves model failures untraceable to specific data deficiencies. Existing methods suffer from disconnected evaluation and training structures, forcing practitioners to rely on computationally expensive and uninterpretable data augmentation rather than targeted repairs. The authors introduce "Programming with Data," a framework that applies test-driven development principles to AI by extracting a shared knowledge representation from raw corpora to govern both training synthesis and benchmarking. This creates a closed-loop system where benchmark failures are diagnosed as concept or reasoning gaps, traced to precise nodes in the data structure, and resolved through targeted patches that improve domain performance without degrading general capabilities.
Dataset

The authors present ProDaLib, a structured knowledge dataset derived from unstructured academic corpora to support reasoning-rich model training and evaluation.
Dataset Composition and Sources
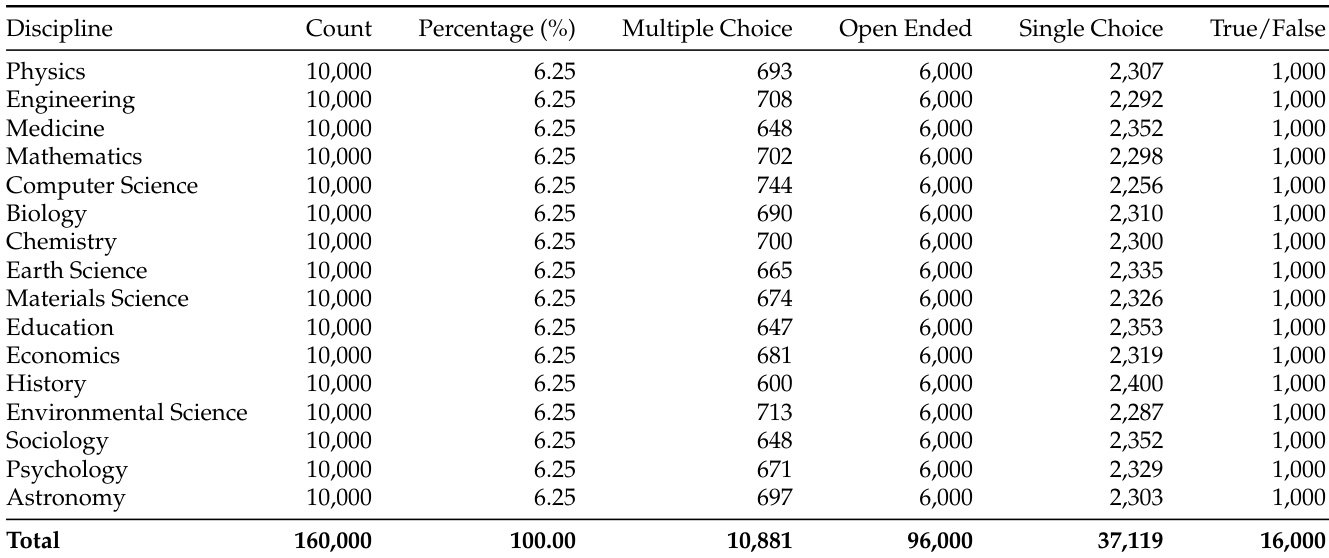
- The corpus originates from 117,000 textbook-grade documents spanning 16 disciplines across natural sciences, engineering, biomedicine, and social sciences.
- Successive quality-based filtering retains 48,000 high-quality chunks containing approximately 1.5 billion tokens, achieving a 10:1 compression ratio that concentrates the material on reasoning-dense content.
- Inclusion rules require documents to be scientific or technical, written at undergraduate, graduate, or research levels, classified as non-descriptive reasoning, and containing non-trivial conceptual or procedural logic.
Key Details for Each Subset
- The extracted knowledge structure comprises 458,622 nodes with a zero orphan rate, ensuring full traceability.
- L3 Reasoning Chains: 43,953 multi-step inferential pathways that anchor the subgraph.
- L2 Relational Statements: 186,784 typed triples encoding causal, definitional, and prerequisite relationships between concepts.
- L1 Atomic Concepts: 227,869 canonical terms with category types and context-aware definitions.
- Discipline distribution varies significantly, with Physics, Engineering, and Medicine exceeding 45,000 nodes, while Astronomy and Psychology contain approximately 7,000.
- Connectivity remains high across all fields, with the largest connected component encompassing over 99.3% of nodes in every discipline.
Data Usage and Processing Strategy
- The authors employ a top-down extraction pipeline where L3 chains are generated first, followed by L2 triples derived via a sliding window over chain steps, and finally L1 concepts harvested from L2 subjects and objects.
- Training data is synthesized from L1 and L2 entries using sliding windows of relational statements, producing open-ended, multiple-choice, and true/false samples with a format ratio that emphasizes open-ended reasoning.
- The benchmark is constructed from L3 chains using adversarial distractor operators including semantic adjacency substitution, relation inversion, and chain truncation to test genuine capability rather than recall.
- Instance-level orthogonality is enforced between benchmark items and training samples, as benchmarks require composing multiple knowledge entries along specific inferential pathways not present in individual training instances.
- Training proceeds in three phases: a uniform baseline of 160,000 samples distributed evenly across 16 disciplines, an error-proportional allocation phase maintaining 160,000 samples based on diagnostic error rates, and a targeted repair phase generating 20 samples per identified error in a 6:3:1 ratio of open-ended to multiple-choice to true/false formats.
Metadata Construction and Structural Properties
- The top-down extraction order enforces a strict reachability invariant, guaranteeing that every L1 and L2 node is reachable from at least one L3 chain, which eliminates untestable orphan entries.
- Metadata construction includes provenance links, parent statement IDs, and category IDs for every node, enabling full traceability from benchmark failures back to specific knowledge entries.
- Concept canonicalization merges lexical variations and assigns context-aware definitions, while pronoun resolution is applied during L2 extraction to ensure unambiguous relational triples.
- Generated training samples include detailed explanations that utilize domain reasoning to justify answers and refute distractors, with strict constraints to avoid exposing internal metadata identifiers in the natural language output.
Method
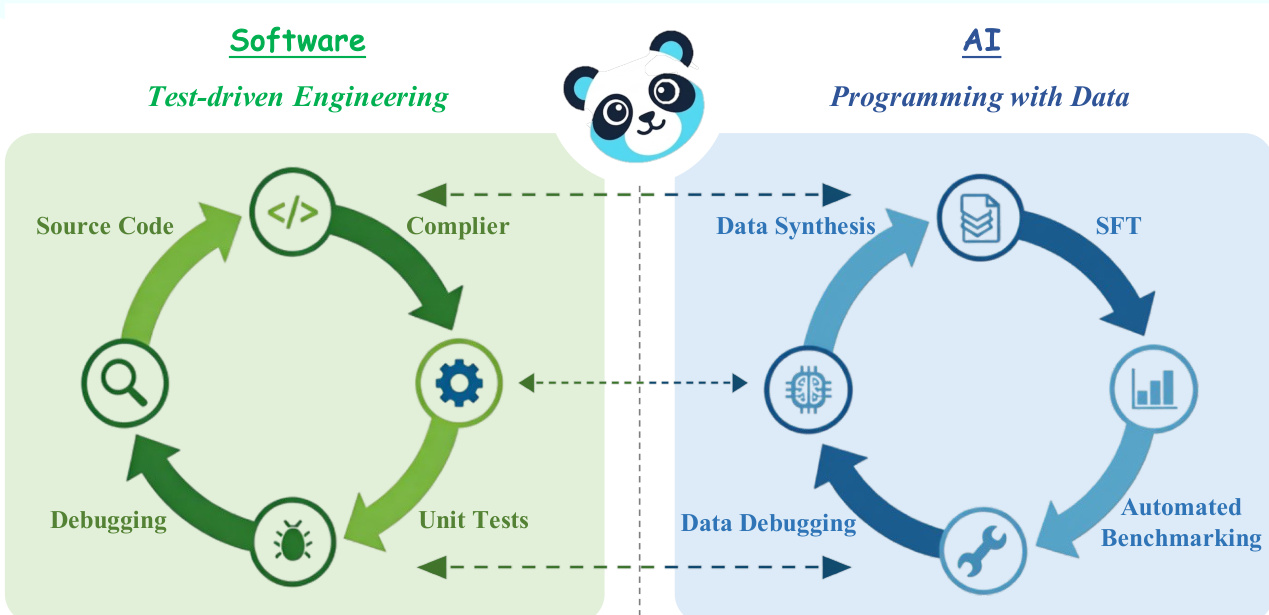
The authors leverage a structured knowledge representation to close the loop between training data generation and model evaluation, establishing a framework they term Programming with Data. This approach draws a direct analogy to software engineering, where a shared specification—such as a requirements document—links code implementation, compilation, and testing. In the context of large language models, the raw corpus serves as the requirements specification, defining the scope of knowledge the model should acquire. Synthesized training data functions as the source code, encoding the specific concepts and relationships the model must internalize. Model training acts as the compiler, transforming this human-readable data into machine-executable weights. The fine-tuned model is the compiled binary, and the benchmark functions as the test suite, verifying whether the model faithfully implements its specification. When a benchmark failure occurs, the shared knowledge structure enables a precise diagnosis, tracing the failure back to a specific deficit in the training data, analogous to a bug fix in software.
The core of this framework is a three-level knowledge structure that serves as the shared specification. This structure is extracted from the raw corpus in a top-down manner: L3 reasoning chains are first identified from high-quality text chunks, then decomposed into L2 knowledge relations (typed triples), and finally, L1 key concepts are harvested from the subjects and objects of these relations. This hierarchical organization ensures that every piece of knowledge is traceable and testable. The framework is instantiated as the ProDa pipeline, which consists of three interconnected components: the Builder, Tester, and Debugger.
The Builder component is responsible for knowledge extraction and training data synthesis. It processes the raw corpus to construct the three-level knowledge structure. The extraction process is guided by the CORE principle, which mandates that the data be Contextualized within the document's global scope, Organized into stratified knowledge layers, Rigorous in enforcing adversarial robustness and instance-level non-overlap between training and evaluation, and Evolving through iterative refinement. The Builder's output is the initial training corpus, grounded in the knowledge structure and ready for model compilation.
The Tester component constructs the benchmark from the L3 reasoning chains, which represent the most demanding inferential patterns in the corpus. This component operates before any training, adhering to the test-first principle of test-driven development. The Rigorous standard is enforced by ensuring each benchmark item contains adversarial distractors constructed from the same knowledge structure and that the benchmark and training data maintain instance-level orthogonality, preventing the model from memorizing answers.
The Debugger component diagnoses each failure identified by the benchmark. It classifies the underlying deficit into one of two categories: a concept gap, where the model lacks or confuses a specific piece of domain knowledge, or a reasoning deficit, where the model possesses the required knowledge but fails to compose it correctly across multiple steps. For each category, the Debugger applies a distinct repair strategy: concept gaps are addressed through knowledge-reinforcement samples that explicitly contrast the confused concepts with their correct definitions, while reasoning deficits are addressed through chain-of-thought samples that scaffold the missing inferential steps. The Evolving standard is operationalized by combining the newly generated patches with a strategically selected subset of the original training data to prevent catastrophic forgetting, and the model is retrained on this augmented corpus, completing the loop.
Experiment
The evaluation setup employs the ProDa-16 benchmark alongside standard general knowledge subsets to assess model performance across multiple architectures and parameter scales. Initial experiments validate the benchmark’s construct validity and discriminative power, while first-pass fine-tuning on automatically synthesized data demonstrates that structured knowledge injection can rival commercial alignment pipelines but inevitably leaves residual capability gaps. Subsequent diagnostic iterations leverage the benchmark’s traceable structure to identify and patch specific knowledge deficits, successfully recovering general capabilities and consistently outperforming conventional data synthesis methods. Collectively, these experiments confirm that a closed-loop, diagnostic-driven repair framework provides a more efficient and scalable pathway for enhancing large language model competence than static data generation alone.
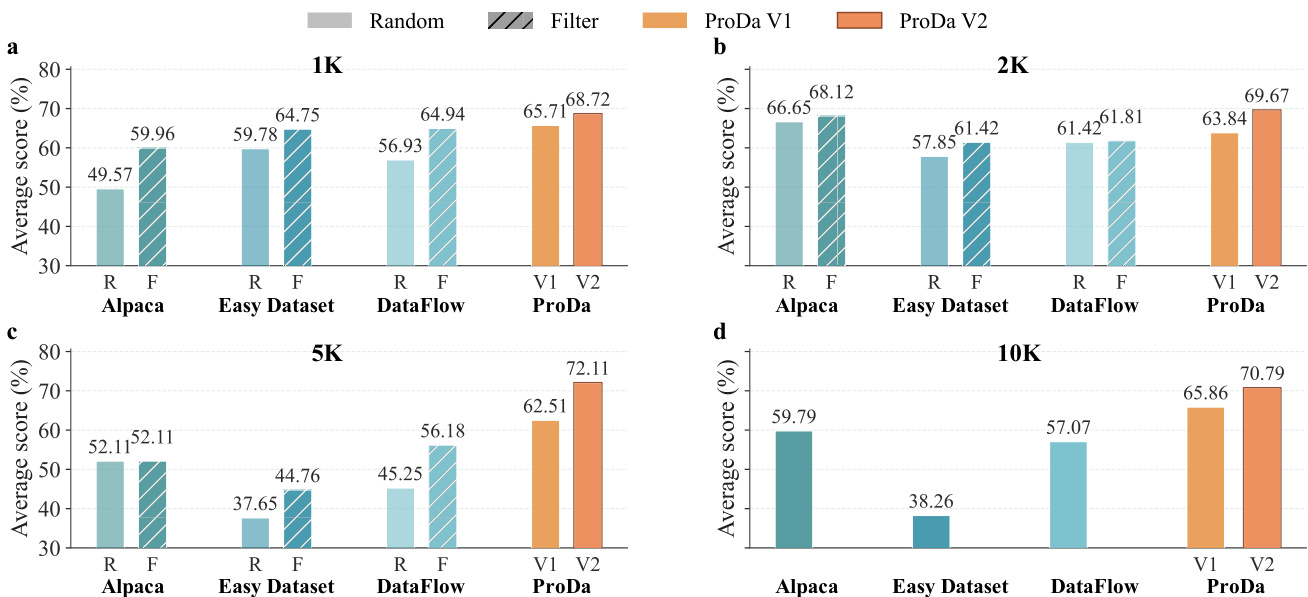
The authors compare the performance of their ProDa framework against baseline data synthesis methods across different data scales. Results show that ProDa consistently outperforms all baselines, with the V2 iteration achieving higher scores than V1 and significantly surpassing conventional methods even at smaller data volumes. The performance gap widens as data scale increases, demonstrating the effectiveness of diagnostic-driven targeted repair over unstructured data scaling. ProDa V2 consistently outperforms baseline methods across all data scales, achieving the highest scores even with minimal data. The performance gap between ProDa and baseline methods widens as data scale increases, indicating superior scalability of the diagnostic approach. ProDa V1 scores are already competitive with baseline methods, but V2 shows substantial gains, highlighting the effectiveness of targeted repair.
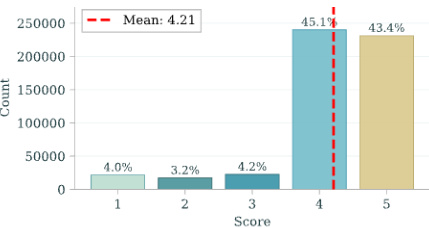
The authors analyze the performance distribution of models on a benchmark, observing that the majority of predictions fall within the lower score ranges, with a notable concentration at the highest score. The results indicate a skewed distribution where most models achieve low to moderate scores, but a significant portion reaches the top score, suggesting a performance gap between models. Most predictions are concentrated in the lower score ranges, with a peak at the highest score. The distribution shows a clear imbalance, with a large number of models achieving high scores and a smaller number scoring low. A significant portion of the data is clustered around the top score, indicating a performance ceiling effect.
The authors compare their ProDa framework against baseline data synthesis methods, highlighting the importance of traceability and closed-loop debugging. ProDa achieves superior performance with minimal data, demonstrating that targeted, diagnostic-driven repair is more effective than scaling conventional data synthesis. The framework's ability to trace errors to specific knowledge nodes enables precise corrections without significant loss of general capabilities. ProDa outperforms baseline methods at all data scales, achieving state-of-the-art results with minimal data. The integration of diagnostic targeting and closed-loop repair enables significant performance gains, especially with small datasets. ProDa maintains general capabilities while improving domain-specific performance, avoiding catastrophic forgetting.

The authors evaluate the ProDa-16 benchmark and a multi-stage model refinement framework. Results show that the benchmark aligns well with established evaluation standards and provides strong discriminative power across model scales and disciplines. The first-pass fine-tuning produces competitive performance against industry-aligned models, and subsequent diagnostic-driven repair significantly improves accuracy, especially for models with lower initial scores, while preserving general capabilities. ProDa-16 demonstrates strong alignment with established benchmarks and provides effective discrimination across model scales and disciplines. First-pass fine-tuning with automatically synthesized data achieves performance competitive with industry-aligned models, particularly in the Qwen-3 family. Diagnostic-driven targeted repair leads to substantial performance gains, with improvements inversely related to initial performance, and successfully restores general capabilities lost during initial fine-tuning.
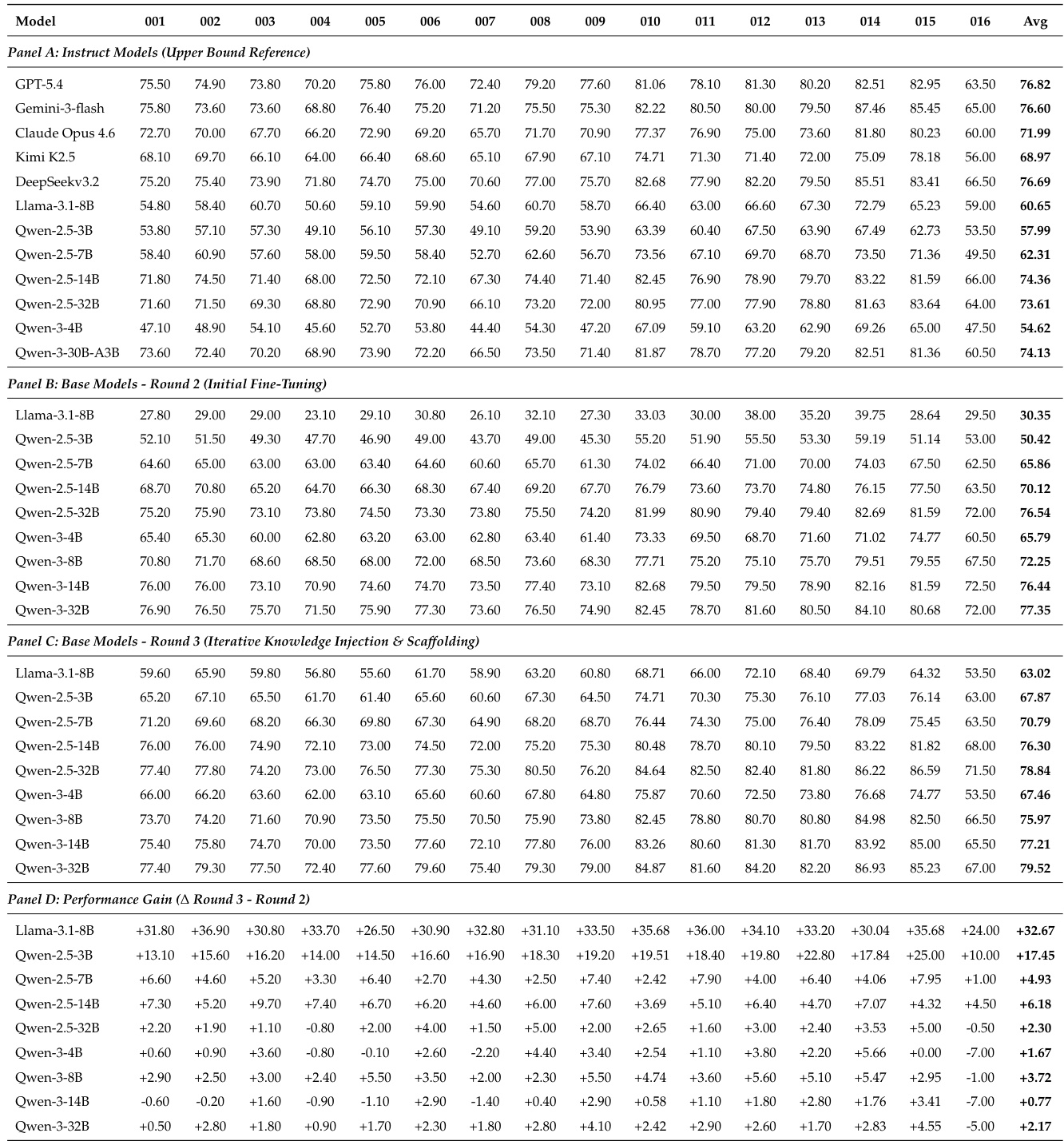
The authors present a comprehensive evaluation of a benchmark across 16 disciplines, demonstrating its statistical consistency with established benchmarks and its ability to discriminate model performance across different parameter scales. The benchmark shows strong alignment with mainstream evaluation standards and maintains discriminative power without ceiling or floor effects, ensuring reliable assessment of model capabilities. The results indicate that the benchmark supports a diagnostic-driven repair framework, where targeted interventions improve model performance while preserving general capabilities. The benchmark exhibits high statistical consistency with established evaluation paradigms and maintains discriminative power across model scales. The benchmark provides consistent diagnostic coverage across all disciplines without ceiling or floor effects, enabling reliable performance assessment. A diagnostic-driven repair framework improves model performance while preserving general capabilities, demonstrating the effectiveness of targeted interventions.
The evaluation compares the ProDa framework against conventional data synthesis methods across varying data scales while assessing the ProDa-16 benchmark for its alignment with established standards and discriminative power across disciplines. These experiments validate that diagnostic-driven targeted repair significantly outperforms unstructured data scaling, particularly when working with minimal datasets, and confirm that the benchmark reliably captures performance variations without ceiling or floor effects. The results demonstrate that iterative closed-loop debugging consistently yields superior performance over baselines, with the V2 iteration showing marked qualitative improvements. Ultimately, the framework successfully enhances domain-specific accuracy while preserving general capabilities, effectively mitigating catastrophic forgetting during model refinement.