Command Palette
Search for a command to run...
Turning the TIDE: Cross-Architecture Distillation for Diffusion Large Language Models
Turning the TIDE: Cross-Architecture Distillation for Diffusion Large Language Models
Gongbo Zhang Wen Wang Ye Tian Li Yuan
Abstract
Diffusion large language models (dLLMs) offer parallel decoding and bidirectional context, but state-of-the-art dLLMs require billions of parameters for competitive performance. While existing distillation methods for dLLMs reduce inference steps within a single architecture, none address cross-architecture knowledge transfer, in which the teacher and student differ in architecture, attention mechanism, and tokenizer. We present TIDE, the first framework for cross-architecture dLLM distillation, comprising three modular components: (1) TIDAL, which jointly modulates distillation strength across training progress and diffusion timestep to account for the teacher's noise-dependent reliability; (2) CompDemo, which enriches the teacher's context via complementary mask splitting to improve predictions under heavy masking; and (3) Reverse CALM, a cross-tokenizer objective that inverts chunk-level likelihood matching, yielding bounded gradients and dual-end noise filtering. Distilling 8B dense and 16B MoE teachers into a 0.6B student via two heterogeneous pipelines outperforms the baseline by an average of 1.53 points across eight benchmarks, yielding notable gains in code generation, where HumanEval scores reach 48.78 compared to 32.3 for the AR baseline.
One-sentence Summary
the paper present TIDE, the first cross-architecture distillation framework for diffusion large language models, which integrates the TIDAL timestep modulation, COMPDEMO complementary mask splitting, and Reverse CALM cross-tokenizer objective to distill 8B dense and 16B MoE teachers into a 0.6B student, yielding a 1.53-point average improvement across eight benchmarks and a HumanEval score of 48.78 compared to the 32.3 autoregressive baseline.
Key Contributions
- This work introduces TIDE, the first framework for cross-architecture distillation in diffusion large language models, enabling knowledge transfer between teacher and student models that differ in architecture, attention mechanisms, and tokenizers.
- The framework integrates three modular components: TIDAL dynamically modulates distillation strength based on timestep-dependent teacher reliability, COMPDEMO enhances predictions under heavy masking through complementary context splitting, and Reverse CALM provides a cross-tokenizer objective that inverts chunk-level likelihood matching to yield bounded gradients and dual-end noise filtering.
- Distilling 8B and 16B parameter teachers into a 0.6B student model yields an average improvement of 1.53 points across eight benchmarks, including a HumanEval score of 48.78 compared to 32.3 for autoregressive baselines.
Introduction
Diffusion language models have emerged as a flexible alternative to autoregressive architectures, yet their rapid diversification into encoder, decoder, and causal variants creates a fragmentation challenge for efficient model deployment. Prior distillation methods for diffusion models are largely confined to same-architecture settings that only compress inference steps, while established autoregressive techniques fail to account for diffusion specific dynamics like timestep-dependent teacher reliability and simultaneous masked token generation. To bridge this gap, the authors introduce TIDE, a cross-architecture distillation framework that transfers knowledge between fundamentally different diffusion models. They adapt interpolation principles and chunk-level likelihood matching to handle architectural and tokenizer mismatches, enabling robust and efficient knowledge transfer across heterogeneous diffusion language model designs.
Dataset
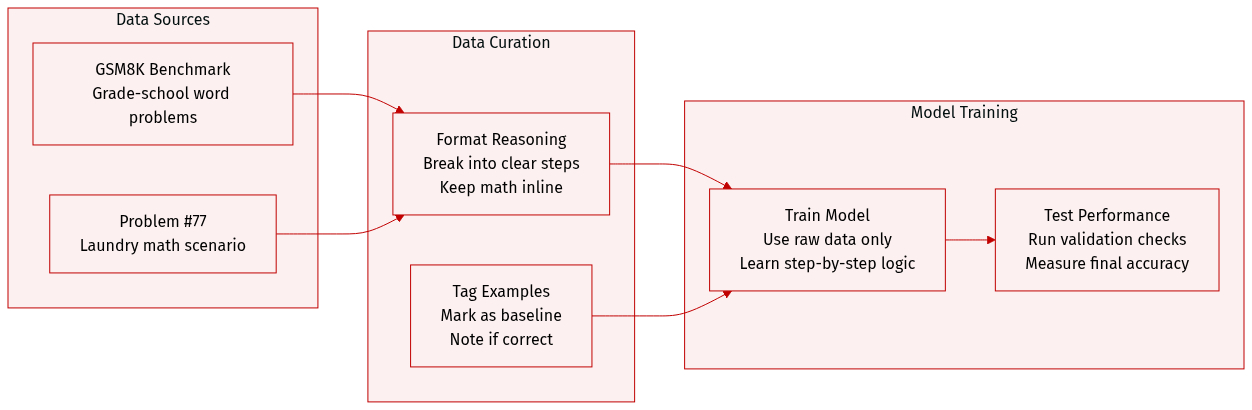
- Dataset Composition and Sources: The authors draw from the GSM8K benchmark, a collection of grade-school mathematics word problems designed to evaluate sequential reasoning capabilities.
- Subset Details: The provided excerpt highlights a specific instance (problem #77) featuring a multi-step arithmetic scenario involving laundry quantities. It is explicitly categorized as a baseline sample without distillation and is flagged as incorrect.
- Data Usage and Processing: The authors incorporate these examples into a no-distillation baseline setup to establish a performance benchmark. The data is processed to include sequential reasoning traces, allowing the model to evaluate or train on stepwise mathematical logic.
- Metadata and Formatting: Each entry is annotated with a problem identifier, a descriptive title indicating the experimental condition, and a correctness label. The reasoning steps are formatted as sequential sentences with inline mathematical expressions to support transparent evaluation.
Method
The TIDE framework addresses the challenge of cross-architecture knowledge distillation for diffusion large language models (dLLMs), where the teacher and student models differ in architecture, attention mechanism, and tokenizer. The overall method consists of three modular components designed to handle the unique challenges of distillation across heterogeneous architectures. The framework is built around a central training loop that processes noisy input sequences, where the student model learns to predict the clean tokens at masked positions using both ground-truth labels and the teacher's predictions. The student model, a 0.6B-parameter block diffusion language model (BD3LM), is trained to distill knowledge from two distinct teacher models: a 16B MoE dLLM (LLaDA2.0-mini) and an 8B dense causal dLLM (WeDLM-8B-Instruct), both of which differ significantly in their foundational structures and tokenization schemes.
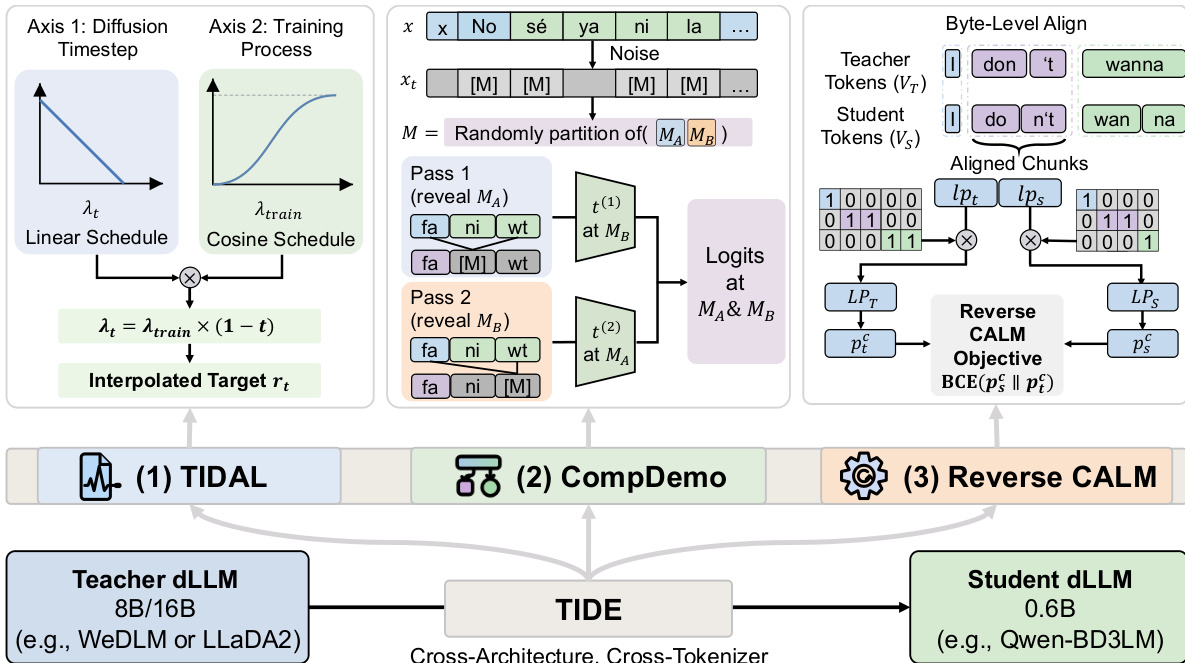
The first component, TIDAL (Time-Iteration Dual-Axis Lambda modulation), tackles the issue of varying teacher signal reliability across diffusion timesteps. In diffusion models, the teacher's predictive confidence is highly dependent on the noise level: at low noise levels (t ≈ 0), the teacher observes nearly the full sequence and produces reliable predictions, while at high noise levels (t ≈ 1), predictions become unreliable due to extensive masking. TIDAL introduces a dual-axis scheduling mechanism that jointly modulates the distillation strength along the diffusion timestep and the training progress. The distillation strength, parameterized by the interpolation coefficient λt, is defined as λt=λtrain×(1−t), where t is the current diffusion timestep. This ensures that the distillation signal is downweighted at high noise levels, preventing the student from learning from unreliable teacher outputs. The base coefficient λtrain itself follows a cosine schedule over the normalized training progress p, starting from a low value (λinit) to avoid representation collapse early in training and gradually increasing to a higher value (λmax) to encourage comprehensive teacher supervision in later stages. The interpolated target rt is formed by combining the student and teacher logits, and the TIDAL loss is computed as a KL divergence between this target and the student's softmax output.
The second component, COMPDEMO (Complementary Demonstration-Conditioned Denoising), addresses the degradation of the teacher's signal under heavy masking. Standard distillation provides the teacher with the same masked input as the student, which can lead to poor predictions. COMPDEMO enriches the teacher's context by partitioning the masked positions into two complementary subsets, MA and MB. The teacher is then run in two forward passes: in the first pass, the tokens at positions MA are revealed as context while MB remains masked, and in the second pass, the roles are reversed. This allows the teacher to produce more accurate predictions at each masked position by leveraging additional context, thereby improving the quality of the distillation signal. The logits from both passes are merged to form the final teacher output for the masked positions.
The third component, Reverse CALM, is designed for robust cross-tokenizer alignment. Traditional CALM objectives, which match chunk-level likelihoods, suffer from gradient instability when the student assigns low initial probability to a chunk that the teacher considers likely. Reverse CALM inverts this objective by using the teacher's probability as a fixed coefficient in the loss gradient, which is bounded and prevents gradient explosion. This creates a stable, self-selecting training signal where the student naturally focuses on the high-probability modes of the teacher. The gradient is further filtered on both ends: poorly aligned chunks (where the teacher's probability is near 0.5) have a zero coefficient, and chunks with low student probability contribute little to the gradient, suppressing noise. This dual-end filtering mechanism provides a more reliable and efficient way to align the student's output with the teacher's across different tokenization schemes.
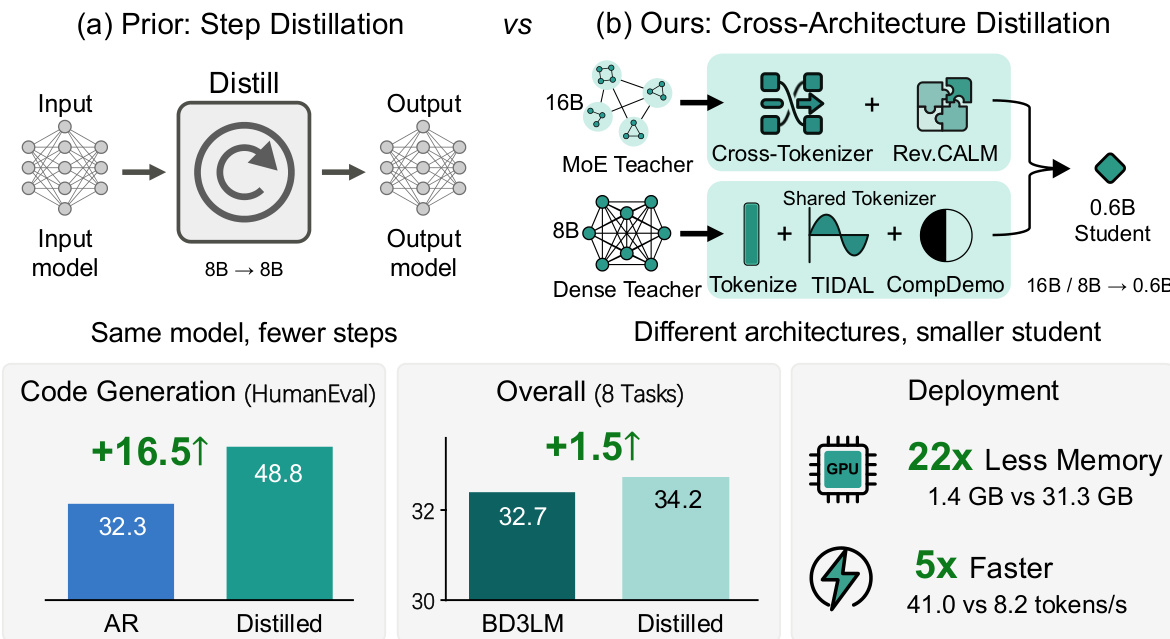
The framework's architecture is designed to be modular and efficient. The student model, Qwen3-0.6B-BD3LM, is trained using a combination of a cross-entropy loss and the three TIDE components. The training process leverages a diverse dataset of SFT data and is conducted over 10 epochs. The overall process enables effective knowledge transfer from large, heterogeneous teachers to a smaller, more efficient student, achieving significant performance gains across multiple benchmarks while reducing memory and inference latency.
Experiment
The evaluation tests the TIDE framework across two distillation pipelines that compress large diffusion language models into a compact student architecture, utilizing benchmark testing, component ablations, and efficiency measurements to validate the approach. Benchmark results confirm that cross-architecture knowledge transfer is effective, with each pipeline benefiting from tailored strategies that address vocabulary misalignment or exact token alignment. Ablation and case study experiments validate that temporal scheduling and contextual enrichment are critical for stable learning, enabling the distilled models to inherit teacher-specific reasoning patterns and correct baseline failures in arithmetic and code generation. Ultimately, the experiments demonstrate that TIDE successfully enables efficient deployment by significantly reducing computational overhead while delivering substantial quality improvements over autoregressive counterparts.
The authors evaluate a distillation framework for diffusion language models across two distinct pipelines, one using a shared tokenizer and the other a cross-tokenizer setup, both targeting a smaller student model. Results show that the framework improves performance over a non-distilled baseline, with each pipeline benefiting from a specific strategy tailored to its architecture. The distilled models achieve higher scores on code generation tasks compared to an autoregressive baseline of the same size. The distillation framework improves performance across two distinct pipelines, with each pipeline benefiting from a strategy tailored to its architecture. The distilled models achieve higher scores on code generation tasks compared to an autoregressive baseline of the same size. The framework demonstrates that cross-architecture distillation is effective and enables practical deployment with significant memory and speed improvements.
The authors evaluate a distillation framework for diffusion language models, comparing performance across different benchmarks and teacher models. The distilled student model consistently outperforms the non-distilled baseline, with notable improvements on code generation tasks. Each distillation pipeline benefits from a distinct strategy tailored to its specific architecture and tokenizer setup. The distilled model achieves higher scores than the non-distilled baseline across all benchmarks, with the most significant gains on code generation tasks. The cross-tokenizer pipeline benefits from a strategy that uses reverse KL divergence, while the shared-tokenizer pipeline performs better with a progressive curriculum and enriched teacher signals. Distillation leads to substantial improvements in performance, particularly on structured tasks like code generation, while maintaining inference efficiency.
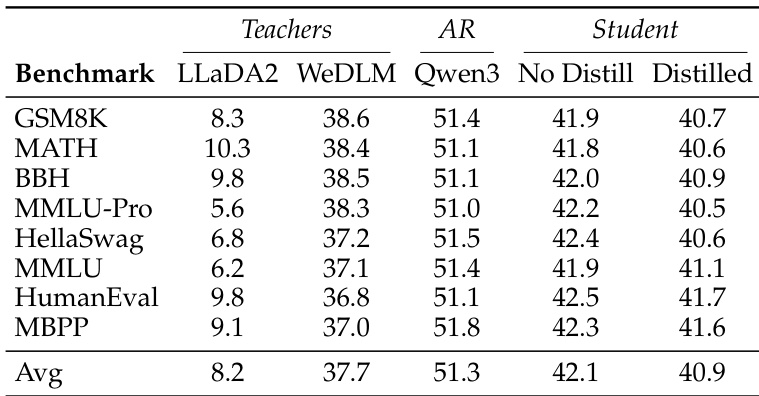
The authors evaluate a cross-architecture distillation framework for diffusion language models, comparing two distinct pipelines: one using a shared tokenizer and another using a cross-tokenizer approach. Results show that the framework improves performance across benchmarks, with each pipeline benefiting from a distinct strategy tailored to its specific architecture. The distilled models significantly outperform baseline models, particularly in code generation tasks, while maintaining efficient inference with reduced memory and latency. The framework improves average performance across benchmarks, with the cross-tokenizer pipeline achieving the highest overall score. Each pipeline benefits from a distinct strategy, with the shared-tokenizer pipeline favoring a progressive curriculum and the cross-tokenizer pipeline benefiting from bounded gradients and noise filtering. Distilled models excel in code generation, outperforming same-sized autoregressive models on HumanEval and MBPP benchmarks.
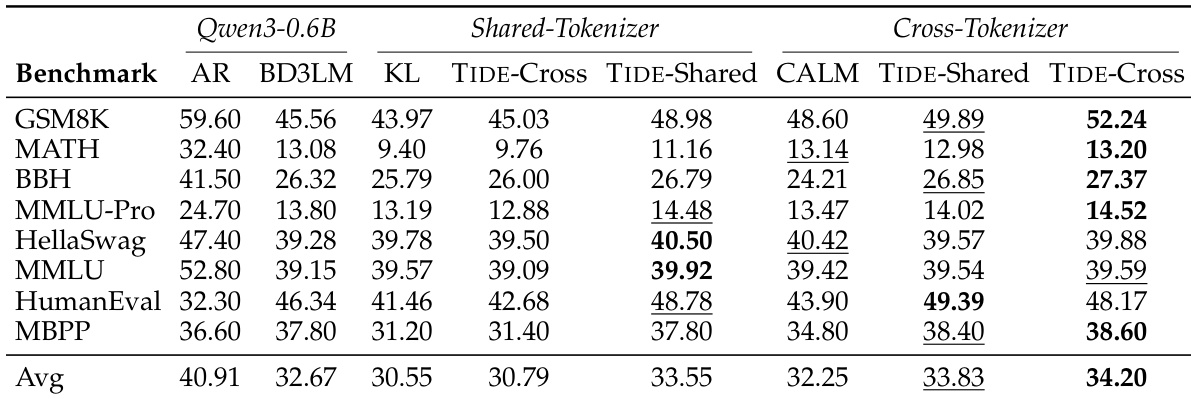
The authors evaluate a distillation framework for diffusion language models across two distinct pipelines, demonstrating that cross-architecture distillation improves performance over non-distilled baselines. The framework incorporates modular components that address temporal, spatial, and vocabulary challenges, with each pipeline benefiting from a distinct optimal strategy. Distilled models show strong performance on code generation tasks, outperforming same-sized autoregressive models. The results highlight that different distillation approaches resolve different types of errors, with each teacher model imparting unique knowledge. Cross-architecture distillation improves performance over non-distilled baselines across multiple benchmarks. Each pipeline favors a distinct strategy, with the cross-tokenizer pipeline benefiting from Reverse CALM and the shared-tokenizer pipeline benefiting from TIDAL and COMPDEMO. Distilled models excel at code generation, successfully resolving specific errors that the baseline model fails to address.
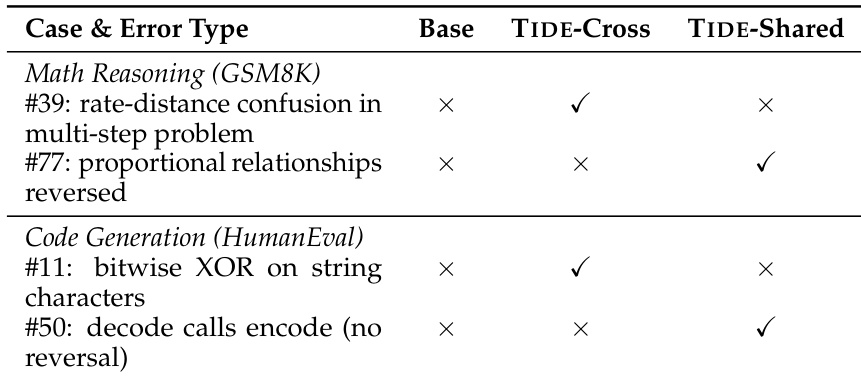
The authors evaluate a distilled model and its baseline against larger teacher models, demonstrating that distillation reduces memory usage and latency while maintaining competitive inference speed. The distilled model achieves lower memory consumption and slower inference compared to the baseline, but the trade-off is justified by significant performance improvements in code generation tasks. The results show that the distilled model outperforms the undistilled version in both efficiency and task-specific capabilities. Distillation reduces peak memory usage and inference latency compared to larger teacher models. The distilled model achieves competitive inference speed with only a minor reduction in throughput relative to the undistilled baseline. Distilled models show superior performance on code generation tasks compared to the same-size autoregressive baseline.
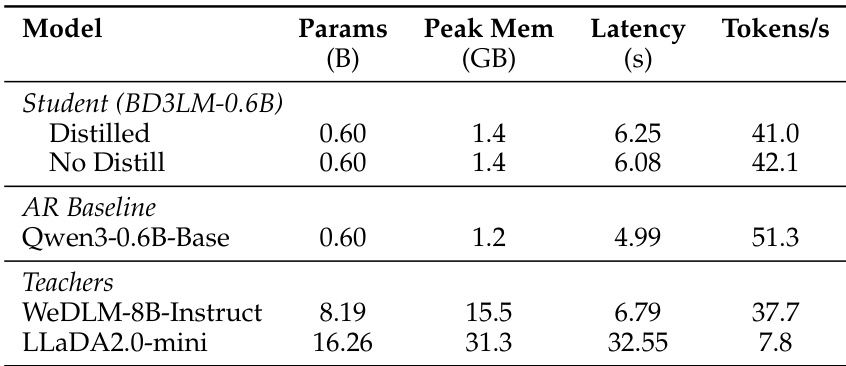
The authors evaluate a cross-architecture distillation framework for diffusion language models across shared and cross-tokenizer pipelines, comparing distilled student models against both non-distilled baselines and same-sized autoregressive counterparts. The experiments validate that architecture-specific training strategies effectively transfer knowledge, enabling the framework to consistently elevate performance across diverse benchmarks. Qualitatively, the distilled models exhibit stronger capabilities in structured tasks like code generation by successfully resolving error patterns that baseline models cannot address. Additionally, the approach substantially lowers memory consumption and inference latency while preserving competitive throughput, demonstrating clear practical advantages for efficient model deployment.