Command Palette
Search for a command to run...
FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
Quanjian Song Yefeng Shen Mengting Chen Hao Sun Jinsong Lan Xiaoyong Zhu Bo Zheng Liujuan Cao
Abstract
Human-centric video customization, particularly at the garment level, has shown significant commercial value. However, existing approaches cannot support low-latency and interactive garment control, which is crucial for applications such as e-commerce and content creation. This paper studies how to achieve interactive multi-garment video customization while preserving motion coherence using only single-garment video data. We present FashionChameleon, a real-time and interactive framework for human-garment customization in autoregressive video generation, where users can interactively switch garment during generation. FashionChameleon consists of three key techniques: (i) Instead of training on multi-garment video data, we train a Teacher Model with In-Context Learning on a single reference-garment pair. By retaining the image-to-video training paradigm while enforcing a mismatch between the reference and garment image, the model is encouraged to implicitly preserve coherence during single-garment switching. (ii) To achieve consistency and efficiency during generation, we introduce Streaming Distillation with In-Context Learning, which fine-tunes the model with in-context teacher forcing and improves extrapolation consistency via gradient-reweighted distribution matching distillation. (iii) To extend the model for interactive multi-garment video customization, we propose Training-Free KV Cache Rescheduling, which includes garment KV refresh, historical KV withdraw, and reference KV disentangle to achieve garment switching while preserving motion coherence. Our FashionChameleon uniquely supports interactive customization and consistent long-video extrapolation, while achieving real-time generation at 23.8 FPS on a single GPU, 30-180times faster than existing baselines.
One-sentence Summary
FashionChameleon is a real-time, interactive framework for autoregressive human-garment video customization that enables dynamic garment switching during generation by leveraging in-context learning on single-reference data, enforcing a mismatched reference-image training paradigm to preserve motion coherence, and applying streaming distillation with in-context teacher forcing to ensure low-latency performance for e-commerce and content creation.
Key Contributions
- Introduces FashionChameleon, a real-time interactive framework for human-garment customization in autoregressive video generation that enables dynamic garment switching during synthesis while preserving motion coherence.
- Achieves multi-garment control using only single-garment reference pairs by training a teacher model with in-context learning and enforcing a deliberate mismatch between reference and target garment images to implicitly maintain temporal consistency.
- Integrates streaming distillation with in-context teacher forcing and gradient-reweighted distribution matching distillation to reduce inference latency and improve extrapolation consistency across generated video sequences.
Introduction
The authors build upon recent advances in diffusion-based video generation, where subject-to-video customization enables users to inject reference concepts into generated content. Garment-level control is particularly valuable for e-commerce and filmmaking, yet existing methods suffer from high inference latency, limited interactivity, and difficulty maintaining motion consistency while dynamically switching clothing. To address these gaps, the authors introduce FashionChameleon, a real-time interactive framework that adapts hybrid autoregressive generation for streaming human-garment customization. The authors leverage a teacher network with in-context learning to generalize from single-garment data, employ streaming distillation to balance efficiency and long-video consistency, and utilize a training-free KV cache rescheduling mechanism to enable seamless, dynamic garment transitions during generation.
Dataset
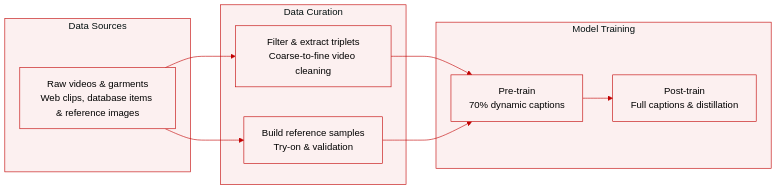
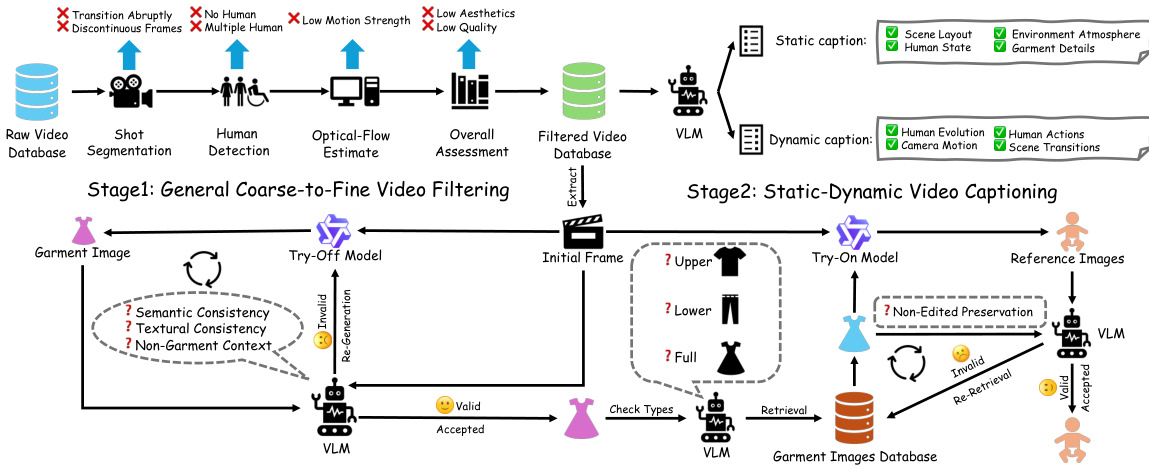
• Dataset Composition and Sources: The authors curate a primary training dataset and an evaluation benchmark called HGC-Bench. Both are built around triplets consisting of a reference image, a garment image, and a video sequence paired with structured prompts. Raw videos are collected from the internet, garment images are drawn from a dedicated database, and reference images are algorithmically constructed to improve training robustness.
• Subset Details and Filtering Rules: The training pipeline initially yields approximately 82K triplets, which are reduced to 62K after manual verification. Videos undergo a four-stage coarse-to-fine filtering process: scene segmentation into 3 to 5 second clips, single-person retention using YOLOv8-Seg, motion filtering via optical flow thresholds, and quality assessment with Q-Align and FAST-VQA-M. The HGC-Bench subset contains 240 high-aesthetic samples where faces are anonymized through swapping, paired with database garments, and accompanied by prompts generated under strict movement and formatting guidelines.
• Model Usage and Training Configuration: For both pre-training and streaming distillation post-training, the authors sample 81 frame sequences and resize videos and reference images to 1280 by 704 pixels while preserving aspect ratios. Garment images are center-padded to match this resolution. During pre-training, the authors apply a 70 to 30 mixture ratio of dynamic-only captions to full static-dynamic captions to reduce textual reliance. Post-training switches to full captions for improved performance. The pipeline leverages Fully Sharded Data Parallelism with a global batch size of 64, using AdamW optimization and precision settings that keep the VAE in float32 during pre-training and switch to bfloat16 for both components during post-training.
• Metadata Construction and Processing Details: The authors implement a static-dynamic decoupling strategy using Gemini-3.1 to generate bilingual Chinese and English captions formatted in JSON. Garment extraction relies on Qwen-Image-Edit followed by a three-stage VLM validation check for semantic, textural, and contextual consistency. Reference images are dynamically constructed by classifying garment types, retrieving compatible items from the database, and applying image try-on models, with VLM verification ensuring non-edited regions remain unchanged. During interactive inference, garment-related terms are explicitly excluded from prompts to prevent conflicts with the visual input.
Method
The authors leverage a three-component framework to achieve real-time and interactive garment customization in autoregressive video generation. The overall architecture, as illustrated in the framework diagram, consists of a Teacher Model trained with in-context learning, a streaming distillation process for efficient inference, and a training-free KV cache rescheduling mechanism for dynamic garment switching while preserving motion coherence.
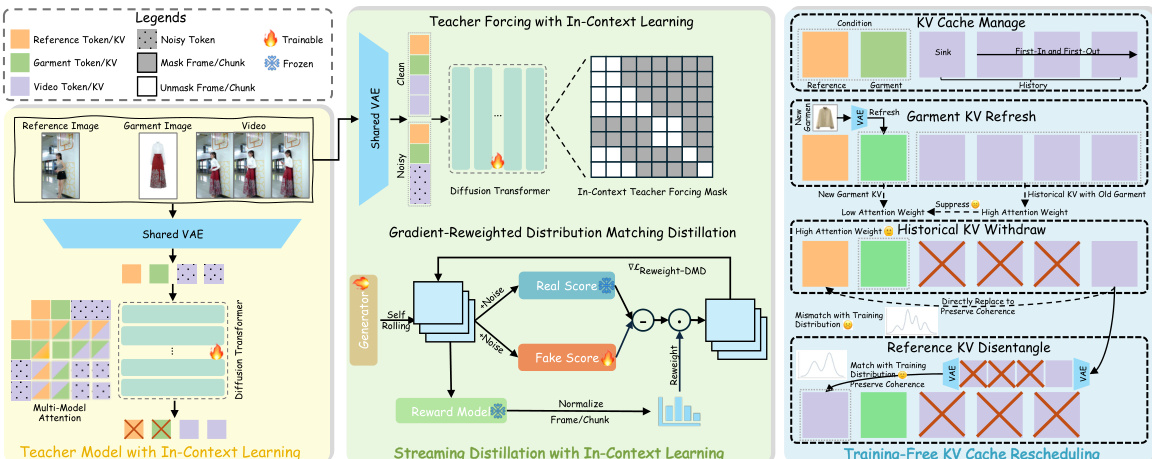
The foundation of the system is the Teacher Model, which is trained using in-context learning on a single reference-garment pair. This model operates within a unified backbone network that processes discrete reference and garment images without requiring auxiliary encoders. The training retains the image-to-video (I2V) paradigm, ensuring the first generated frame remains consistent with the reference frame, except for the garment information. To achieve this, the reference image and garment image are separately encoded into latent representations using a shared VAE encoder. These latent representations, along with the noisy video latent, are concatenated and passed through a multi-modal attention mechanism within the transformer. This shared attention mechanism enables global interaction between the conditional and video latents without introducing additional parameters, allowing the model to implicitly learn single-garment switching while maintaining coherence.

To enable real-time generation, the pretrained teacher model is distilled into a few-step autoregressive student model. This distillation process, known as Streaming Distillation with In-Context Learning, employs an in-context teacher forcing mask to stabilize training. This mask allows the model to condition on ground-truth historical frames and conditional signals during generation, which is essential for the in-context learning setup. Following teacher forcing, gradient-reweighted distribution matching distillation is applied to improve extrapolation consistency. This technique uses an aesthetic reward model to estimate frame quality during distillation, normalizing the scores into frame-wise gradient weights. This adaptive reweighting increases the influence of low-quality frames and decreases that of high-quality ones, mitigating error accumulation and drift in later frames during self-rolling generation.
For interactive multi-garment video customization, the system employs Training-Free KV Cache Rescheduling. This mechanism manages the key-value (KV) cache to enable stable long-video extrapolation. It consists of three key operations: Garment KV Refresh, which updates the garment's KV entry in the cache to switch the outfit; Historical KV Withdraw, which removes historical KV entries to reduce the model's reliance on old garment context and allow the new garment to take effect; and Reference KV Disentangle, which replaces the old reference KV with a new one derived from the last historical frame to maintain temporal coherence across the switching point. The framework diagram illustrates how these operations work together to achieve seamless garment switching while preserving coherent human motion.
Experiment
The evaluation establishes a comprehensive benchmark comparing the proposed autoregressive streaming distillation framework against leading multi-reference video generation baselines, validating its ability to maintain character identity, garment fidelity, and motion coherence through both automated assessments and human preference studies. Qualitative analyses demonstrate that the method consistently preserves fine-grained clothing details and natural movement across complex poses and extended sequences, effectively mitigating the appearance degradation and temporal incoherence observed in competing approaches. Ablation studies further validate that specific training strategies and cache rescheduling mechanisms are essential for preventing motion collapse during long-video extrapolation and enabling real-time interactive garment switching. Overall, the experiments confirm that the framework delivers superior visual quality and temporal consistency while unlocking interactive customization capabilities that existing bidirectional models cannot achieve.
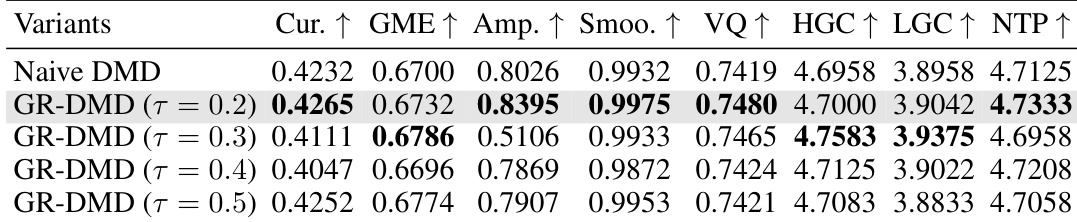
The the the table presents a quantitative ablation study comparing different variants of Gradient-Reweighted Distribution Matching Distillation (GR-DMD) with varying temperature coefficients. Results show that the variant with a temperature of 0.2 achieves the best performance across multiple metrics, including temporal smoothness, visual quality, and garment consistency. Other variants exhibit lower performance, with some showing significant drops in key areas like motion magnitude and temporal smoothness. The variant with a temperature coefficient of 0.2 achieves the best performance across multiple metrics. Higher temperature values lead to a noticeable decline in motion magnitude and temporal smoothness. The variant with a temperature of 0.2 outperforms others in visual quality and garment consistency metrics.
The authors present a comparison of various methods for human-garment video customization, focusing on metrics such as identity consistency, text alignment, motion magnitude, temporal smoothness, visual quality, and garment consistency. FashionChameleon achieves the highest scores in several key areas, including temporal smoothness, visual quality, and garment consistency, while also demonstrating superior inference efficiency compared to other methods. FashionChameleon outperforms all baselines in temporal smoothness, visual quality, and garment consistency metrics. FashionChameleon achieves the highest inference efficiency, enabling real-time generation at a significantly higher frames per second than other methods. The method ranks second in identity consistency and motion magnitude, closely following the top-performing baselines.
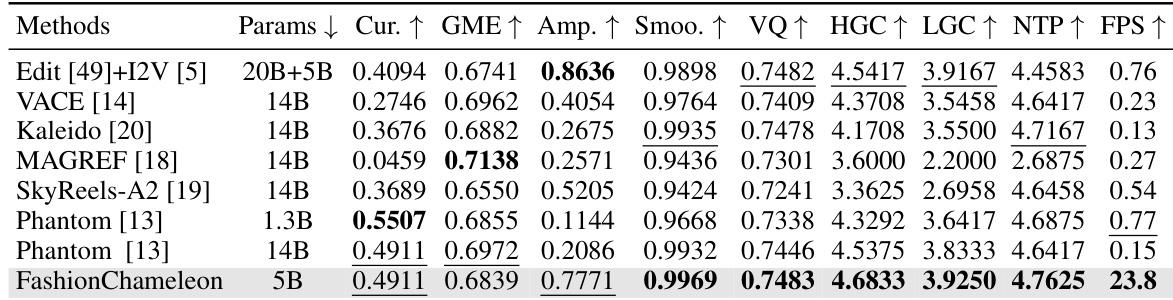
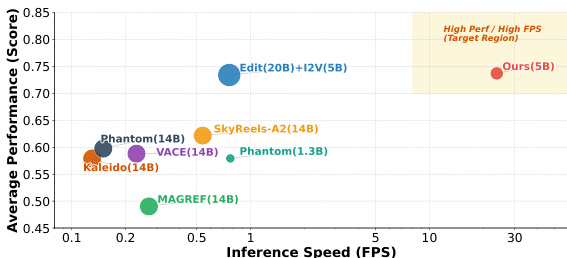
The authors present a comparison of different methods on a performance-efficiency trade-off, where the proposed method achieves the highest average performance and significantly higher inference speed compared to other approaches. Results show that the proposed method outperforms baselines in both efficiency and effectiveness, placing it in a superior region of the performance-speed space. The proposed method achieves the highest average performance among all compared methods. The proposed method demonstrates significantly higher inference speed than other methods. The proposed method outperforms baselines in both performance and efficiency, placing it in a superior region of the performance-speed trade-off space.
The authors compare different teacher model training strategies in an ablation study, focusing on their impact on video generation quality. The results show that the proposed method, which uses in-context learning with full fine-tuning, achieves superior performance across multiple metrics, particularly in temporal smoothness, visual quality, and garment consistency. The best-performing variant outperforms alternatives that use different fine-tuning methods or concatenation-based approaches. The proposed method with in-context learning and full fine-tuning outperforms alternatives in key metrics including temporal smoothness and visual quality. The best variant achieves the highest scores in garment consistency and non-target garment preservation. The method using full fine-tuning consistently outperforms those using attention or LoRA fine-tuning across most evaluation metrics.

The evaluation framework comprises ablation studies and comparative analyses that validate the optimal temperature settings for distribution matching distillation and the effectiveness of different teacher model training strategies. These experiments demonstrate that a moderate temperature coefficient combined with full fine-tuning and in-context learning consistently enhances temporal coherence, visual fidelity, and garment preservation. Comparative assessments against existing baselines further validate the method's superiority in video customization quality while confirming its significantly faster inference speeds. Ultimately, the approach establishes a highly efficient solution that successfully balances computational performance with high-fidelity human-garment video synthesis.