HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

LMEnt:一种从预训练数据到表征分析语言模型知识的工具套件

开放数据合成用于深度研究




























LMEnt:一种从预训练数据到表征分析语言模型知识的工具套件
开放数据合成用于深度研究
Robix:一种用于机器人交互、推理与规划的统一模型
对语言模型进行红队测试以减少危害:方法、扩展行为与经验教训
FusionProt:融合序列与结构信息的统一蛋白质表示学习
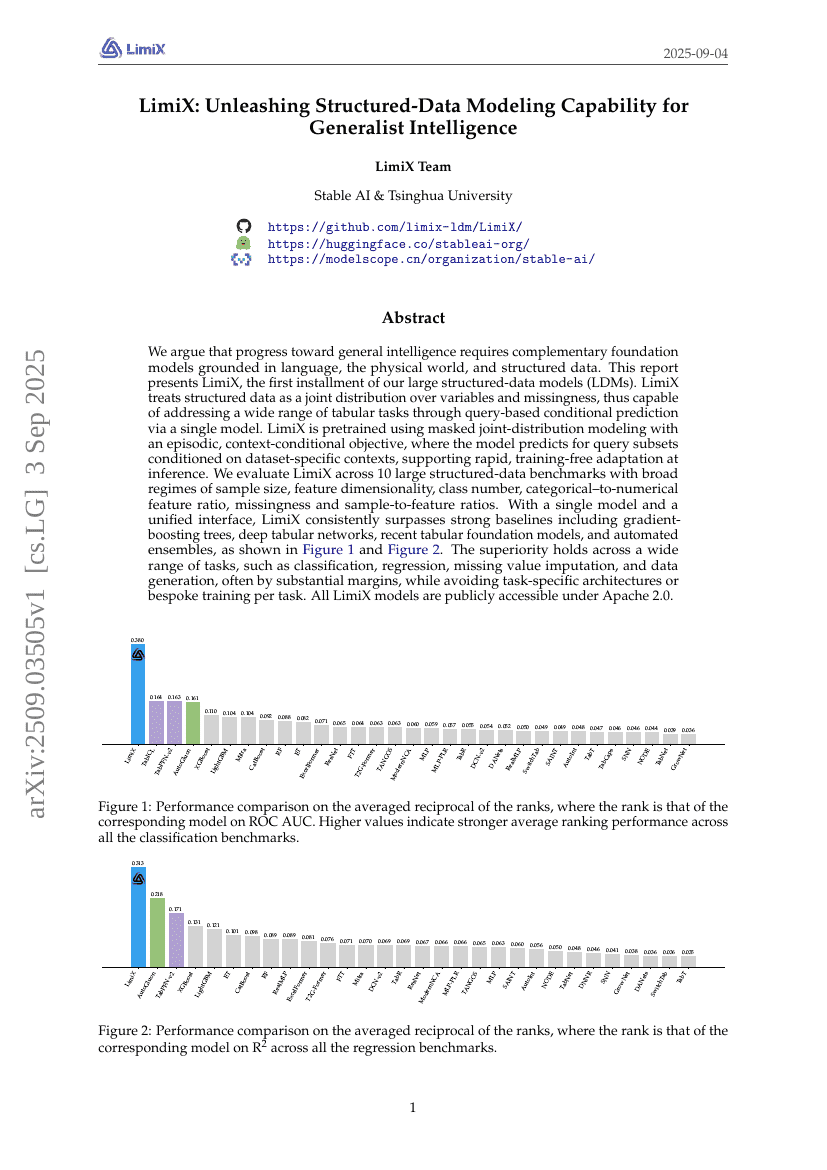
LimiX:释放通用智能的结构化数据建模能力
epiGPTope:一种基于机器学习的表位生成与分类工具
GenCompositor:基于扩散Transformer的生成式视频合成
DCPO:动态裁剪策略优化
推理向量:通过任务算术转移思维链能力
Baichuan-M2:基于大型验证系统扩展医学能力
VerlTool:面向具工具使用的整体性智能体强化学习
ELV-Halluc:长视频理解中语义聚合幻觉的基准测试
MedChatZH:一个更优的医疗顾问通过更优的指令学习
AlphaEarth Foundations:一种基于嵌入场的模型,用于从稀疏标签数据中实现精确且高效的全球制图
AetherCode:评估LLMs在顶级编程竞赛中获胜的能力
TileLang:一种面向AI系统的可组合分块编程模型
DeepSeek-R1 思维学:让我们探讨 LLM 推理
基于双轴传播的多本体集成用于医学概念表示
使用协作式多Agent LLM架构从SOAP病历中自动检测临床问题
SmolDocling:一种超紧凑的视觉-语言模型,用于端到端多模态文档转换
VA-MoE:面向增量天气预报的变量自适应专家混合模型
华佗GPT-Vision,面向大规模注入医学视觉知识到多模态LLM
输入重构如何提升复杂动态环境中工具使用准确性?基于τ-bench 的研究
ALLaM 34B 的 UI 级评估:通过 HUMAIN Chat 测量以阿拉伯语为中心的 LLM
从反应式到认知式:面向具身Agent的类脑空间智能
无标签遗漏:适用于所有监督模式的统一表面缺陷检测模型
T2R-bench:一个从真实工业表格生成文章级报告的基准测试
PVPO:面向智能体推理的预估价值策略优化
UQ:在未解问题上评估语言模型
CARJAN:基于Agent的交通场景生成与仿真方法——AJAN
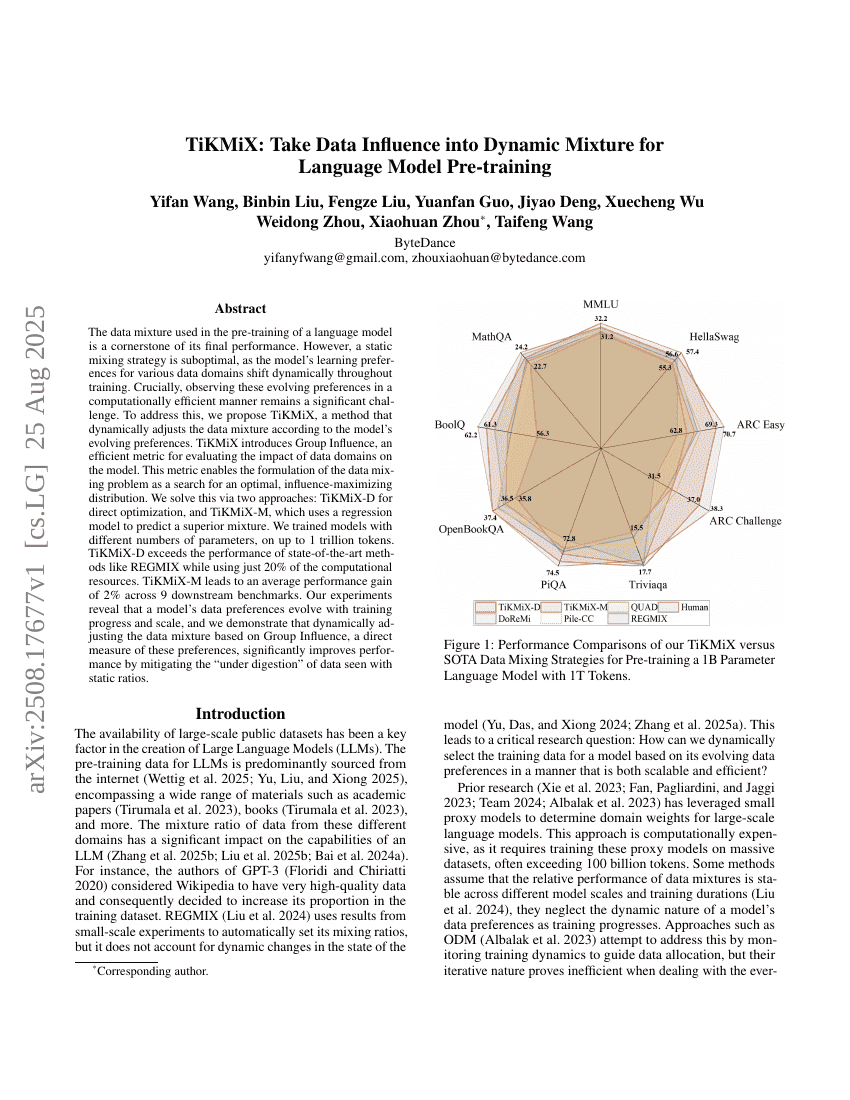
TiKMiX:在语言模型预训练中引入数据影响的动态混合机制
Robix:一种用于机器人交互、推理与规划的统一模型
对语言模型进行红队测试以减少危害:方法、扩展行为与经验教训
FusionProt:融合序列与结构信息的统一蛋白质表示学习
LimiX:释放通用智能的结构化数据建模能力
epiGPTope:一种基于机器学习的表位生成与分类工具
GenCompositor:基于扩散Transformer的生成式视频合成
DCPO:动态裁剪策略优化
推理向量:通过任务算术转移思维链能力
Baichuan-M2:基于大型验证系统扩展医学能力
VerlTool:面向具工具使用的整体性智能体强化学习
ELV-Halluc:长视频理解中语义聚合幻觉的基准测试
MedChatZH:一个更优的医疗顾问通过更优的指令学习
AlphaEarth Foundations:一种基于嵌入场的模型,用于从稀疏标签数据中实现精确且高效的全球制图
AetherCode:评估LLMs在顶级编程竞赛中获胜的能力
TileLang:一种面向AI系统的可组合分块编程模型
DeepSeek-R1 思维学:让我们探讨 LLM 推理
基于双轴传播的多本体集成用于医学概念表示
使用协作式多Agent LLM架构从SOAP病历中自动检测临床问题
SmolDocling:一种超紧凑的视觉-语言模型,用于端到端多模态文档转换
VA-MoE:面向增量天气预报的变量自适应专家混合模型
华佗GPT-Vision,面向大规模注入医学视觉知识到多模态LLM
输入重构如何提升复杂动态环境中工具使用准确性?基于τ-bench 的研究
ALLaM 34B 的 UI 级评估:通过 HUMAIN Chat 测量以阿拉伯语为中心的 LLM
从反应式到认知式:面向具身Agent的类脑空间智能
无标签遗漏:适用于所有监督模式的统一表面缺陷检测模型
T2R-bench:一个从真实工业表格生成文章级报告的基准测试
PVPO:面向智能体推理的预估价值策略优化
UQ:在未解问题上评估语言模型
CARJAN:基于Agent的交通场景生成与仿真方法——AJAN
TiKMiX:在语言模型预训练中引入数据影响的动态混合机制