Command Palette
Search for a command to run...
With Depth Estimation Accuracy Reaching 0.9, Meta Proposed VLM³, Demonstrating That Visual Models Are Inherently Capable of Learning 3D, and Achieving Unified Modeling for Multiple Tasks Based on Qwen3-VL-4B.

Three-dimensional spatial perception is a core foundational capability in fields such as autonomous driving, robotics, and 3D reconstruction. Its goal is to recover the spatial structure, scale information, and geometric relationships of the real world from two-dimensional images. Compared to two-dimensional vision tasks such as image classification and object detection,Three-dimensional perception requires not only semantic understanding capabilities, but also accurate spatial reasoning and geometric modeling.Therefore, it has long been regarded as one of the most challenging research directions in the field of computer vision.
In recent years, Visual-Language Models (VLMs) have made significant progress in 2D tasks such as classification, detection, and segmentation thanks to their unified architecture and large-scale pre-training. However, in fine-grained tasks requiring precise spatial reasoning, such as depth estimation, pixel matching, and camera pose determination, the performance of standard VLMs still lags behind that of specialized 3D models. Currently,The field of 3D vision has not yet developed a universal basic model similar to that in 2D vision. Mainstream methods still rely on expert models designed for specific tasks.This includes specialized network structures, loss functions, and training strategies.
Recent research has found that the standard Visual Language Model (VLM) without specific 3D modifications already exhibits a certain pixel-level depth perception capability. This phenomenon suggests that general-purpose visual language models may possess stronger 3D representation capabilities than expected, and also raises a question worth exploring further: can the standard VLM handle a wider range of fine-grained 3D perception tasks without introducing additional encoders, visual cues, or task-specific modules?
To address this issue,Meta, in collaboration with Princeton University, proposed the VLM³ (VLM Cubed) framework.Based on the standard visual language model, this study achieves unified modeling for four types of tasks—object-level 3D understanding, metric depth estimation, pixel matching, and camera pose solving—through a unified data organization method and training paradigm. It also systematically evaluates the capability boundaries of the standard VLM in fine-grained 3D perception.
The related research findings, titled "VLM3: Vision Language Models Are Native 3D Learners," have been published on the preprint platform arXiv.
Research highlights:
* On the SpatialRGPT benchmark, the VLM³-4B outperforms the larger SpatialRGPT-8B with a more streamlined architecture, requiring no additional encoder.
* Compared to the previous best visual language model, DepthLM-7B, VLM³-4B improves the average accuracy δ₁ from 0.84 to 0.90, achieving performance on par with the professional depth estimation model UnidepthV2.
* VLM³ reduces the endpoint error (EPE) of baseline visual language models by an order of magnitude, outperforming classic expert models such as DKM and RoMa.
* VLM³ significantly improves the AUC₃₀° metric from a near-random level of 5% to 94%, surpassing VGGT and reaching a level comparable to DA3-Giant.
View the paper:
https://hyper.ai/papers/2605.30561
Hybrid datasets for multi-task 3D perception
3D perception tasks involve various factors such as scene scale, viewpoint changes, camera parameters, and geometric relationships, placing high demands on the quality and coverage of training data. To support the learning of unified 3D representation capabilities,This study constructs a hybrid data system covering single-view and multi-view scenes, encompassing three types of tasks: metric depth estimation, object-level 3D understanding, and pixel matching and camera pose estimation.
In the metric depth estimation taskThe researchers used a large-scale, multi-scene hybrid dataset. The base data is inherited from DepthLM and includes mainstream 3D scene data such as Argoverse2, Waymo, NuScenes, ScanNet++, Taskonomy, HM3D, and Matterport3D. In addition, 10 million self-built outdoor street scene images were introduced, expanding the training scale from 16 million to 26 million images.The final model training used approximately 32 million images and 320 million depth annotations.It covers a variety of scenarios, including indoor, outdoor, street scenes, and complex open environments.
Unlike existing work, VLM³ does not employ a uniform sampling strategy. Instead, it designs differentiated training weights based on dataset size, learning difficulty, and generalization value. Experiments show that small datasets are more prone to overfitting during mixed training, and simply increasing the number of data sources does not necessarily lead to performance improvements. Therefore, the research team appropriately reduced the training weights of some small datasets to improve overall generalization ability.
The object-level 3D understanding task uses the same standard dataset as SpatialRGPT.It includes approximately 1 million training images and accompanying qualitative and quantitative question-answering samples. This dataset has become an important benchmark for current object-level 3D understanding tasks. A large number of the images lack camera intrinsic information, making it closer to real-world application scenarios and thus more realistically reflecting the model's spatial reasoning capabilities.
For the pixel matching and camera pose estimation tasks, the research team constructed a unified multi-view training dataset.This dataset integrates 14 mainstream data sources, including BlendedMVS, DynamicReplica, SailVOS3D, and ScanNet++, containing approximately 9.9 million image pairs. To ensure training quality, researchers only retained samples with visual overlap exceeding 251 TP3T between images, and reserved 30 independent scenes from ScanNet++ as a dedicated test set, thus avoiding data leakage between the training and test sets. The dataset weights are configured based on the original number of image pairs from each data source, further enhancing the stability and adaptability of the training process.
VLM³ Model: Unified 3D Learning under the Principle of Minimal Modification
The design goal of VLM³ is not to build a new 3D vision architecture, but to evaluate its potential capabilities in fine-grained 3D tasks while maintaining the original structure of standard visual language models. Therefore, the entire framework follows the "principle of minimal modification," without introducing additional encoders, proprietary loss functions, or task-customized modules.Instead, the focus is on optimizing three aspects: input representation, spatial positioning methods, and data organization strategies.
The study uses Qwen3-VL-4B as the base model and employs the standard Supervised Fine-Tuning (SFT) paradigm throughout the training process, maintaining consistency with the pre-training and fine-tuning workflow of existing visual language models. This design ensures that the framework is directly compatible with mainstream VLM systems without requiring the construction of an additional dedicated training pipeline.
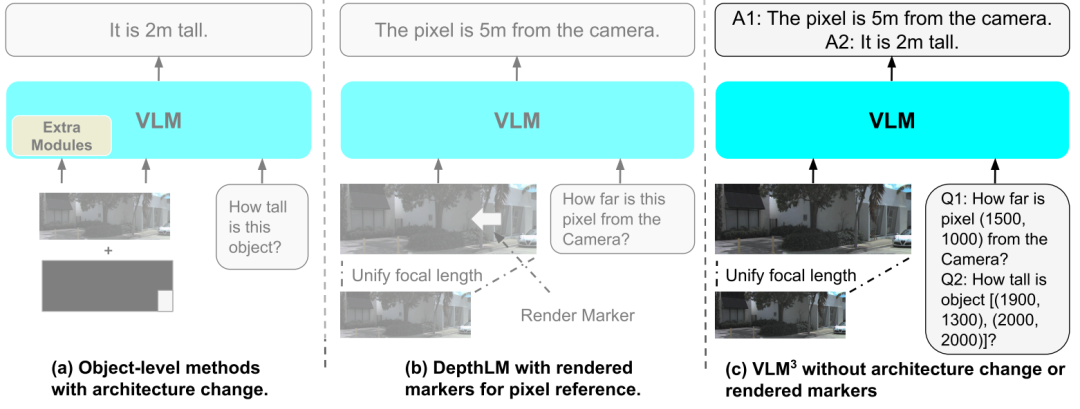
First, regarding the issue of inconsistent camera parameters between different data sources,VLM³ proposes a unified image standardization strategy.Research has found that significant differences in camera intrinsic parameters often exist between multi-source 3D datasets, with some network images even lacking camera parameter information. This directly impacts the model's ability to learn spatial geometric relationships. Therefore,The framework maps all input images to a standard focal length space and estimates the missing intrinsic parameters using existing single-image calibration models.This reduces the distribution shift caused by differences in imaging conditions.
Secondly,VLM³ adopts a unified textual spatial positioning paradigm.Traditional 3D vision models typically rely on additional visual cues, rendered markers, or specially designed positional encoding modules to achieve pixel-level localization. VLM³, however, normalizes image coordinates to a unified coordinate space and expresses positional relationships in text form. In this way, the model can leverage native language modeling capabilities to perform pixel-level localization, region localization, and cross-view correspondence learning without introducing additional visual modules. Simultaneously, a single image can contain multiple localization question-answering samples, significantly improving training efficiency. In depth estimation tasks,The amount of supervisory signal that a single sample can provide is about 10 times higher than that of traditional schemes, while the computational cost remains almost unchanged.
The third core design is a sophisticated data mixing strategy.Unlike many methods that rely on complex network structures to improve performance, VLM³ focuses its optimization efforts on the data organization level. Through extensive experiments, the research team discovered that blindly expanding the data size or using equal-weighted mixed training often leads to performance saturation or even degradation. In contrast, designing differentiated sampling strategies based on data size and task characteristics can more effectively improve the model's three-dimensional representation capabilities. Therefore, data allocation is considered a crucial component of the entire framework, rather than merely an auxiliary factor in the training process.
Based on the above designVLM³ further enables unified modeling for four types of 3D tasks.Depth estimation constructs supervised samples through textual pixel localization; object-level 3D understanding uses text coordinate boxes instead of dedicated mask encoders; pixel matching transforms cross-view correspondences into coordinate prediction problems; and camera pose estimation decomposes complex geometric parameters into text-based question-and-answer formats such as translation distance, translation direction, and rotation angle. Tasks that originally relied on different models for processing are ultimately unified into the autoregressive generative framework of the standard VLM.
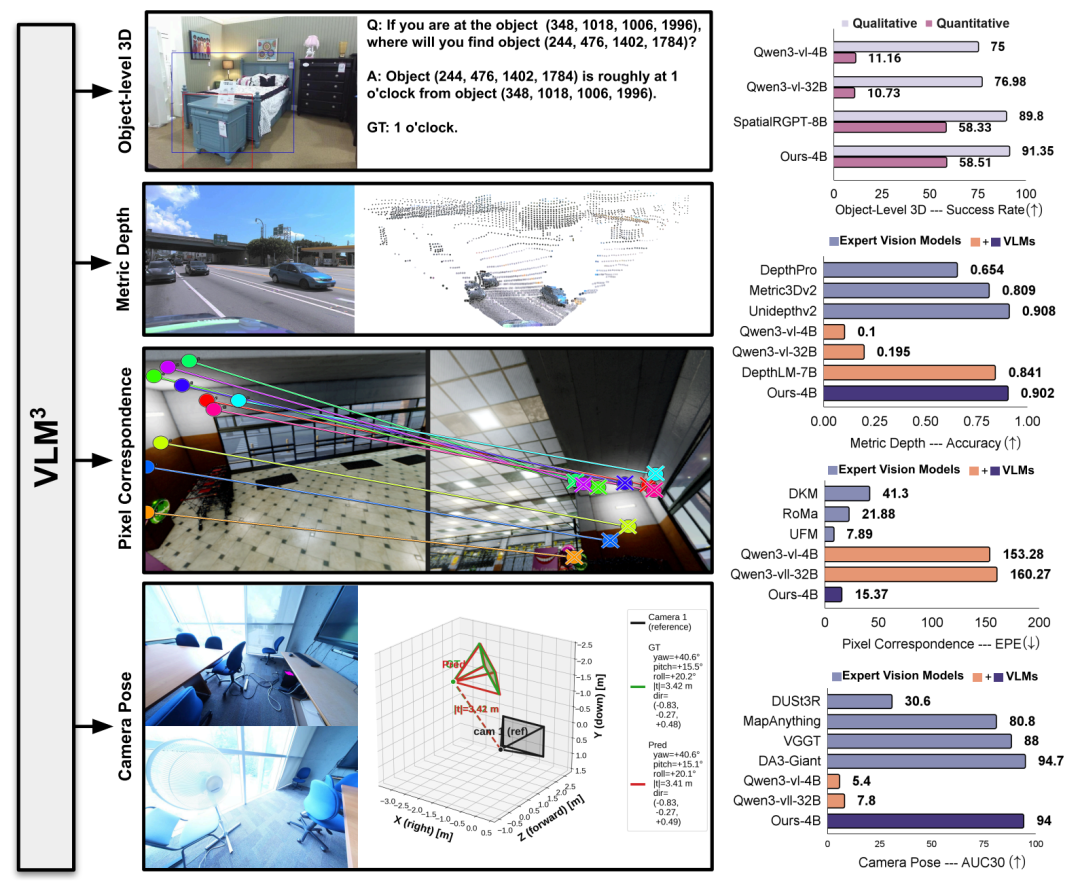
For the first time, the standard visual language model has achieved high-precision 3D understanding on multiple fine-grained 3D tasks.
In order to systematically evaluate the effectiveness of VLM³,The research team conducted experiments on four types of tasks: metric depth estimation, object-level 3D understanding, pixel matching, and camera pose estimation.It is compared with general visual language models and current mainstream expert models.
In the metric depth estimation taskThe study selects nine public datasets for comparison with a general VLM and benchmarks it against the current state-of-the-art expert model on five representative benchmarks.Using δ₁ as the primary evaluation metric, the results are shown in the table below. VLM³-4B comprehensively outperforms the previously representative method, DepthLM-7B.The average accuracy improved from 0.84 to 0.90, setting a new record on multiple datasets.At the same time, its overall performance has reached the level of professional depth estimation models such as UnidepthV2 and MoGe-2.
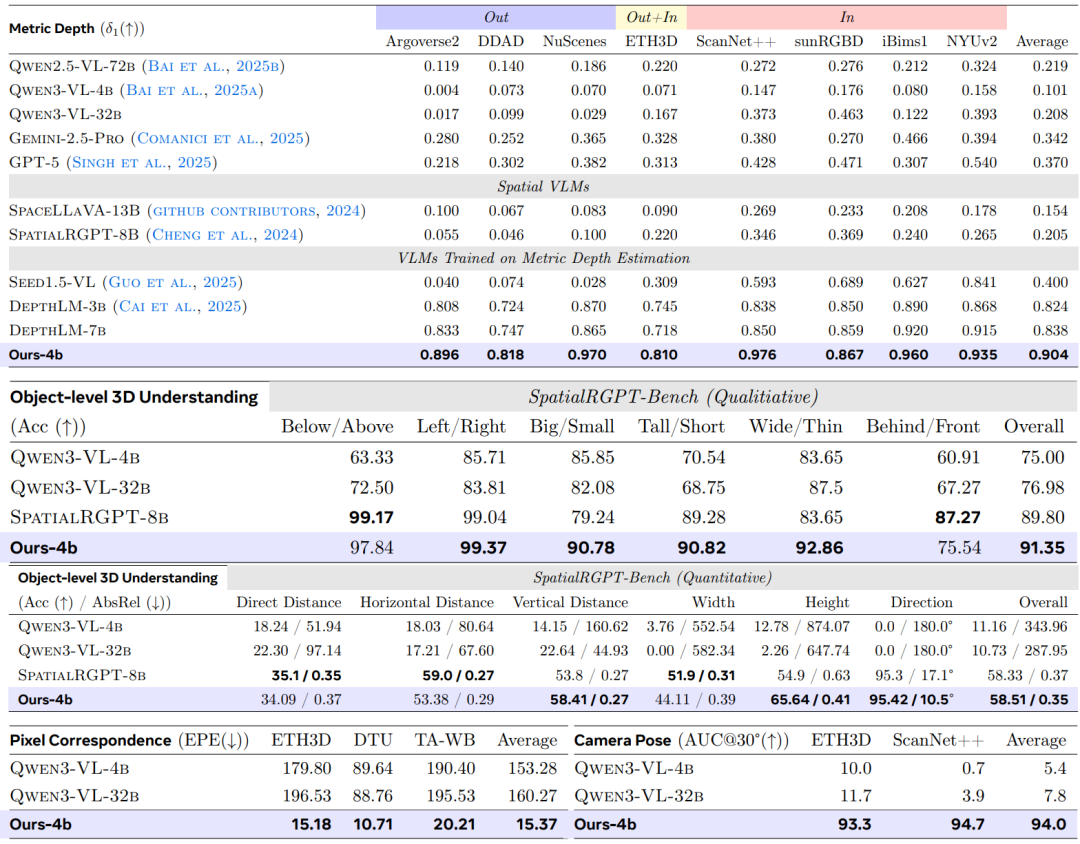
In the object-level 3D understanding task, the study fully reused the evaluation framework of SpatialRGPT. The results show that...The VLM³, with a parameter size of only 4B, outperforms the SpatialRGPT, which has a size of 8B, in both qualitative and quantitative evaluations.The latter relies on an additional mask encoder to complete spatial localization, while VLM³ can obtain better results by relying solely on the unified text localization mechanism, indicating that unified textual modeling has strong effectiveness in spatial reasoning tasks.
The pixel matching task employs the UFM evaluation system, with End Point Error (EPE) as the core metric. Experimental results show that VLM³ reduces the error by an order of magnitude compared to the basic VLM, surpasses classic expert models such as DKM and RoMa, and is only slightly below the current state-of-the-art method, UFM. This indicates that...The unified text-based modeling approach is not only applicable to single-view scenes, but can also effectively learn cross-view geometric correspondences.
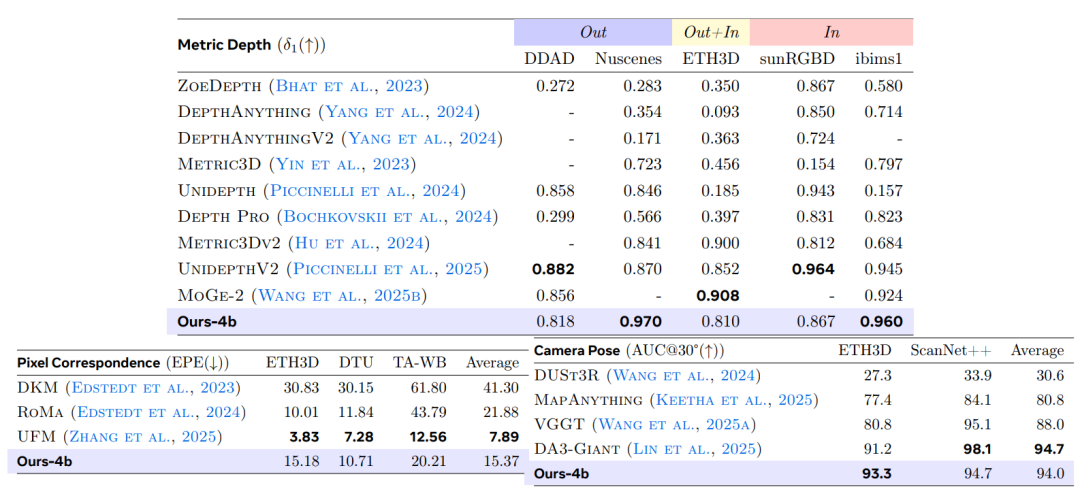
In the camera pose estimation task, the study uses the AUC₃₀° metric for evaluation on the ETH3D and ScanNet++ datasets, respectively. The results show that...VLM³ improves the performance of the base VLM from near-random prediction levels to an AUC₃₀° of 94%.It surpasses mainstream methods such as VGGT and MapAnything, and approaches the performance level of the current best model, DA3-Giant.
Final Thoughts
For a long time, 3D vision research has mainly followed a "task-driven" approach: designing dedicated models for different tasks such as depth estimation, pixel matching, or pose solving. VLM³, however, demonstrates a different possibility—without introducing additional encoders, proprietary loss functions, or complex visual cueing mechanisms, a standard visual language model can achieve performance comparable to or even surpassing some expert models on multiple fine-grained 3D tasks simply through standardized image processing, textual spatial modeling, and refined data strategies. This research result suggests that the 3D representation capabilities of a general visual language model may far exceed previous expectations, and provides new empirical evidence for the shift in 3D vision from "task-specific optimization" to a "unified basic model."