Command Palette
Search for a command to run...
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
FunCineForge: A Unified Dataset Toolkit and Model for Zero-Shot Movie Dubbing in Diverse Cinematic Scenes
Jiaxuan Liu Yang Xiang Han Zhao Xiangang Li Zhenhua Ling
Abstract
Movie dubbing is the task of synthesizing speech from scripts conditioned on video scenes, requiring accurate lip sync, faithful timbre transfer, and proper modeling of character identity and emotion. However, existing methods face two major limitations: (1) high-quality multimodal dubbing datasets are limited in scale, suffer from high word error rates, contain sparse annotations, rely on costly manual labeling, and are restricted to monologue scenes, all of which hinder effective model training; (2) existing dubbing models rely solely on the lip region to learn audio-visual alignment, which limits their applicability to complex live-action cinematic scenes, and exhibit suboptimal performance in lip sync, speech quality, and emotional expressiveness. To address these issues, we propose FunCineForge, which comprises an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed for diverse cinematic scenes. Using the pipeline, we construct the first Chinese television dubbing dataset with rich annotations, and demonstrate the high quality of these data. Experiments across monologue, narration, dialogue, and multi-speaker scenes show that our dubbing model consistently outperforms SOTA methods in audio quality, lip sync, timbre transfer, and instruction following.
One-sentence Summary
To address the limitations of existing movie dubbing methods, the authors propose FunCineForge, a unified toolkit and MLLM-based model for zero-shot dubbing in diverse cinematic scenes that utilizes a newly constructed, richly annotated large-scale Chinese television dubbing dataset to outperform state-of-the-art methods in audio quality, lip sync, timbre transfer, and instruction following across monologue, narration, dialogue, and multi-speaker scenarios.
Key Contributions
- The paper introduces FunCineForge, an end-to-end production pipeline designed to generate large-scale, high-quality dubbing datasets from cinematic content. This pipeline utilizes Multimodal CoT Correction to improve data quality and produces the first Chinese television dubbing dataset featuring rich annotations.
- A novel MLLM-based dubbing model is presented to handle diverse cinematic scenes by employing a frame-index codebook and dedicated MLLM supervision for precise audio-visual alignment. This approach moves beyond simple lip-region reliance to better manage complex live-action environments.
- The research implements an improved flow-matching design that enables flexible speaker switching and supports multi-speaker interactions. Experimental results demonstrate that this model outperforms state-of-the-art methods in audio quality, lip sync, timbre transfer, and instruction following across monologue, narration, dialogue, and multi-speaker scenarios.
Introduction
Movie dubbing requires synthesizing speech that maintains accurate lip synchronization, faithful timbre transfer, and appropriate emotional expression within cinematic contexts. Current methods are limited by small scale datasets that rely on costly manual labeling and are often restricted to simple monologue scenes. Furthermore, existing models typically focus only on the lip region for audio-visual alignment, which leads to poor performance in complex, multi-speaker, or highly expressive cinematic environments. The authors propose FunCineForge, which introduces an end-to-end production pipeline for generating large-scale, richly annotated dubbing datasets and an MLLM-based dubbing model. This approach enables high-quality zero-shot dubbing across diverse scenarios including dialogue and multi-speaker scenes by leveraging improved multimodal alignment and flexible speaker switching.
Dataset
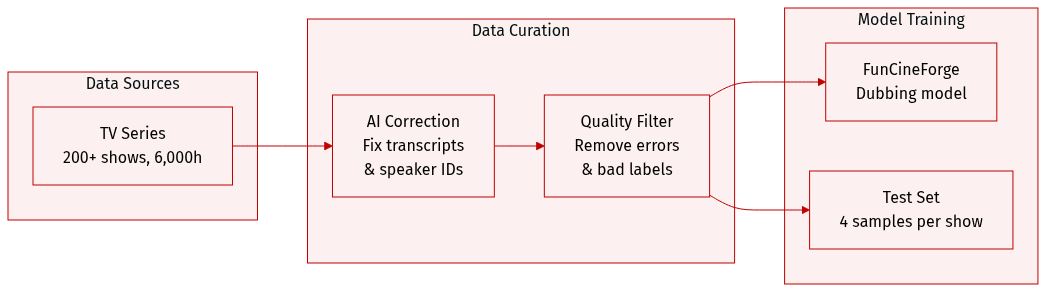
-
Dataset Composition and Sources: The authors constructed the CineDub-CN dataset using over 200 raw Chinese television series, totaling more than 6,000 hours of footage. The selection process focused on non-documentary content with standard pronunciation, clear vocal tracks, minimal colloquialisms, and unobstructed faces.
-
Dataset Scale and Subsets: The final dataset consists of 1,559,172 samples totaling 7.2 TB, providing over 4,700 hours of effective speech with an average clip length of 11.02 seconds. The data is categorized into four scene types: monologue, narration, dialogue, and multi-speaker scenes. For evaluation, the authors constructed a test set by selecting four samples from each television series, ensuring representation across all four scene categories.
-
Data Processing and MLLM Correction: To address errors in ASR transcripts and speaker diarization, the authors implemented a Multimodal CoT (Chain of Thought) correction pipeline using Gemini-2.5-Pro. This process involves:
- Correcting lexical and punctuation errors in ASR transcripts.
- Refining speaker diarization to identify the true number of speakers and their temporal intervals.
- Generating paralinguistic metadata, including character gender, age group, timbre traits, and emotional tone.
- Using a bidirectional verification mechanism between the MLLM and lightweight specialized models to prevent hallucinations.
- Normalizing outputs through front-end processing, such as numeric normalization and Chinese character conversion.
-
Filtering and Quality Control: The pipeline applies strict discarding rules to ensure high data quality. Samples are removed if the Levenshtein distance between the MLLM-corrected transcript and the original ASR transcript exceeds 50%. Additionally, samples with inconsistent speaker identities between the MLLM and specialized models are discarded, while unreliable gender or age labels are replaced with an "Unknown" tag.
-
Usage in Training: The processed CineDub-CN dataset is used to train the FunCineForge dubbing model. The authors demonstrate that training on this large-scale, corrected dataset significantly outperforms models trained on smaller datasets like V2C-Animation, Chem, or GRID, specifically improving pronunciation quality, lip sync accuracy, and speech naturalness.
Method
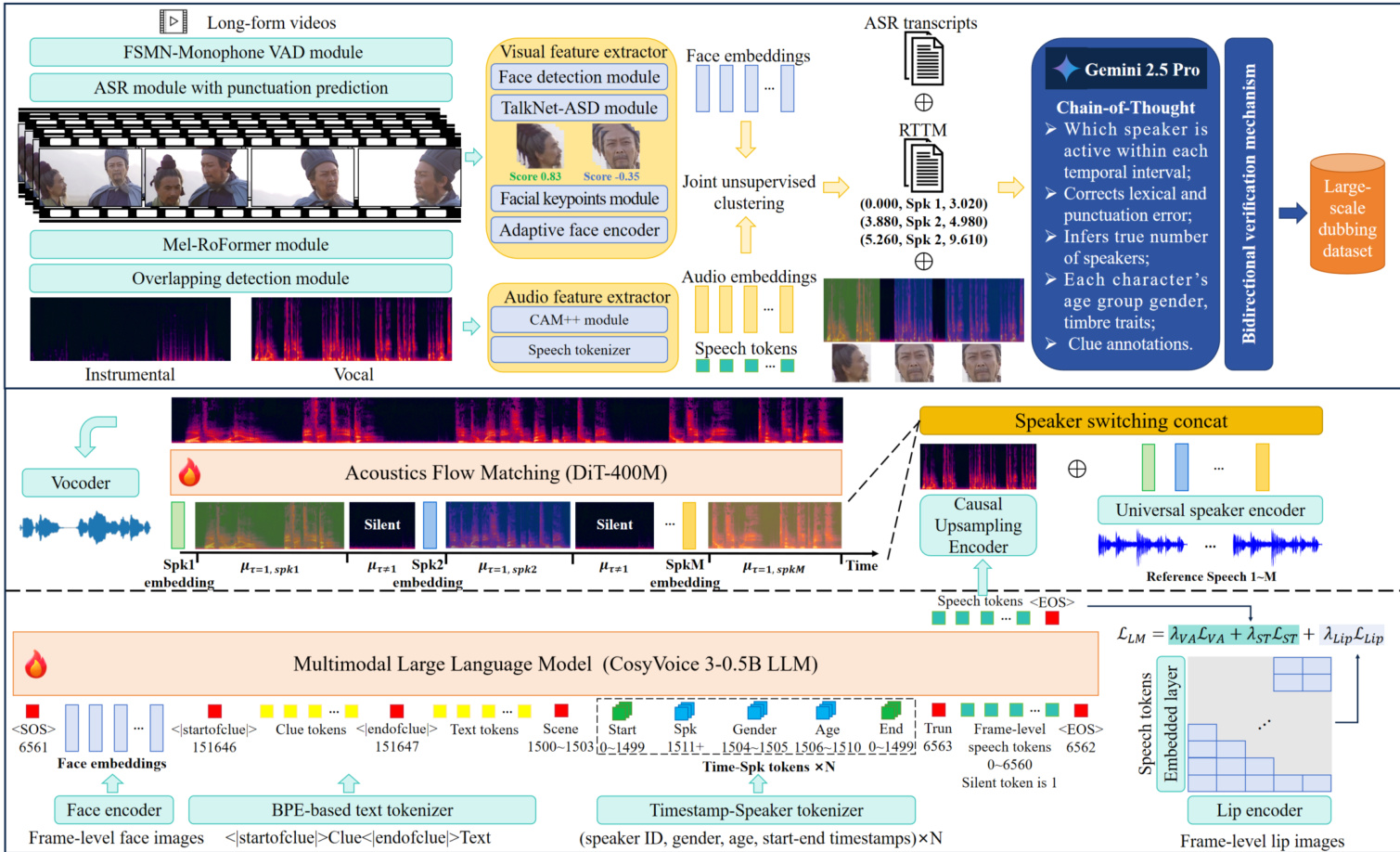
The authors propose FunCineForge, a system consisting of an end-to-end production pipeline for large-scale dubbing datasets and an MLLM-based dubbing model designed to handle diverse cinematic scenes. The dataset pipeline is designed to automatically transform raw film and television sources into structured multimodal data. This process involves several specialized modules: an FSMN-Monophone VAD module for speech-active segment extraction, an ASR module for transcription, and a Mel-RoFormer module for vocal and instrumental separation. To ensure robust speaker identification, the pipeline utilizes a visually enhanced speaker diarization framework that combines audio embeddings from a CAM++ module with visual face embeddings.
As shown in the framework diagram:
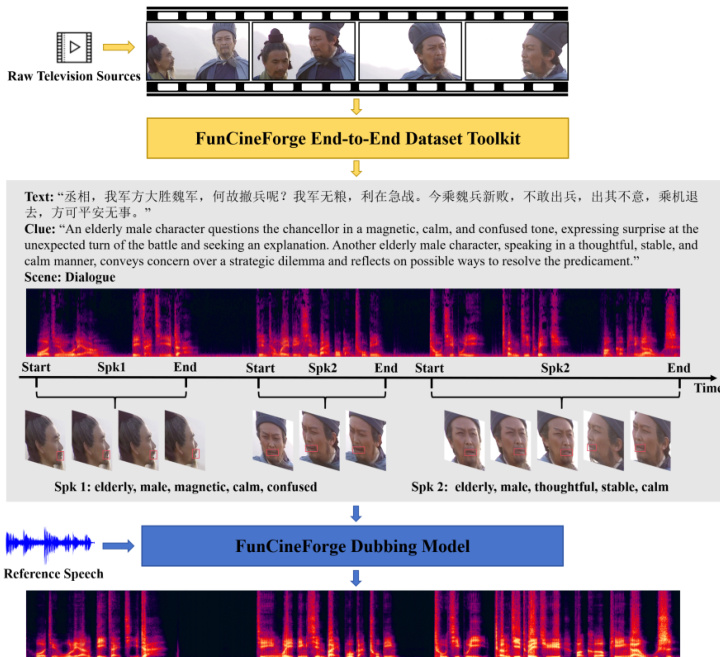
The dubbing model architecture is designed to synthesize Mel-spectrograms by integrating multiple modalities. Given facial frame sequences Face, a dubbing script Text, clue instructions Clue, a scene category Scene, a set of timestamp-speaker tuples TN, and reference speech samples refM, the model performs the following mapping: Y^=Model(Face,Text,Clue,Scene,TN,refM)
The training process is divided into two primary stages: MLLM training and flow matching training. In the MLLM stage, the model employs a multimodal alignment mechanism. The text and clues are tokenized into XText, while face and lip images are encoded into sparse facial and lip representations, EFaceT and ELipT. To address the complexities of cinematic scenes, the authors introduce a Timestamp-Speaker tokenizer (TST) that maps temporal and speaker attributes into a discrete sequence XTS. This provides strong supervision for temporal alignment. The model is optimized using a combination of losses: a voice activity loss LVA to model speech occurrence, a speech token loss LST to capture content, and a contrastive lip loss LLip to achieve fine-grained lip-speech alignment.
The second stage involves a flow matching module built upon a Diffusion Transformer (DiT) backbone. To support speaker switching in multi-speaker scenes, the authors implement a speaker switching concatenation strategy. For each timestamp segment, the corresponding speaker embedding ESpk from the reference set is inserted immediately after the last silent token. This allows the model to explicitly align speaker identity with temporal boundaries.
Refer to the architecture diagram:
Experiment
The evaluation compares the proposed FunCineForge model against state-of-the-art baselines and instruction-driven methods using both monologue and complex cinematic scenes. Results demonstrate that the model consistently outperforms existing methods in speech naturalness, pronunciation accuracy, and audio-visual alignment across diverse datasets. Ablation studies further validate that explicit temporal speaker supervision, lip contrastive loss, and specialized speaker switching strategies are essential for maintaining fine-grained lip sync and preventing speaker leakage in multi-speaker dialogues.
The authors conduct ablation studies on the CineDub-Forge model across various scene types including monologue, narration, dialogue, and multi-speaker scenarios. The results demonstrate that the inclusion of timestamp-speaker tuples and the lip contrastive loss significantly improves temporal alignment and lip synchronization accuracy. Removing timestamp-speaker tuples leads to a substantial increase in speaker truncation and leakage metrics, particularly in dialogue and multi-speaker scenes. The absence of the lip contrastive loss results in decreased lip sync confidence and increased lip sync error distance. Removing the speaker switching concatenation strategy causes a significant drop in speaker similarity within dialogue and multi-speaker contexts.
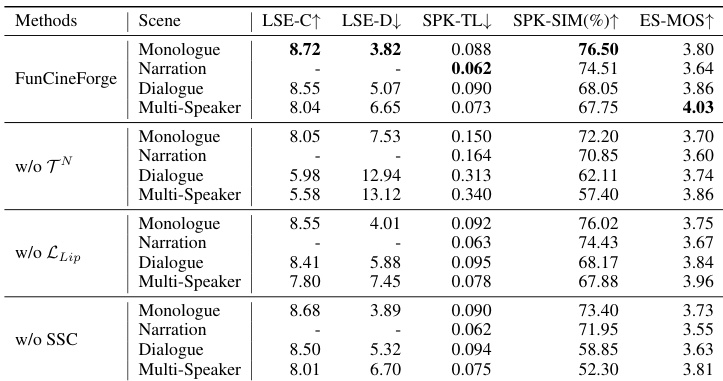
The authors perform ablation studies on the CineDub-Forge model across diverse scene types, including monologues, narrations, and multi-speaker dialogues, to validate the effectiveness of its core components. The results indicate that timestamp-speaker tuples and lip contrastive loss are essential for maintaining precise temporal alignment and lip synchronization. Furthermore, the speaker switching concatenation strategy is shown to be critical for preserving speaker identity and preventing leakage in complex conversational scenarios.