HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

Superposition Yields Robust Neural Scaling

Optimal Mistake Bounds for Transductive Online Learning





























Superposition Yields Robust Neural Scaling
Optimal Mistake Bounds for Transductive Online Learning
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Evolution Strategies at the Hyperscale
Does Understanding Inform Generation in Unified Multimodal Models? From Analysis to Path Forward
iMontage: Unified, Versatile, Highly Dynamic Many-to-many Image Generation
Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
MedSAM3: Delving into Segment Anything with Medical Concepts
SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
Fidelity-Aware Recommendation Explanations via Stochastic Path Integration
Extracting Interaction-Aware Monosemantic Concepts in Recommender Systems
MSRNet: A Multi-Scale Recursive Network for Camouflaged Object Detection
Budget-Aware Tool-Use Enables Effective Agent Scaling
In-Video Instructions: Visual Signals as Generative Control
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
AICC: Parse HTML Finer, Make Models Better -- A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser
UltraFlux: Data-Model Co-Design for High-quality Native 4K Text-to-Image Generation across Diverse Aspect Ratios
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Computer-Use Agents as Judges for Generative User Interface
AutoEnv: Automated Environments for Measuring Cross-Environment Agent Learning
General Agentic Memory Via Deep Research
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
MIST: Mutual Information Via Supervised Training
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Flow Map Distillation Without Data
Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
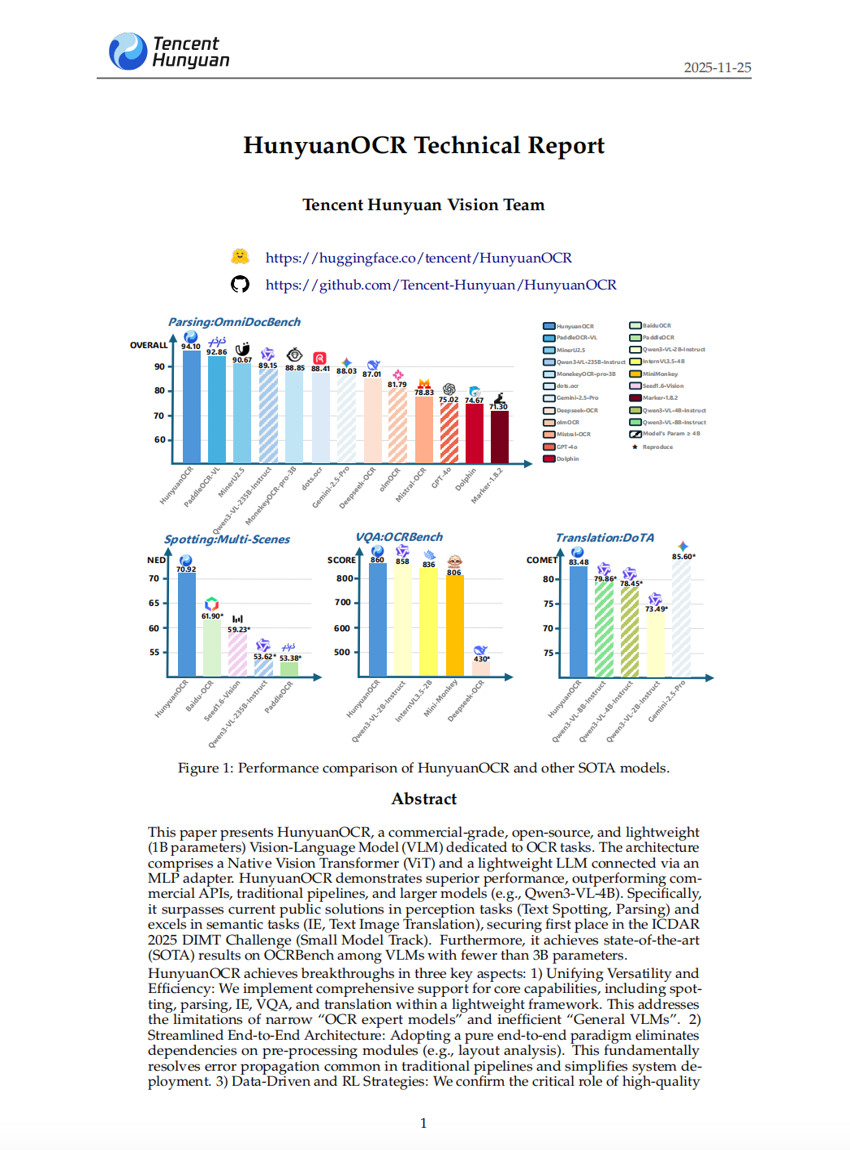
HunyuanOCR Technical Report
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Evolution Strategies at the Hyperscale
Does Understanding Inform Generation in Unified Multimodal Models? From Analysis to Path Forward
iMontage: Unified, Versatile, Highly Dynamic Many-to-many Image Generation
Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning
MedSAM3: Delving into Segment Anything with Medical Concepts
SteadyDancer: Harmonized and Coherent Human Image Animation with First-Frame Preservation
GigaEvo: An Open Source Optimization Framework Powered By LLMs And Evolution Algorithms
Fidelity-Aware Recommendation Explanations via Stochastic Path Integration
Extracting Interaction-Aware Monosemantic Concepts in Recommender Systems
MSRNet: A Multi-Scale Recursive Network for Camouflaged Object Detection
Budget-Aware Tool-Use Enables Effective Agent Scaling
In-Video Instructions: Visual Signals as Generative Control
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
AICC: Parse HTML Finer, Make Models Better -- A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser
UltraFlux: Data-Model Co-Design for High-quality Native 4K Text-to-Image Generation across Diverse Aspect Ratios
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Computer-Use Agents as Judges for Generative User Interface
AutoEnv: Automated Environments for Measuring Cross-Environment Agent Learning
General Agentic Memory Via Deep Research
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
MIST: Mutual Information Via Supervised Training
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Flow Map Distillation Without Data
Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
HunyuanOCR Technical Report