HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

擦除它!通过机器遗忘在代码语言模型中消除敏感记忆

全景图:具身AI时代全向视觉的崛起






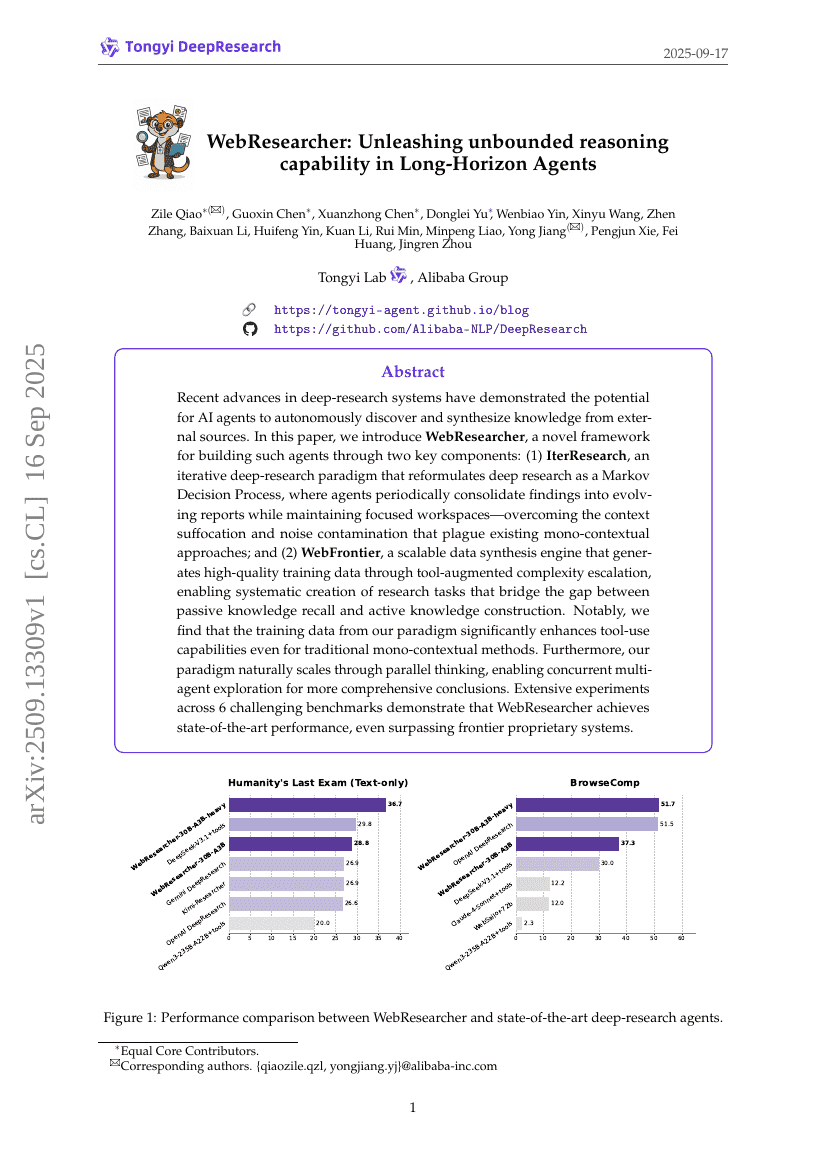





















擦除它!通过机器遗忘在代码语言模型中消除敏感记忆
全景图:具身AI时代全向视觉的崛起
Hala技术报告:大规模构建以阿拉伯语为中心的指令与翻译模型
DeepSeek-R1 通过强化学习激励 LLMs 进行推理
教LLM进行规划:用于符号规划的逻辑思维链指令微调
OpenHA:一系列开源的Minecraft层级化Agent模型
BED-LLM:基于LLM与贝叶斯实验设计的智能信息收集
ReSum:通过上下文摘要解锁长时程搜索智能
WebResearcher:在长时程Agent中释放无边界推理能力
通过环境扩展迈向通用Agent智能
WebSailor-V2:通过合成数据与可扩展强化学习弥合专有Agent的鸿沟
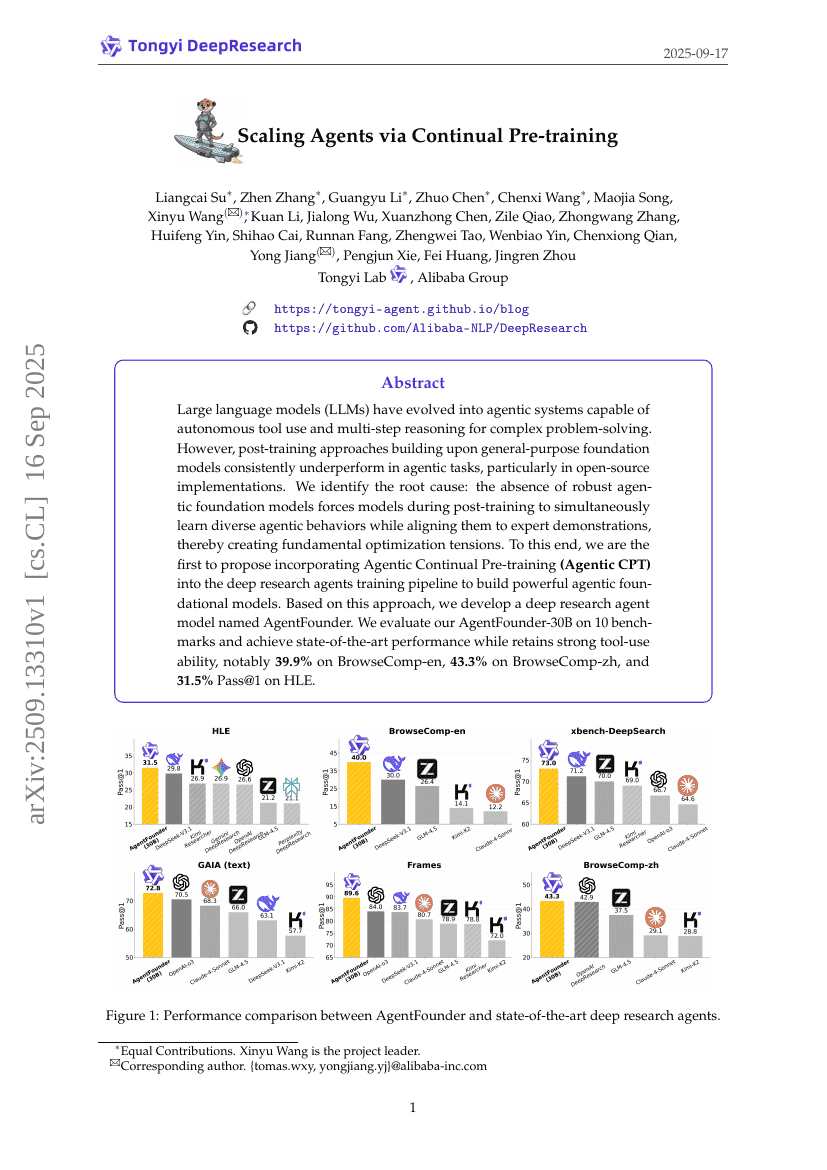
通过持续预训练扩展Agent
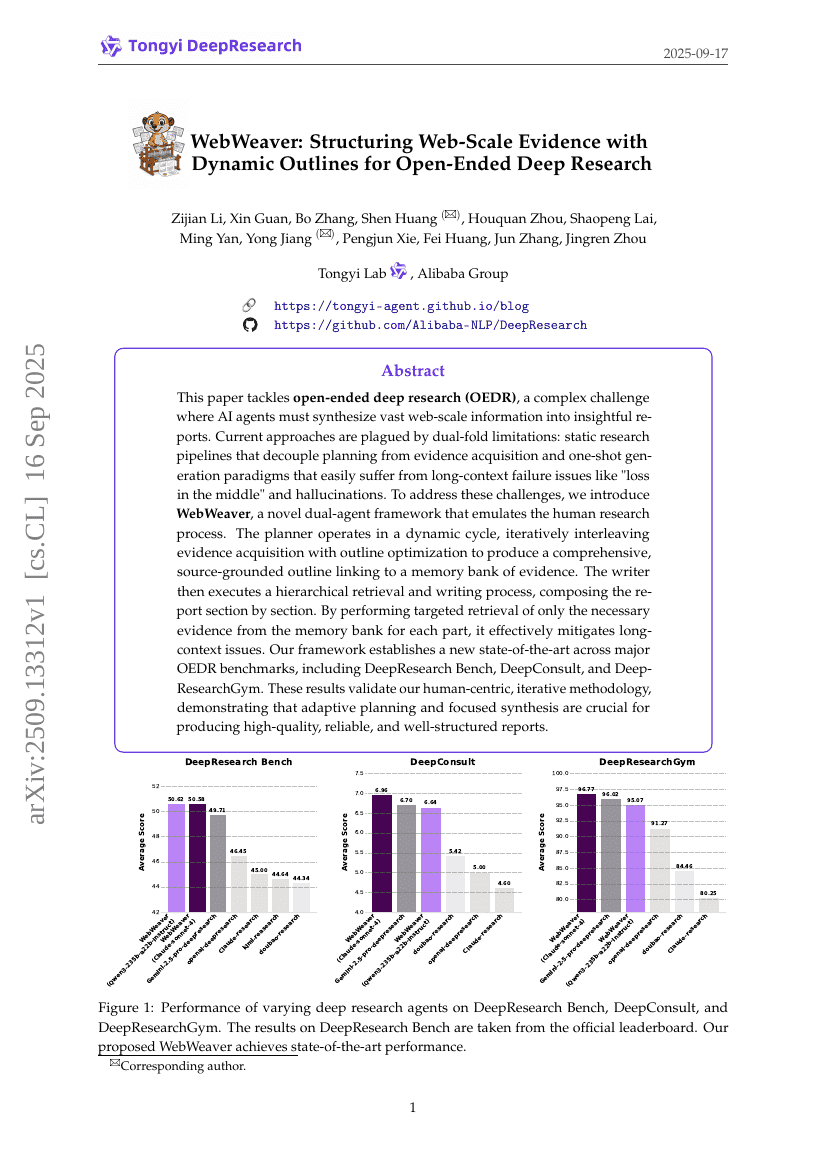
WebWeaver:通过动态大纲构建网络规模证据以支持开放式深度研究
大型语言模型中的Glitch Tokens:分类体系与有效检测
REFRAG:重新思考基于RAG的解码
对齐后引导:通过统一潜在引导适应视觉-语言-动作模型
SubLIME:基于秩相关性预测的子集选择用于数据高效的LLM评估
上下文混合用于长视频生成
MusicSwarm:用于音乐创作的生物启发式智能
LEGO:张量应用的时空加速器生成与优化
LazyDrag:通过显式对应关系实现多模态扩散Transformer上的稳定拖拽编辑
SearchInstruct:通过基于检索的指令数据集构建增强领域自适应
可解释的物理推理与视觉-语言模型的性能分类体系
InternScenes:一个大规模可模拟室内场景数据集,具备真实布局
UI-S1:通过半在线强化学习推进GUI自动化
OmniWorld:用于4D世界建模的多领域多模态数据集
LAVa:基于层级的KV缓存淘汰与动态预算分配
基于概率结构融合的世界建模
VStyle:一个基于口语指令的语音风格适配基准
HANRAG:启发式高精度抗噪声多跳问答增强生成
InfGen:一种与分辨率无关的可扩展图像合成范式
X-Part:高保真且结构一致的形状分解
Hala技术报告:大规模构建以阿拉伯语为中心的指令与翻译模型
DeepSeek-R1 通过强化学习激励 LLMs 进行推理
教LLM进行规划:用于符号规划的逻辑思维链指令微调
OpenHA:一系列开源的Minecraft层级化Agent模型
BED-LLM:基于LLM与贝叶斯实验设计的智能信息收集
ReSum:通过上下文摘要解锁长时程搜索智能
WebResearcher:在长时程Agent中释放无边界推理能力
通过环境扩展迈向通用Agent智能
WebSailor-V2:通过合成数据与可扩展强化学习弥合专有Agent的鸿沟
通过持续预训练扩展Agent
WebWeaver:通过动态大纲构建网络规模证据以支持开放式深度研究
大型语言模型中的Glitch Tokens:分类体系与有效检测
REFRAG:重新思考基于RAG的解码
对齐后引导:通过统一潜在引导适应视觉-语言-动作模型
SubLIME:基于秩相关性预测的子集选择用于数据高效的LLM评估
上下文混合用于长视频生成
MusicSwarm:用于音乐创作的生物启发式智能
LEGO:张量应用的时空加速器生成与优化
LazyDrag:通过显式对应关系实现多模态扩散Transformer上的稳定拖拽编辑
SearchInstruct:通过基于检索的指令数据集构建增强领域自适应
可解释的物理推理与视觉-语言模型的性能分类体系
InternScenes:一个大规模可模拟室内场景数据集,具备真实布局
UI-S1:通过半在线强化学习推进GUI自动化
OmniWorld:用于4D世界建模的多领域多模态数据集
LAVa:基于层级的KV缓存淘汰与动态预算分配
基于概率结构融合的世界建模
VStyle:一个基于口语指令的语音风格适配基准
HANRAG:启发式高精度抗噪声多跳问答增强生成
InfGen:一种与分辨率无关的可扩展图像合成范式
X-Part:高保真且结构一致的形状分解