HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

CharacterShot: Controllable and Consistent 4D Character Animation
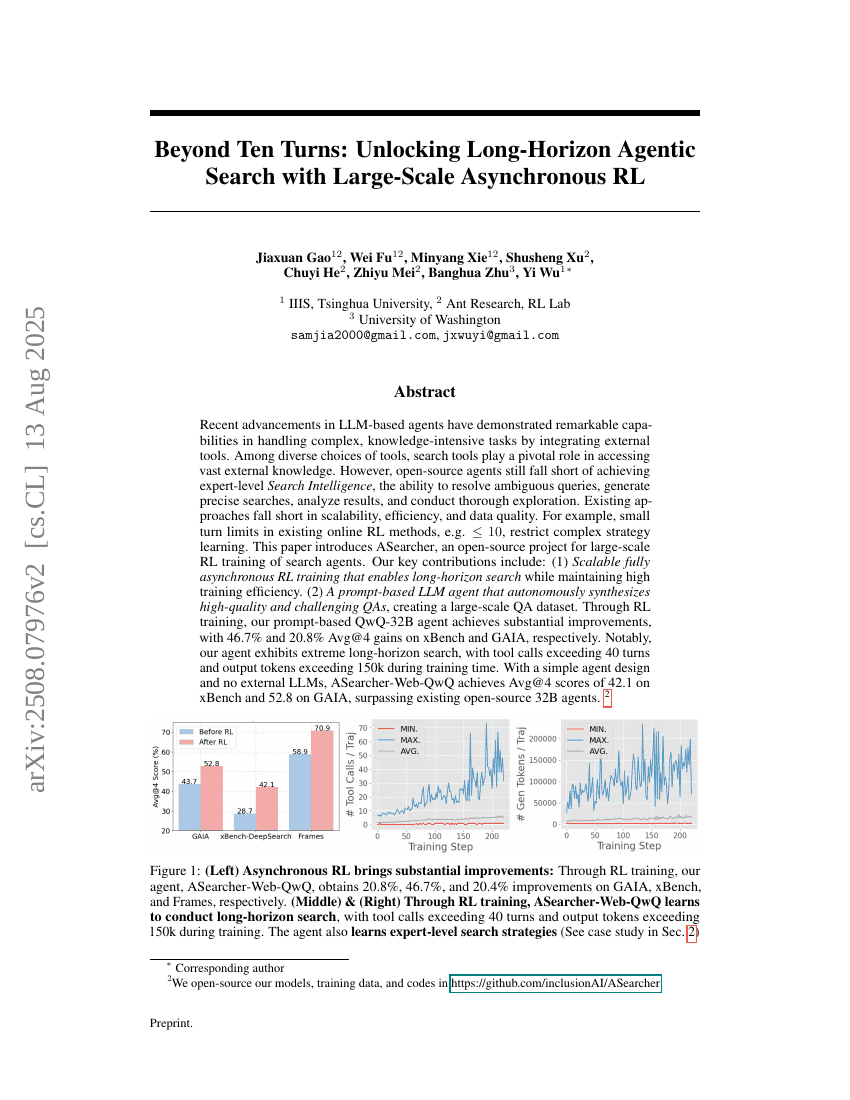
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL



























CharacterShot: Controllable and Consistent 4D Character Animation
Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL
Matrix-3D: Omnidirectional Explorable 3D World Generation
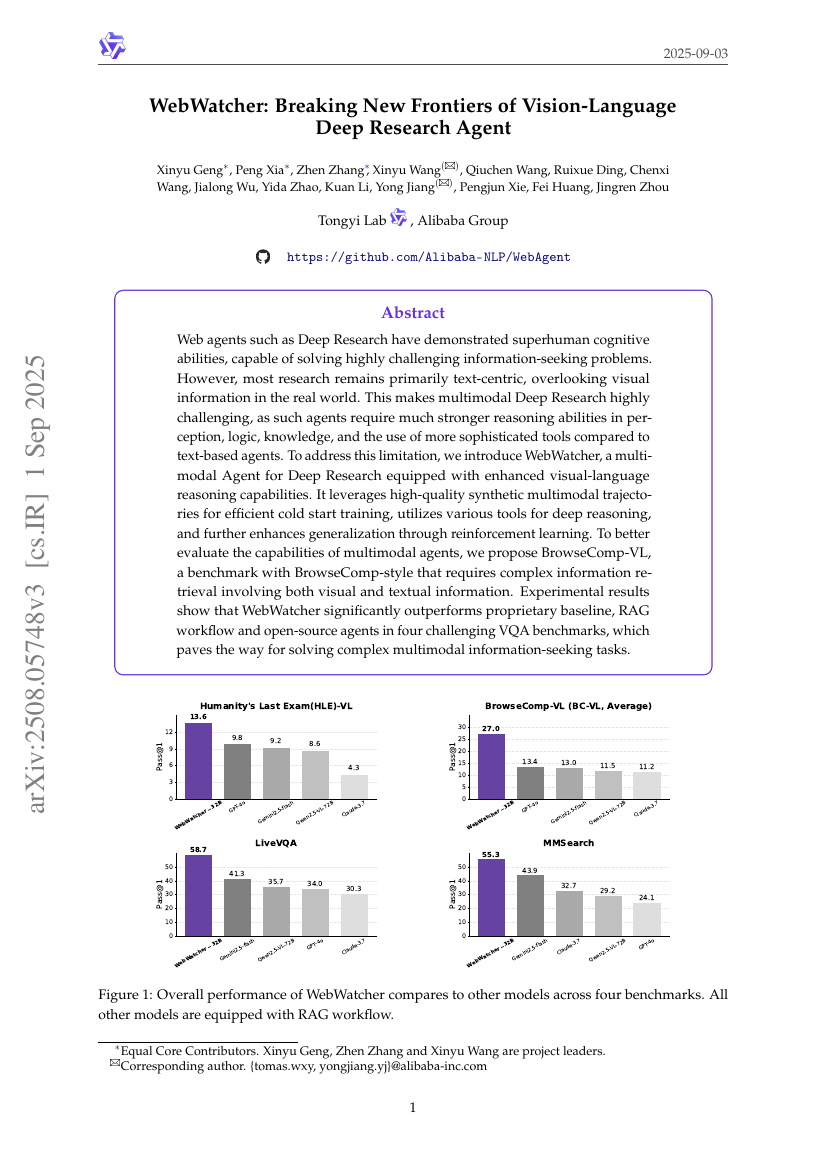
WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent
Marco-Voice Technical Report
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
PyVeritas: On Verifying Python via LLM-Based Transpilation and Bounded Model Checking for C
Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory
Design of highly functional genome editors by modelling CRISPR–Cas sequences
UserBench: An Interactive Gym Environment for User-Centric Agents
SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens
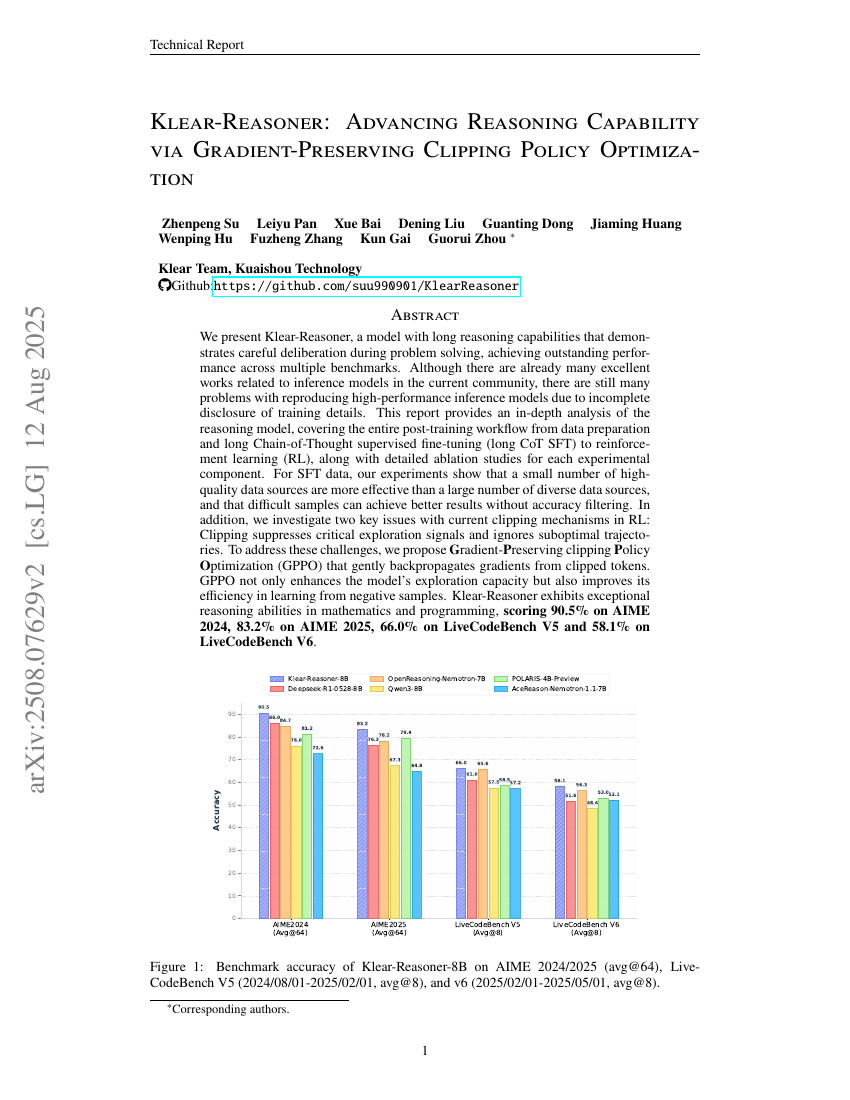
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
WideSearch: Benchmarking Agentic Broad Info-Seeking
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Mediator-Guided Multi-Agent Collaboration among Open-Source Models for Medical Decision-Making
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
GENIE: Gaussian Encoding for Neural Radiance Fields Interactive Editing
Pruning the Unsurprising: Efficient Code Reasoning via First-Token Surprisal
Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off
InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
Memp: Exploring Agent Procedural Memory
Perch 2.0: The Bittern Lesson for Bioacoustics
Are We on the Right Way for Assessing Document Retrieval-Augmented Generation?
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
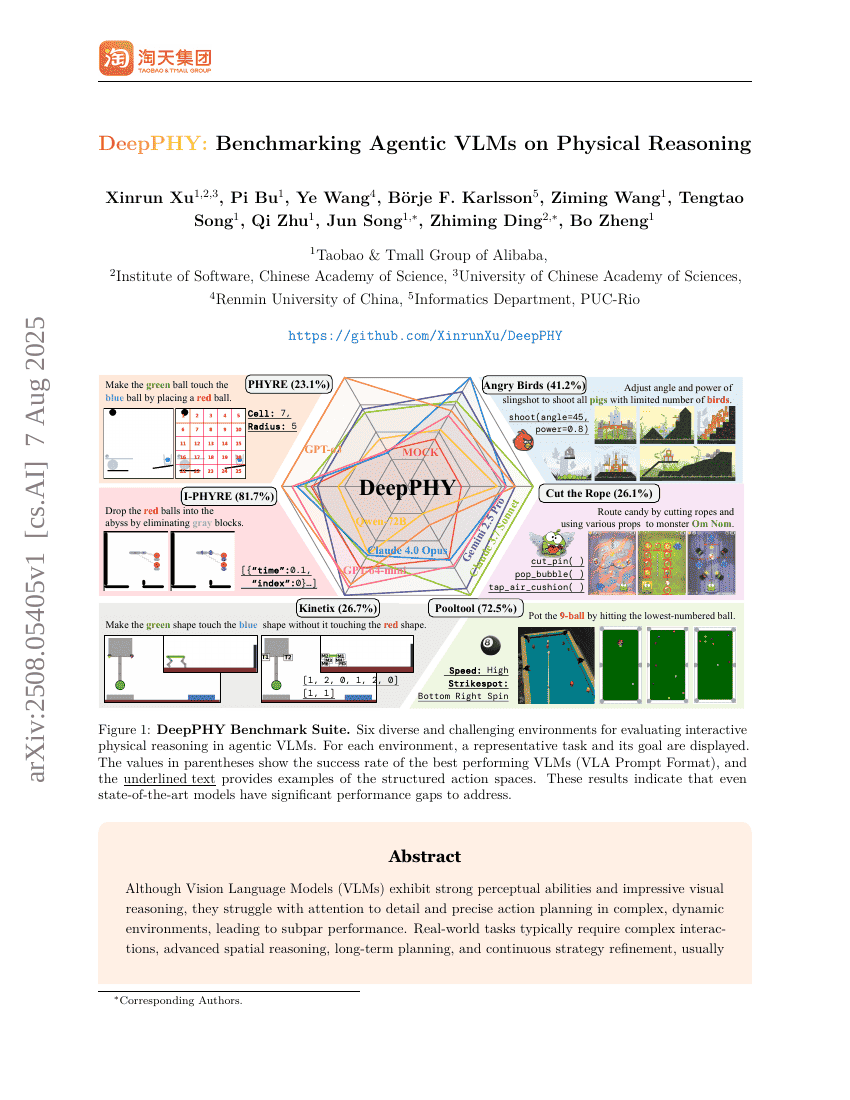
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
R-Zero: Self-Evolving Reasoning LLM from Zero Data
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Matrix-3D: Omnidirectional Explorable 3D World Generation
WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent
Marco-Voice Technical Report
Kimina-Prover Preview: Towards Large Formal Reasoning Models with Reinforcement Learning
PyVeritas: On Verifying Python via LLM-Based Transpilation and Bounded Model Checking for C
Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory
Design of highly functional genome editors by modelling CRISPR–Cas sequences
UserBench: An Interactive Gym Environment for User-Centric Agents
SONAR-LLM: Autoregressive Transformer that Thinks in Sentence Embeddings and Speaks in Tokens
Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
WideSearch: Benchmarking Agentic Broad Info-Seeking
ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Mediator-Guided Multi-Agent Collaboration among Open-Source Models for Medical Decision-Making
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
GENIE: Gaussian Encoding for Neural Radiance Fields Interactive Editing
Pruning the Unsurprising: Efficient Code Reasoning via First-Token Surprisal
Voost: A Unified and Scalable Diffusion Transformer for Bidirectional Virtual Try-On and Try-Off
InfiGUI-G1: Advancing GUI Grounding with Adaptive Exploration Policy Optimization
Memp: Exploring Agent Procedural Memory
Perch 2.0: The Bittern Lesson for Bioacoustics
Are We on the Right Way for Assessing Document Retrieval-Augmented Generation?
Hi3DEval: Advancing 3D Generation Evaluation with Hierarchical Validity
DeepPHY: Benchmarking Agentic VLMs on Physical Reasoning
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
R-Zero: Self-Evolving Reasoning LLM from Zero Data
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification
Simulating Human-Like Learning Dynamics with LLM-Empowered Agents
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning