HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

TalkVid:一个大规模多样化音频驱动说话头合成数据集

Droplet3D:来自视频的常识先验促进3D生成


























TalkVid:一个大规模多样化音频驱动说话头合成数据集
Droplet3D:来自视频的常识先验促进3D生成
A.S.E:面向AI生成代码安全性的仓库级基准测试
EmbodiedOneVision:面向通用机器人控制的交织视觉-文本-动作预训练
R-4B:通过双模式退火与强化学习激励多模态大模型的通用自动思考能力
激发小规模语言模型的创意写作:基于LLM的评判与多智能体精炼奖励
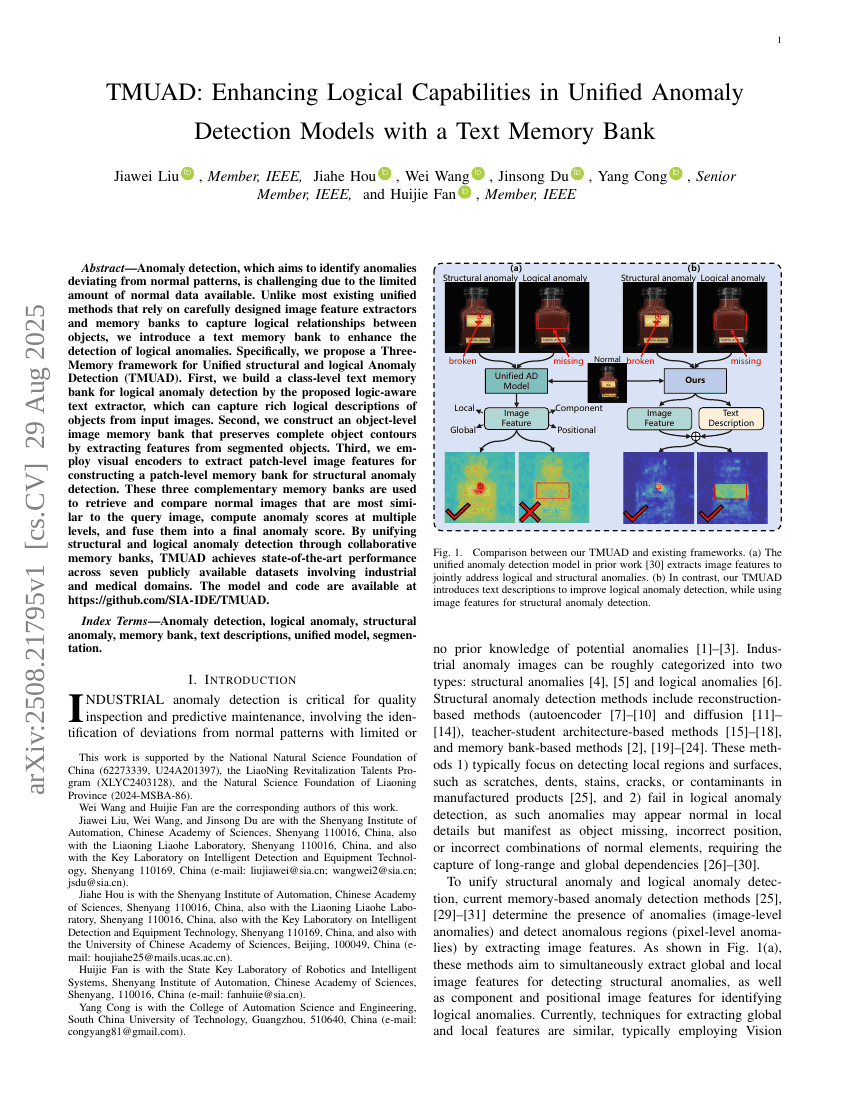
TMUAD:通过文本记忆库增强统一异常检测模型的逻辑能力
思维链动态分析:主动引导还是不忠实的事后合理化?
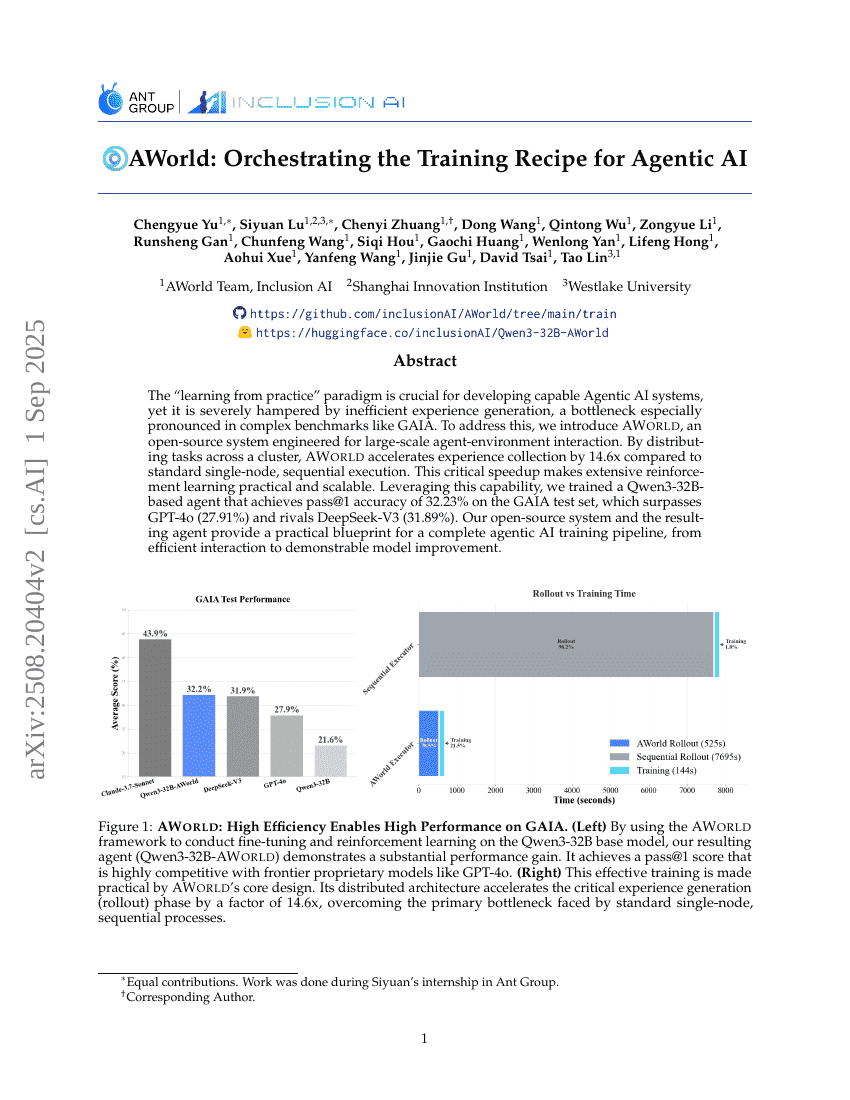
AWorld:面向智能体AI训练配方的编排
MCP-Bench:通过MCP服务器对复杂现实世界任务中使用工具的LLM Agent进行基准测试
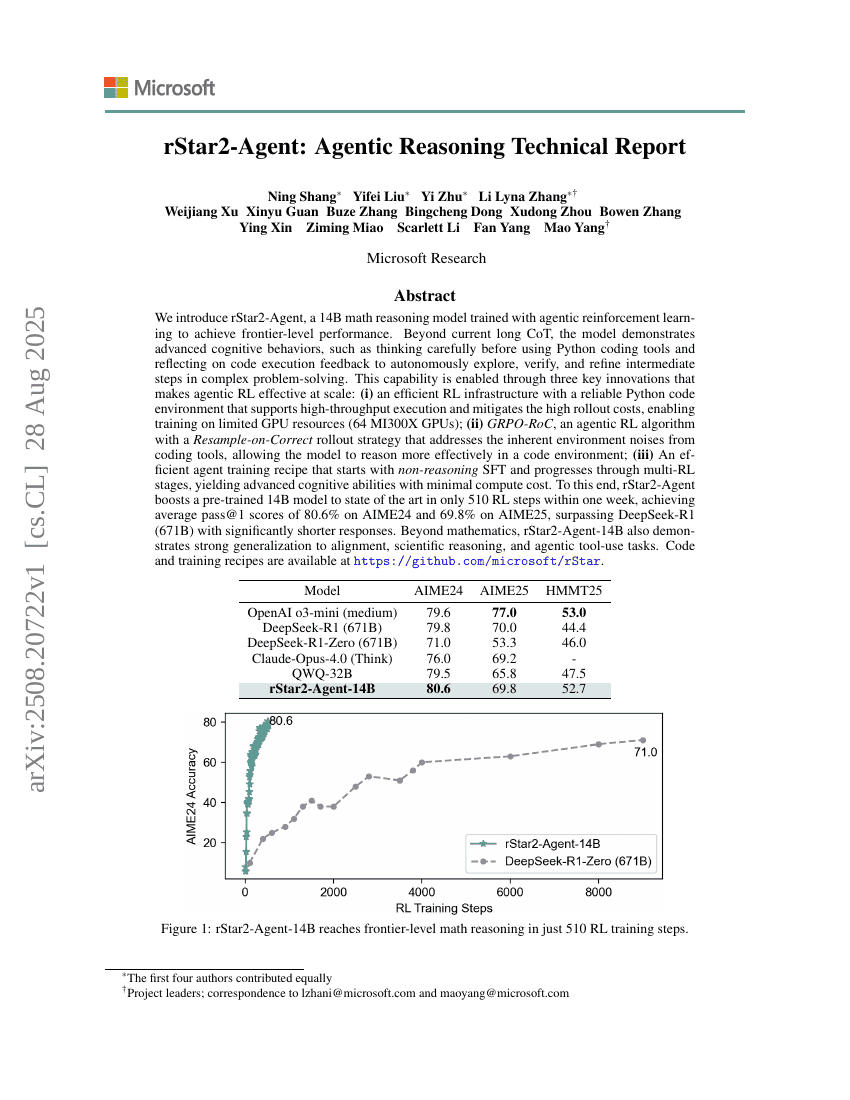
rStar2-Agent:代理式推理技术报告
Pref-GRPO:基于成对偏好奖励的GRPO用于稳定文本到图像强化学习
MobileCLIP2:提升多模态强化训练
AI-AI 审美协作:显式符号学意识与涌现语法发展
凝视心灵:用于rPPG与健康生物标志物估计的多视角视频数据集
预测下一个标记的顺序可提升语言建模性能
MIDAS:通过实时自回归视频生成实现的多模态交互式数字人合成
离散扩散VLA:将离散扩散引入视觉-语言-动作策略中的动作解码
通过推理分解的自奖励视觉-语言模型
超越转录:自动语音识别中的机制可解释性
CODA:面向解耦强化学习的双脑计算机使用Agent中大脑与小脑的协同机制
WebSight:一种面向视觉的鲁棒网络智能体架构
UltraMemV2:面向120B参数的内存网络,具备卓越的长上下文学习能力
Hermes 4 技术报告
OmniHuman-1.5:通过认知模拟为虚拟化身注入主动思维
VoxHammer:无需训练的原生3D空间中精确且连贯的3D编辑
CMPhysBench:用于评估大语言模型在凝聚态物理领域性能的基准测试
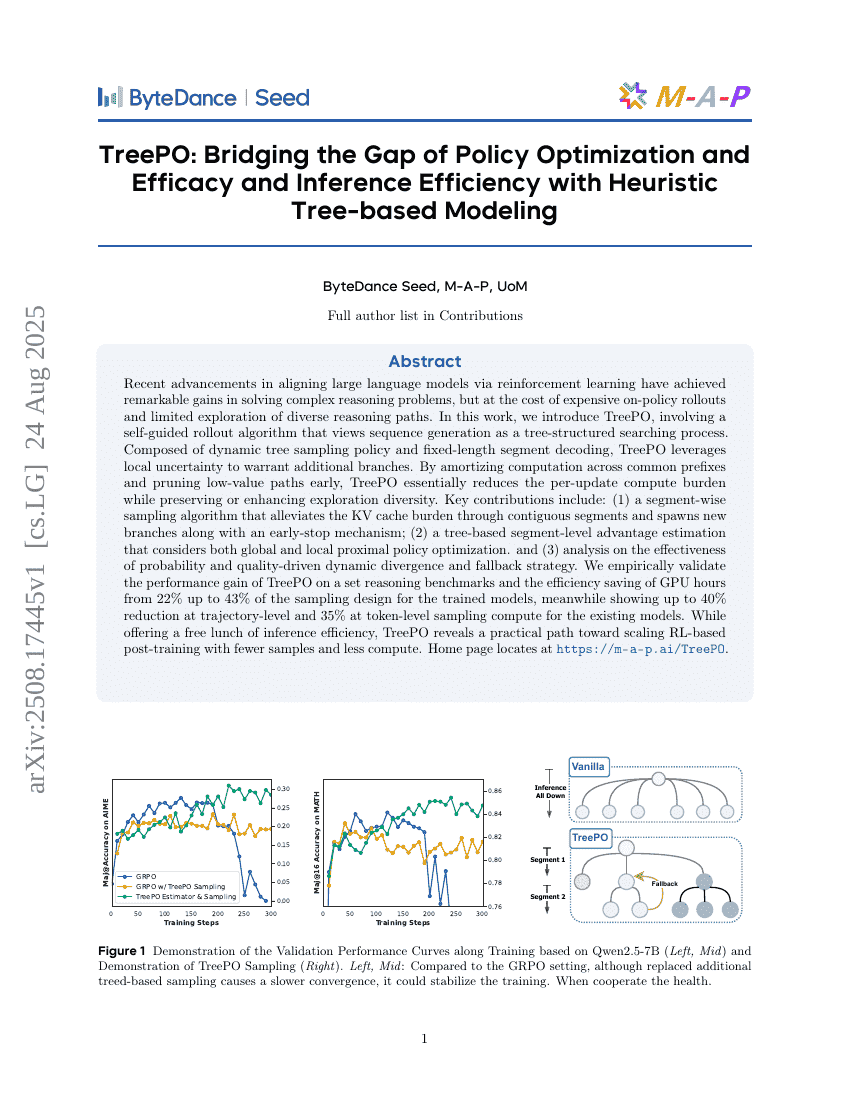
TreePO:基于启发式树建模弥合策略优化与有效性及推理效率之间的差距
Nemotron-CC-Math:一个1330亿token规模的高质量数学预训练数据集
理解工具集成推理
Spacer:面向工程化科学灵感
超越记忆:通过循环、记忆与测试时计算扩展实现推理深度延伸
A.S.E:面向AI生成代码安全性的仓库级基准测试
EmbodiedOneVision:面向通用机器人控制的交织视觉-文本-动作预训练
R-4B:通过双模式退火与强化学习激励多模态大模型的通用自动思考能力
激发小规模语言模型的创意写作:基于LLM的评判与多智能体精炼奖励
TMUAD:通过文本记忆库增强统一异常检测模型的逻辑能力
思维链动态分析:主动引导还是不忠实的事后合理化?
AWorld:面向智能体AI训练配方的编排
MCP-Bench:通过MCP服务器对复杂现实世界任务中使用工具的LLM Agent进行基准测试
rStar2-Agent:代理式推理技术报告
Pref-GRPO:基于成对偏好奖励的GRPO用于稳定文本到图像强化学习
MobileCLIP2:提升多模态强化训练
AI-AI 审美协作:显式符号学意识与涌现语法发展
凝视心灵:用于rPPG与健康生物标志物估计的多视角视频数据集
预测下一个标记的顺序可提升语言建模性能
MIDAS:通过实时自回归视频生成实现的多模态交互式数字人合成
离散扩散VLA:将离散扩散引入视觉-语言-动作策略中的动作解码
通过推理分解的自奖励视觉-语言模型
超越转录:自动语音识别中的机制可解释性
CODA:面向解耦强化学习的双脑计算机使用Agent中大脑与小脑的协同机制
WebSight:一种面向视觉的鲁棒网络智能体架构
UltraMemV2:面向120B参数的内存网络,具备卓越的长上下文学习能力
Hermes 4 技术报告
OmniHuman-1.5:通过认知模拟为虚拟化身注入主动思维
VoxHammer:无需训练的原生3D空间中精确且连贯的3D编辑
CMPhysBench:用于评估大语言模型在凝聚态物理领域性能的基准测试
TreePO:基于启发式树建模弥合策略优化与有效性及推理效率之间的差距
Nemotron-CC-Math:一个1330亿token规模的高质量数学预训练数据集
理解工具集成推理
Spacer:面向工程化科学灵感
超越记忆:通过循环、记忆与测试时计算扩展实现推理深度延伸