Command Palette
Search for a command to run...
MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
Abstract
Recent progress in multimodal large language models (MLLMs) has brought AI capabilities from static offline data processing to real-time streaming interaction, yet they still remain far from human-level multimodal interaction. The key bottlenecks are no longer modality coverage or latency alone, but the interaction paradigm itself. First, perception and response are still separated into alternating phases, preventing models from incorporating new inputs for timely adjustment during generation. Second, most current models remain reactive, responding only to explicit user requests instead of acting proactively in the evolving multimodal environment. We present MiniCPM-o 4.5, our latest effort towards human-like multimodal interaction, which mitigates these gaps by real-time full-duplex omni-modal interaction. It can see, listen, and speak simultaneously in real-time, while also exhibiting proactive behaviors such as issuing reminders or comments based on its continuous understanding of the live scene. The key technique behind MiniCPM-o 4.5 is Omni-Flow, a unified streaming framework that aligns omni-modal inputs and outputs along a shared temporal axis. This formulation converts conventional turn-based interaction into a full-duplex, time-aligned process, enabling simultaneous perception and response and allowing proactive behavior to arise within the same framework.
One-sentence Summary
MiniCPM-o 4.5 enables real-time full-duplex omni-modal interaction via Omni-Flow, a unified streaming framework that aligns omni-modal inputs and outputs along a shared temporal axis to convert conventional turn-based interaction into a time-aligned process enabling the model to see, listen, and speak simultaneously while exhibiting proactive behaviors within evolving multimodal environments.
Key Contributions
- MiniCPM-o 4.5 is presented as a 9B parameter model designed for real-time full-duplex omni-modal interaction that allows simultaneous perception and response. This architecture achieves practical edge efficiency by running with less than 12GB RAM while supporting flexible switching between streaming and traditional turn-based modes.
- A unified streaming framework called Omni-Flow aligns omni-modal inputs and outputs along a shared temporal axis to convert conventional turn-based interaction into a full-duplex process. This formulation enables the model to incorporate new inputs for timely adjustment during generation and supports proactive behaviors such as issuing reminders based on continuous scene understanding.
- Extensive evaluations demonstrate that the model approaches Gemini 2.5 Flash in vision-language capabilities and delivers state-of-the-art open-source performance at its scale. The model also surpasses Qwen3-Omni-30B-A3B in omni-modal understanding and speech generation quality while maintaining significantly higher computational efficiency.
Introduction
Recent progress in multimodal large language models has shifted capabilities from static data processing to real-time streaming, yet current systems still fall short of human-level interaction due to rigid paradigms. Existing models typically separate perception and response into alternating phases, which prevents timely adjustments during generation and restricts behavior to reactive requests rather than proactive engagement. The authors address these limitations with MiniCPM-o 4.5, a 9B parameter model designed for real-time full-duplex omni-modal interaction. Their key innovation is the Omni-Flow framework, which aligns multimodal inputs and outputs along a shared temporal axis to enable simultaneous seeing, listening, and speaking. This architecture allows the model to exhibit proactive behaviors and maintain high computational efficiency on edge devices while achieving state-of-the-art performance.
Dataset
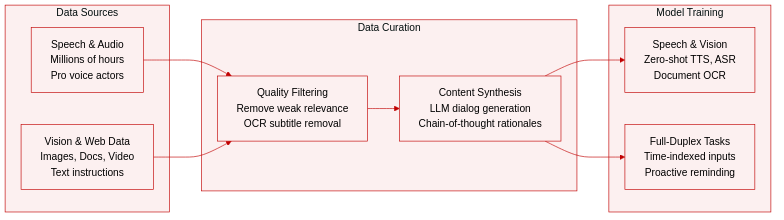
- Speech Data: The authors process millions of hours of unlabeled speech from diverse sources to yield training sets for zero-shot TTS, ASR, and multi-turn multi-speaker dialogue. High-quality dialog data involves colloquial instruction-following dialogue generated by a text-based LLM and re-recorded by professional voice actors under studio conditions. Actors deliver in a conversational style with varied emotion and speaking rates rather than reading scripts verbatim.
- Vision-Language Data: Building on the MiniCPM-V 4.5 system, the team expands scale and quality to cover broader task types and real-world scenarios. Knowledge and alignment data utilize an updated CapsFusion generator to synthesize informative image captions and refine image-text relevance estimation. Complex document and OCR data employ a relevance-aware masking strategy that prioritizes regions relevant to figures and charts to encourage visual grounding.
- Real-World and Video Data: Real-world scenario samples feature natural query patterns where short answers are rewritten into detailed chain-of-thought-style rationales and filtered by a reward-model-based pipeline. Dense video perception data provides continuous fine-grained descriptions of temporal events, human actions, and complex scene transitions. Text-only instruction data is incorporated from the MiniCPM 4.1 post-training dataset to maintain robust linguistic capabilities.
- Omni-Modal Full-Duplex Data: This subset includes both large-scale web data and high-quality instruction samples where each training sample contains full visual and audio inputs alongside output text and speech tagged with a time index. Large-scale web audio-video data is filtered to remove segments dominated by single-speaker speech or weak audio-visual relevance. Quality improvements apply OCR-based subtitle removal, talking-head detection, and filtering over ASR-derived transcripts. Manually constructed full-duplex task data supports advanced capabilities like continuous scene description and proactive reminding.
Method
The authors introduce MiniCPM-o 4.5, an end-to-end omni-modal architecture designed to unify text, vision, and audio processing. This system supports both full-duplex interaction under the Omni-Flow framework and conventional turn-based inference. The evolution of interaction capabilities leading to this model is illustrated in the timeline below, showing the progression from text-only models to the current full-duplex system.

Existing paradigms often suffer from blocked I/O and passive responding, where perception and response occur in alternating phases. To overcome these limitations, the authors introduce the Omni-Flow framework, which coordinates omni-modal input and output streams along a shared temporal axis. This approach partitions continuous interaction into fine-grained time windows, allowing the model to perceive and speak simultaneously. The comparison below highlights the limitations of traditional streaming versus the proactive, full-duplex capabilities of the proposed system.
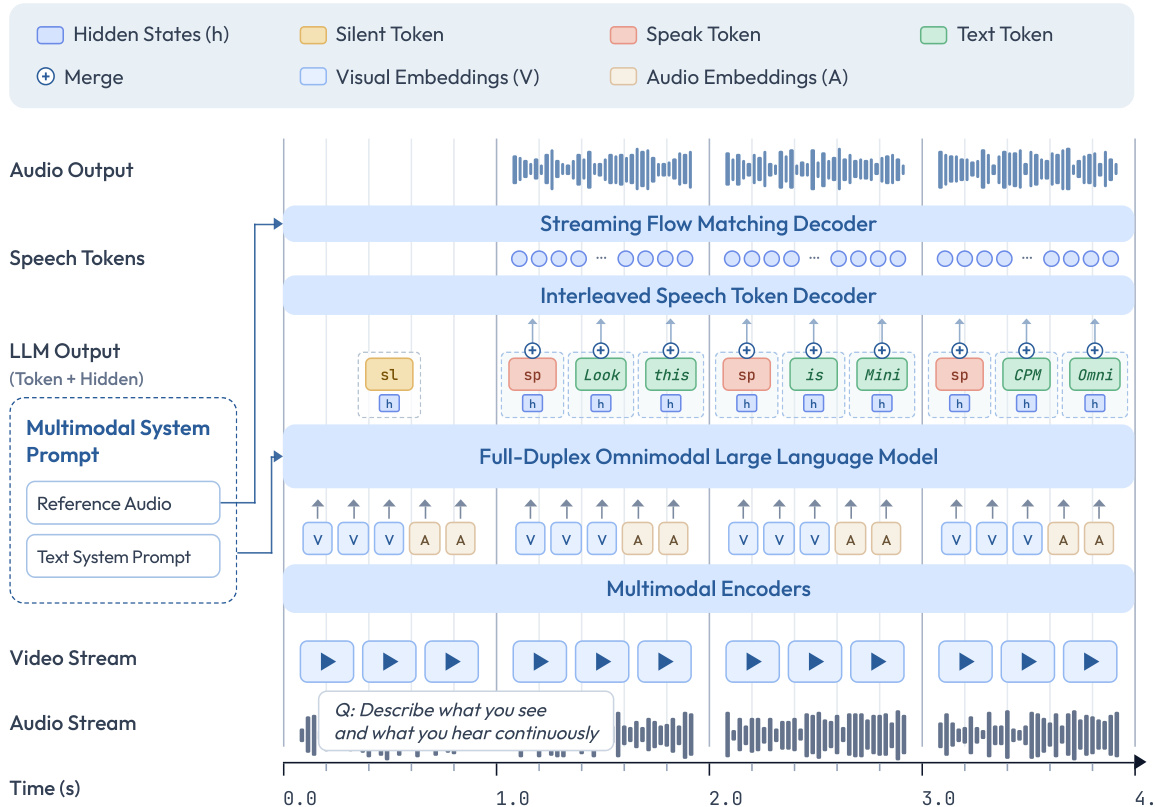
The core architecture consists of three main components connected via token-level hidden states. First, multimodal encoders process visual and audio inputs in a streaming manner. Visual encoding utilizes an LLaVA-UHD strategy with a SigLIP ViT and a resampler module to achieve a high compression ratio. Audio encoding employs a Whisper Medium encoder in a chunk-based streaming fashion. Second, an LLM backbone (Qwen3-8B) performs omni-modal understanding and text generation. Third, speech decoders handle output generation. This includes an interleaved speech token decoder that autoregressively generates discrete speech tokens and a streaming flow-matching decoder that converts these tokens into audio waveforms.
The detailed flow of data through these modules is shown in the architecture diagram below.
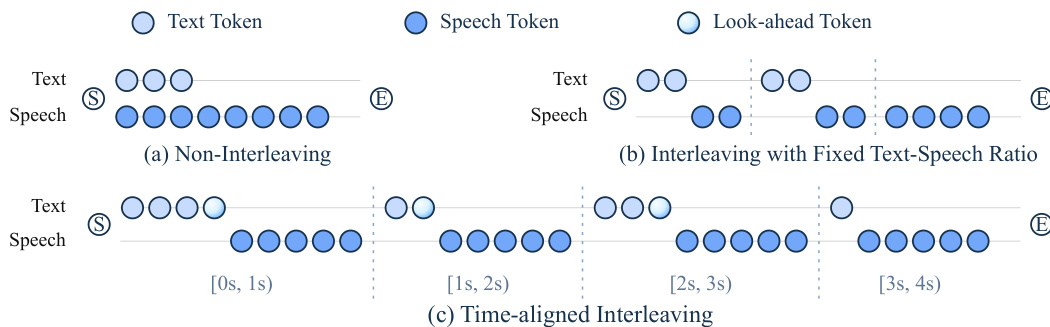
A critical challenge in streaming speech generation is maintaining temporal alignment between the spoken output and the latest observed context. Standard methods often result in speech lagging behind the model's evolving state. To address this, the authors propose Time-Aligned Interleaving (TAIL). Unlike non-interleaving or fixed-ratio strategies, TAIL adaptively controls the amount of text generated at each step to ensure the speech stream remains close to the current time boundary. The effectiveness of this time-aligned strategy compared to other methods is visualized below.
The training pipeline for MiniCPM-o 4.5 follows a carefully staged process to integrate speech capabilities smoothly. It begins with speech pretraining to establish foundational audio understanding while freezing the pretrained visual and linguistic components. This is followed by joint pretraining on a balanced mixture of vision-language, speech, and omni-modal data to construct unified cross-modal representations. Subsequent joint supervised fine-tuning strengthens instruction following across all modalities. Finally, reinforcement learning is applied to enhance reasoning abilities and mitigate hallucinations using rewards for accuracy and token efficiency.
Experiment
The evaluation comprehensively assesses MiniCPM-o 4.5 across vision-language, speech, text, and omni-modal streaming capabilities using diverse benchmarks to validate its holistic performance. Results demonstrate that the model achieves state-of-the-art open-source performance in vision-language understanding and speech generation while successfully preserving core text abilities despite omni-modal training. Ablation studies further confirm that temporal granularity and control formulation choices enhance full-duplex interaction stability, while optimized inference frameworks ensure efficient real-time deployment on consumer hardware.
The authors evaluate speech generation capabilities across intelligibility, speaker similarity, and emotional control metrics. Results indicate that MiniCPM-o 4.5 achieves superior speech clarity and expressive control compared to baseline models. The model demonstrates high reliability in bilingual generation and significantly better stability for long-form English content. MiniCPM-o 4.5 achieves superior intelligibility in both Chinese and English compared to baseline models. The model demonstrates significantly better stability for long-form English generation than competitors. MiniCPM-o 4.5 outperforms baselines in emotion and style control capabilities.

The authors evaluate full-duplex streaming interaction capabilities using the LiveSports-3K-CC benchmark to assess continuous visual interaction. MiniCPM-o 4.5 demonstrates superior performance compared to baseline models, achieving the highest win rate among the compared systems. These results suggest that the proposed Omni-Flow design effectively organizes perception and response along a shared timeline for better scene grounding. MiniCPM-o 4.5 achieves the highest performance on the LiveSports-3K-CC benchmark. The model significantly outperforms LiveCC and StreamingVLM baselines. Results indicate the Omni-Flow design is effective for continuous visual interaction.

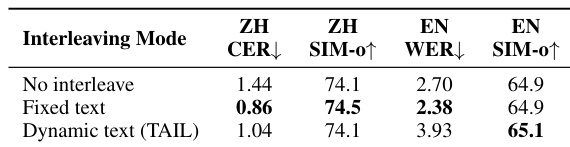
The authors present a comprehensive evaluation of MiniCPM-o 4.5 against competing models across automatic speech recognition, translation, and audio understanding tasks. Results demonstrate that the 9B parameter model achieves leading performance in speech translation and specific question answering benchmarks, often surpassing larger 30B models. However, the evaluation also highlights specific areas where performance gaps persist, particularly in complex factual speech question answering. MiniCPM-o 4.5 achieves leading results in speech translation and specific audio understanding tasks like MELD, often surpassing larger 30B models. The model demonstrates strong automatic speech recognition capabilities, securing top scores on GigaSpeech and VoxPopuli benchmarks. Performance remains strong in trivia-based speech QA but shows gaps in retrieval-like factual and Chinese speech knowledge tasks compared to baselines.
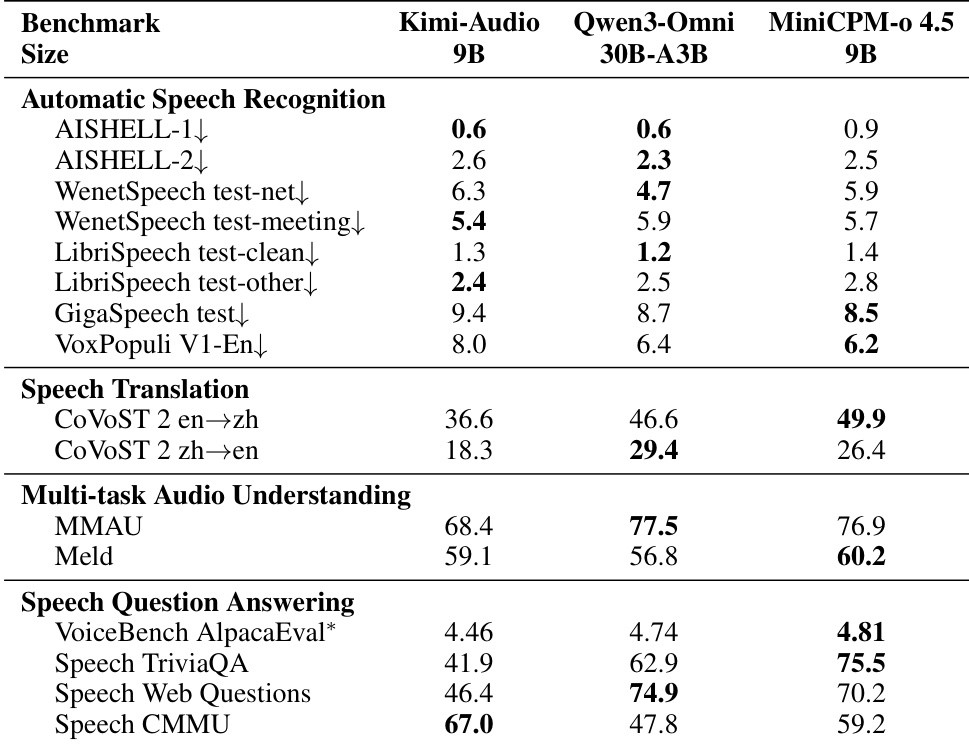
The authors evaluate inference efficiency on a single NVIDIA RTX 4090, comparing MiniCPM-o 4.5 against the larger Qwen3-Omni-30B-A3B model. Results indicate that the larger model fails to run in BF16 precision due to memory constraints, whereas MiniCPM-o 4.5 operates successfully with significantly lower memory requirements. In INT4 quantization, MiniCPM-o 4.5 demonstrates superior throughput and latency while consuming substantially less memory than the baseline. MiniCPM-o 4.5 runs successfully in BF16 while the larger Qwen3-Omni-30B-A3B model encounters out-of-memory errors. Under INT4 quantization, MiniCPM-o 4.5 achieves higher throughput and lower latency compared to the baseline. The proposed model maintains a significantly lower memory footprint, using approximately half the memory required by Qwen3-Omni-30B-A3B in INT4 mode.
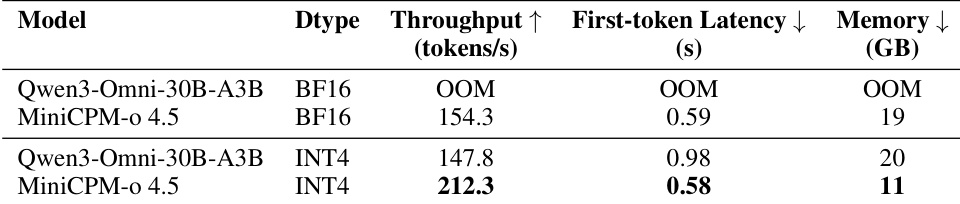
The authors evaluate three speech generation modes to assess the impact of interleaving on quality and interaction capabilities. Fixed text interleaving demonstrates superior recognition accuracy in both Chinese and English compared to the other modes, suggesting that chunked streaming generation improves pronunciation. The dynamic text interleaving strategy, designed for full-duplex interaction, trades a small amount of recognition accuracy for improved speaker similarity in English. Fixed text interleaving results in the lowest character and word error rates. Dynamic text interleaving achieves the highest speaker similarity score for English. Both interleaving strategies outperform the non-interleaved baseline in recognition accuracy.
The authors evaluate MiniCPM-o 4.5 across speech generation, full-duplex streaming, audio understanding, and inference efficiency to validate its capabilities against competing models. Results indicate superior performance in speech clarity, emotional control, and continuous visual interaction, with the model often surpassing larger baselines in translation and recognition tasks despite some gaps in complex factual question answering. Furthermore, the system demonstrates significant efficiency advantages and achieves optimal quality through specific text interleaving strategies for recognition and speaker similarity.