HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
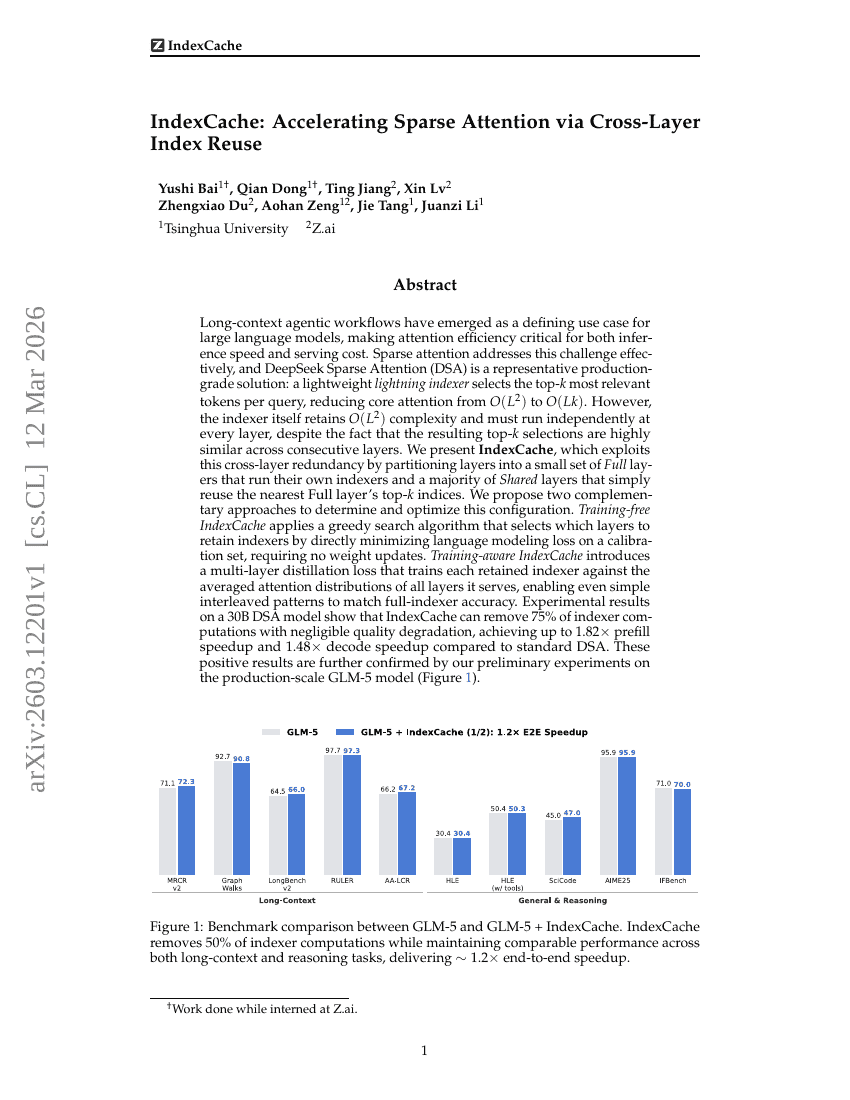
IndexCache:通过跨层索引复用加速稀疏注意力机制

战略导航还是随机搜索?Agent 与人类如何在文档集合中进行推理
















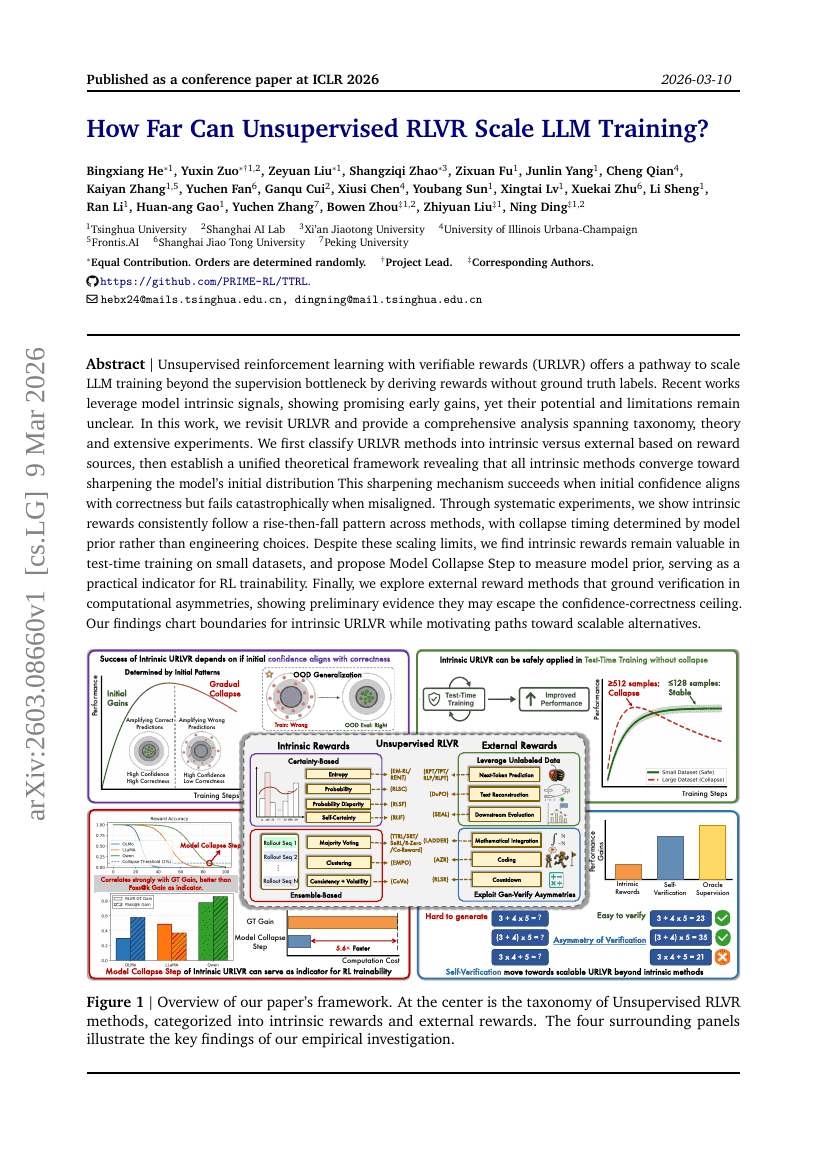













IndexCache:通过跨层索引复用加速稀疏注意力机制
战略导航还是随机搜索?Agent 与人类如何在文档集合中进行推理
Spatial-TTT:基于流式视觉的测试时训练空间智能
大型语言模型能否跟上节奏?面向持续知识流的在线适应性基准测试
ReMix:LLM 微调中 LoRA 混合模型的强化路由机制
大型语言模型中工具使用的上下文强化学习
MA-EgoQA:基于多具身智能体的第一人称视频问答
Flash-KMeans:快速且内存高效的精确 K-Means 算法
OpenClaw-RL:仅需对话即可训练任意 Agent
将视觉语言模型引入赛场:体育领域空间智能基准测试
InternVL-U:推动面向理解、推理、生成与编辑的统一多模态模型普及化
MM-Zero:基于零数据自进化的多模型视觉语言模型
思考以唤起:推理如何解锁 LLM 中的参数化知识
Omni-Diffusion:基于掩蔽离散扩散的统一多模态理解与生成
几何引导的强化学习用于多视角一致的 3D 场景编辑
CARE-Edit:面向上下文图像编辑的条件感知专家路由
相信你的模型:分布引导的置信度校准
LoGeR:基于混合记忆机制的长上下文几何重建
无监督 RLVR 能在多大程度上扩展 LLM 训练?
Holi-Spatial:将视频流演进为整体三维空间智能
迷失于叙事之中:LLMs 长故事生成中的一致性缺陷
DreamCAD:基于可微参数曲面的多模态CAD生成扩展
实时人工智能服务经济:跨连续体的代理计算框架
NOTAI.AI:基于曲率与特征归因的可解释机器生成文本检测
更安全的推理轨迹:衡量与缓解 LLMs 中的 Chain-of-Thought 泄露
RACAS:通过单一 Agent 系统控制多样化机器人
输入有偏,输出亦有偏?在基础模型中探索无偏子网络
ArtLLM: 通过 3D LLM 生成关节化资产
HiFi-Inpaint:面向高保真参考式图像修复以生成细节保留的人 - 物图像
RoboPocket:通过手机即时提升机器人策略
AgentVista:在超具挑战性的真实视觉场景中评估多模态 Agent
DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐
Spatial-TTT:基于流式视觉的测试时训练空间智能
大型语言模型能否跟上节奏?面向持续知识流的在线适应性基准测试
ReMix:LLM 微调中 LoRA 混合模型的强化路由机制
大型语言模型中工具使用的上下文强化学习
MA-EgoQA:基于多具身智能体的第一人称视频问答
Flash-KMeans:快速且内存高效的精确 K-Means 算法
OpenClaw-RL:仅需对话即可训练任意 Agent
将视觉语言模型引入赛场:体育领域空间智能基准测试
InternVL-U:推动面向理解、推理、生成与编辑的统一多模态模型普及化
MM-Zero:基于零数据自进化的多模型视觉语言模型
思考以唤起:推理如何解锁 LLM 中的参数化知识
Omni-Diffusion:基于掩蔽离散扩散的统一多模态理解与生成
几何引导的强化学习用于多视角一致的 3D 场景编辑
CARE-Edit:面向上下文图像编辑的条件感知专家路由
相信你的模型:分布引导的置信度校准
LoGeR:基于混合记忆机制的长上下文几何重建
无监督 RLVR 能在多大程度上扩展 LLM 训练?
Holi-Spatial:将视频流演进为整体三维空间智能
迷失于叙事之中:LLMs 长故事生成中的一致性缺陷
DreamCAD:基于可微参数曲面的多模态CAD生成扩展
实时人工智能服务经济:跨连续体的代理计算框架
NOTAI.AI:基于曲率与特征归因的可解释机器生成文本检测
更安全的推理轨迹:衡量与缓解 LLMs 中的 Chain-of-Thought 泄露
RACAS:通过单一 Agent 系统控制多样化机器人
输入有偏,输出亦有偏?在基础模型中探索无偏子网络
ArtLLM: 通过 3D LLM 生成关节化资产
HiFi-Inpaint:面向高保真参考式图像修复以生成细节保留的人 - 物图像
RoboPocket:通过手机即时提升机器人策略
AgentVista:在超具挑战性的真实视觉场景中评估多模态 Agent
DARE:通过分布感知检索将LLM Agents与R统计生态系统对齐