Command Palette
Search for a command to run...
Paper Weekly Report | Microsoft MAI-Thinking Explores self-evolution of Pure RL, Achieving an AIME Accuracy of 97%; VLM³ Achieves 3D Task Generalization Using Plain Text Coordinates Without Architectural Modifications… A Quick Overview of the week's cutting-edge AI Papers

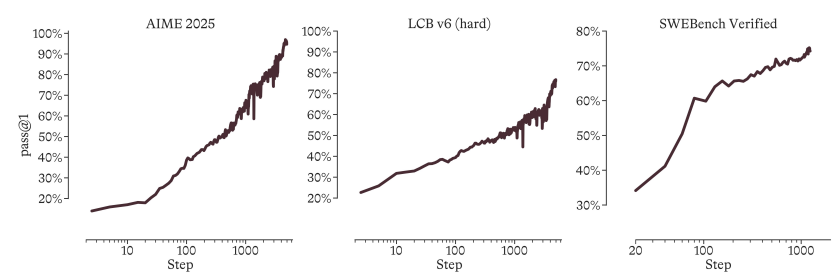
Advances in artificial intelligence depend not only on breakthroughs in individual models, but more importantly on building systems capable of continuous self-improvement. To this end, Microsoft's AI team views model development as a system-level optimization problem.A "hill-climbing machine" framework designed to achieve rapid and sustained performance improvements is proposed."Based on this, a MoE inference model MAI-Thinking-1 with a total parameter of 1T and activation parameter of 35B was trained from scratch.
The model completely discards distillation data from third-party models during the pre-training phase and introduces the GRPO algorithm with adaptive entropy control and a self-distillation mechanism during the reinforcement learning (RL) phase.Experimental results show that even starting without any prior inference trajectories, MAI-Thinking-1 can achieve long-term and stable log-linear performance growth.Ultimately, it achieved state-of-the-art levels of complex inference and code generation on core benchmarks such as AIME 2025 (97.0%) and SWE-Bench Pro (52.8%).
Paper link:https://go.hyper.ai/QeSWd
Latest AI Papers:https://go.hyper.ai/hzChC
To help more users understand the latest developments in the field of artificial intelligence in academia,The HyperAI website (hyper.ai) now features a "Latest Papers" section, which is regularly updated with cutting-edge AI research papers.Here are 9 popular AI papers we recommend. Let's quickly take a look at the latest AI achievements this week ⬇️
This week's paper recommendation
1. MAI-Thinking-1
Paper title:
MAI-Thinking-1: Building a Hill-Climbing Machine
Microsoft's AI team proposed a "hill-climbing" approach, treating model development as a system-level optimization problem. They trained the MoE inference model MAI-Thinking-1 from scratch, with a total of 1T parameters and 35B activation parameters. The model's pre-training was entirely based on clean data, without using any third-party distilled data. During the reinforcement learning phase, the team achieved stable and long-term performance growth without an initial inference trajectory by using the GRPO algorithm with adaptive entropy control and a self-distillation mechanism. The model ultimately integrates capabilities from three expert areas: STEM, code agent, and security, demonstrating class-leading inference and code performance on benchmarks such as AIME 2025 (97.0%) and SWE-Bench Pro (52.8%).
Paper and detailed interpretation:https://go.hyper.ai/QeSWd
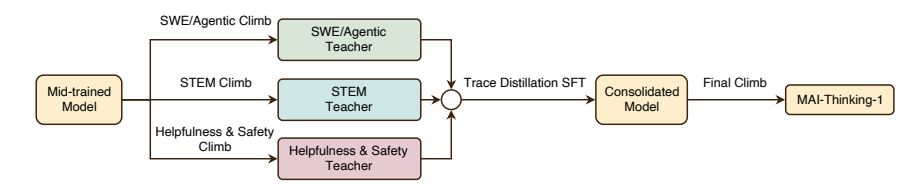
2. VLM³
Paper title:
VLM³: Vision Language Models Are Native 3D Learners
Meta and his team discovered through large-scale experiments that enabling VLMs to perform efficient 3D learning does not require complex architectures or specialized designs; it only requires a unified focal length, the introduction of text-based pixel references, and reasonable data mixing and expansion strategies. Based on this discovery, the research team proposed VLM³, a minimalist design that allows standard VLMs to simultaneously perform tasks such as depth estimation, pixel-level correspondence, camera pose estimation, and object-level 3D understanding. While maintaining the original architecture and text-based training method, VLM³'s performance has approached or even rivaled that of expert-level visual models, providing a simpler and more scalable new path for general-purpose visual models to learn the 3D world.
Paper and detailed interpretation:https://go.hyper.ai/5ks6r
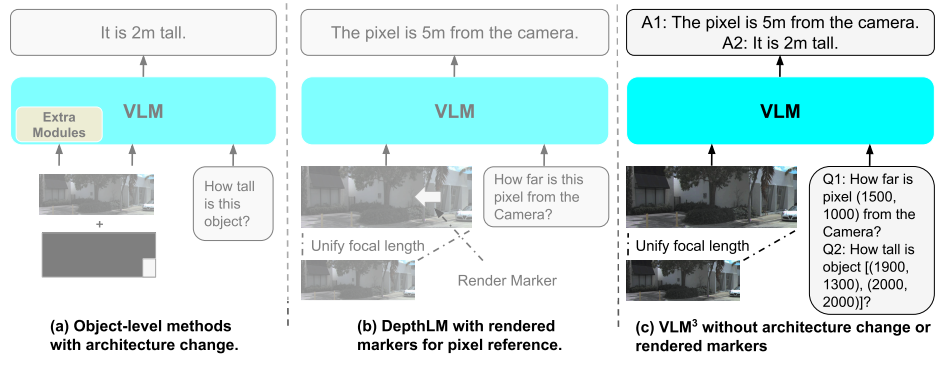
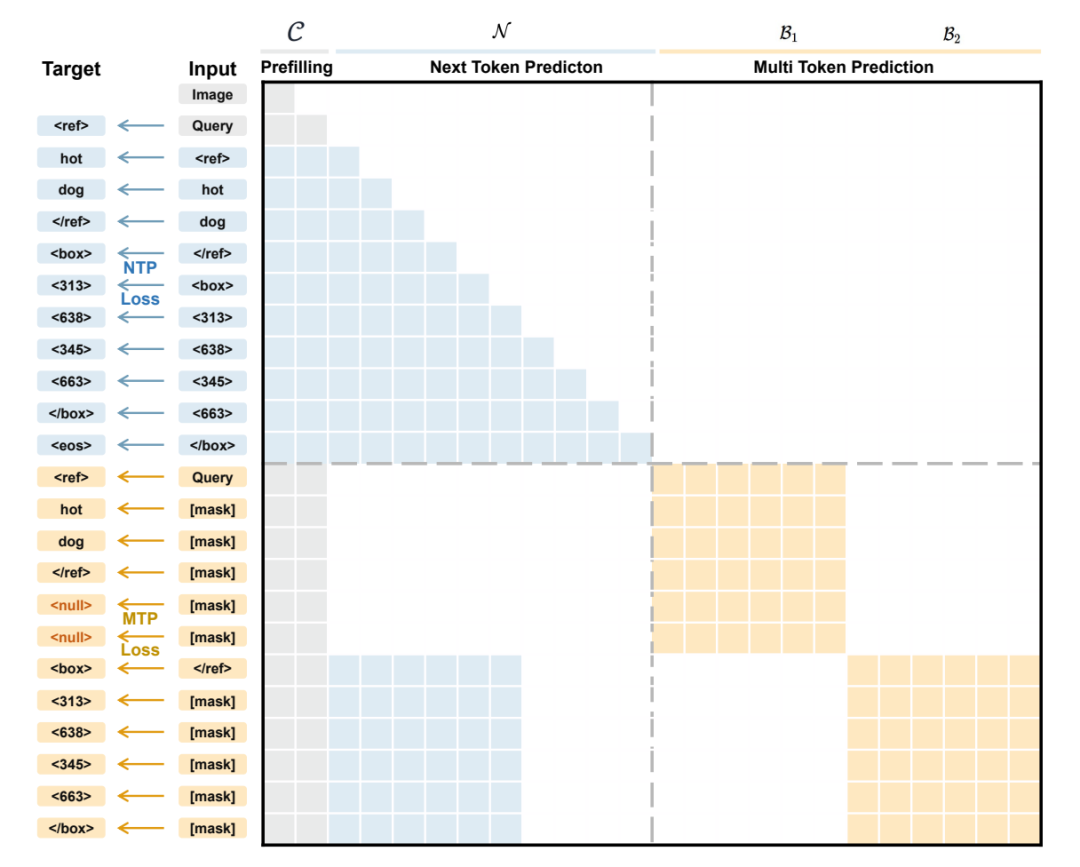
3. LocateAnything
Paper title:
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
Existing visual language models typically model object localization as a step-by-step generation process of coordinate tokens, requiring sequential prediction of bounding box coordinates. This not only ignores the geometric relationships within the boxes but also limits inference speed. To address this issue, the NVIDIA team proposed LocateAnything, which uses a parallel box decoding (PBD) mechanism to treat the bounding box as an atomic unit, generating its complete coordinate set in parallel within a single step. Combined with a massive dataset containing 138 million queries and a hybrid inference mode with intelligent error fallback, this model achieves higher decoding throughput and better high IoU localization accuracy across multiple benchmarks, pushing the speed and accuracy limits of unified visual localization and detection tasks.
Paper and detailed interpretation:https://go.hyper.ai/C8jXC
Dataset composition and source: The research team constructed LocateAnything-Data, a large-scale corpus containing 12 million unique images, 138 million natural language queries, and 785 million labeled bounding boxes.

4. Qwen-VLA
Paper title:
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Embodied intelligence research has long relied on specialized models for single tasks, leading to fragmented capabilities and limited generalization. The Qianwen team proposes Qwen-VLA, a unified vision-language-action foundational model. Through a DiT-based action decoder, it extends vision-language perception, understanding, and reasoning to continuous actions and trajectory generation. The model employs large-scale joint pre-training, encompassing robot operation trajectories, human first-person demonstrations, simulation data, navigation tasks, and auxiliary vision-language signals. It also adapts to various robot platforms through an embodied perception cue conditionalization mechanism. Qwen-VLA integrates operation, navigation, and trajectory prediction into a unified framework, achieving transferability across tasks, environments, and robot forms. Experiments demonstrate that the model exhibits stable multi-task performance and out-of-distribution generalization capabilities across multiple operation and navigation benchmarks.
Paper and detailed interpretation:https://go.hyper.ai/5x2Tj
Dataset composition and sources: The research team constructed a large-scale heterogeneous pre-trained corpus to unify visual, language, and action modeling. Data sources include more than ten public robot benchmarks, a large-scale human video corpus, proprietary internally collected data, and internally generated simulation pipelines.

5. SDPG
Paper title:
Self-Distilled Policy Gradient
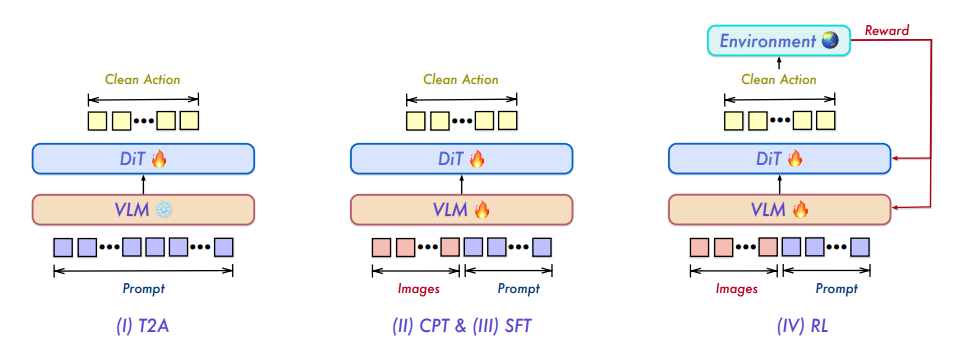
Policy-based self-distillation (SDPG) utilizes the privileged context of the model to supervise its own generated results, providing denser learning signals for sparse reward reinforcement learning. It can be formalized as a reverse KL student-teacher loss over the entire vocabulary. Building on this, researchers from UCLA and Princeton University jointly proposed the SDPG framework, combining group relative validator advantage, standard deviation normalization, online full-vocabulary self-distillation, and reference policy KL regularization. Experiments show that SDPG improves stability and performance compared to RLVR and existing self-distillation methods.
Paper and detailed interpretation:https://go.hyper.ai/p5irp
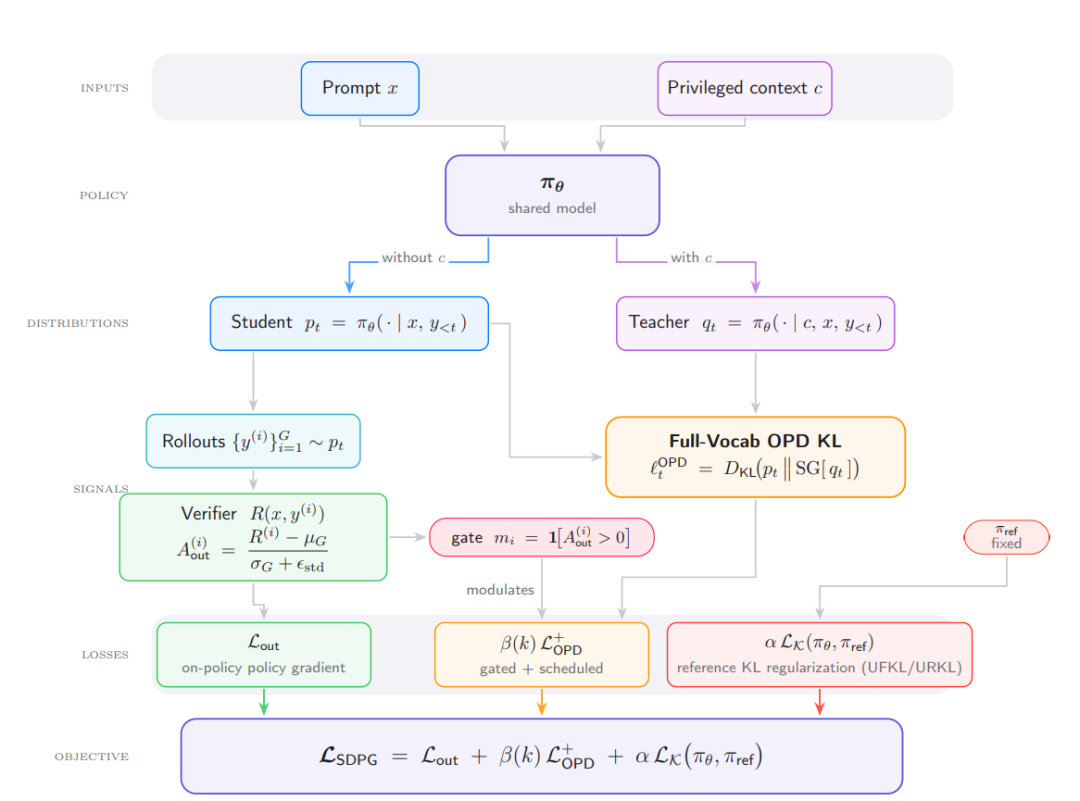
6. GSM-Symbolic
Paper title:
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Research indicates that traditional GSM8K benchmarks are insufficient to accurately reflect the true performance of models. Therefore, the Apple team constructed a controllable benchmark, GSM-Symbolic, based on symbolic templates. Experiments show that simply changing the numbers or entity names in the questions causes significant fluctuations in the performance of large models; and adding irrelevant distracting clauses further drastically reduces accuracy. The research team hypothesizes that current LLMs do not possess true logical reasoning capabilities but rather attempt to reproduce the reasoning steps observed in their training data.
Paper and detailed interpretation:https://go.hyper.ai/n3UfJ
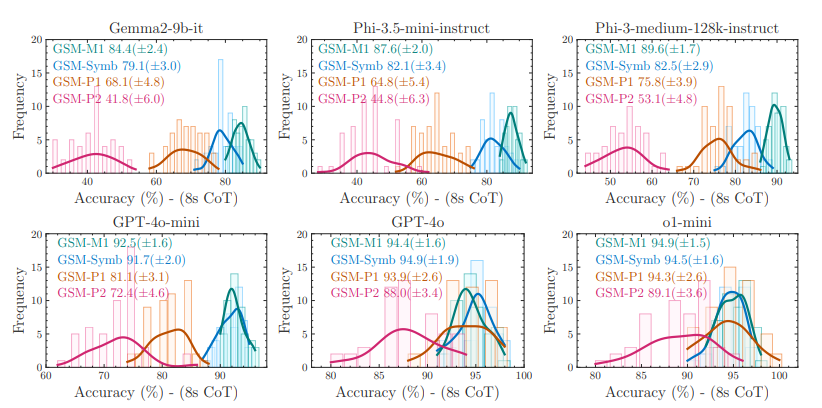
7. MUSE-Autoskill
Paper title:
MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
Teams including ByteDance proposed the MUSE-Autoskill intelligent agent framework, which unifies the creation, memorization, management, evaluation, and optimization of skills into a complete lifecycle. This framework breaks through the limitations of traditional static and isolated skills by introducing skill-level memory to accumulate experience across tasks. Experiments on SkillsBench provide preliminary evidence that lifecycle-managed skills can improve task success rate, execution efficiency, reusability, and cross-agent transferability, highlighting the importance of treating skills as long-lifecycle, experience-aware, and testable assets.
Paper and detailed interpretation:https://go.hyper.ai/mdgB2
8. Nemotron 3 Ultra
Paper title:
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
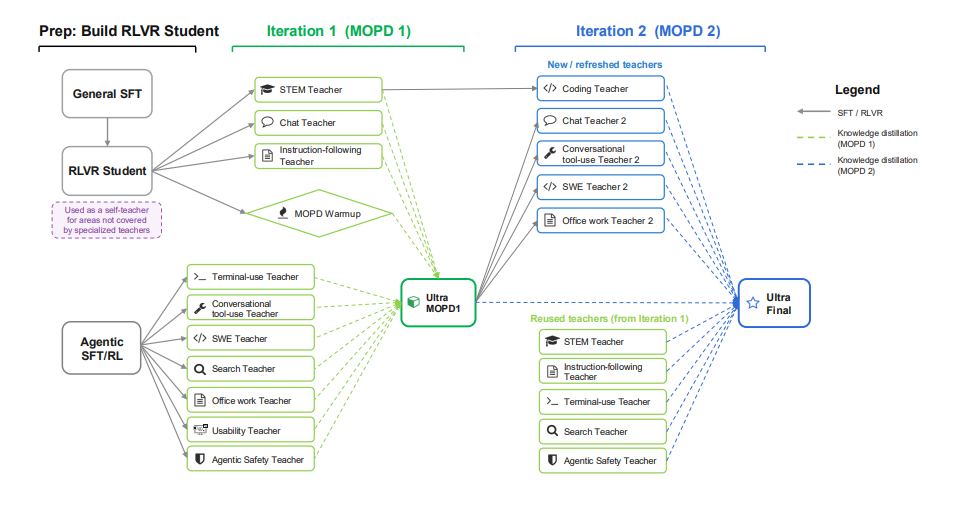
NVIDIA has released Nemotron 3 Ultra, a Mamba-Attention MoE language model with 550 billion parameters and 55 billion activation parameters. This model is pre-trained on 20 trillion tokens, with the context length extended to 1 million tokens, and post-trained using SFT, RL, and Multi-Teacher Online Policy Distillation (MOPD). Employing techniques such as LatentMoE, multi-token prediction, NVFP4, RLVR, MOPD, and inference budget control, Nemotron 3 Ultra achieves approximately 6x higher inference throughput than existing public LLMs while maintaining high accuracy, making it suitable for long-term autonomous agentic tasks.
Paper and detailed interpretation:https://go.hyper.ai/lm6S1
9. Cosmos 3
Paper title:
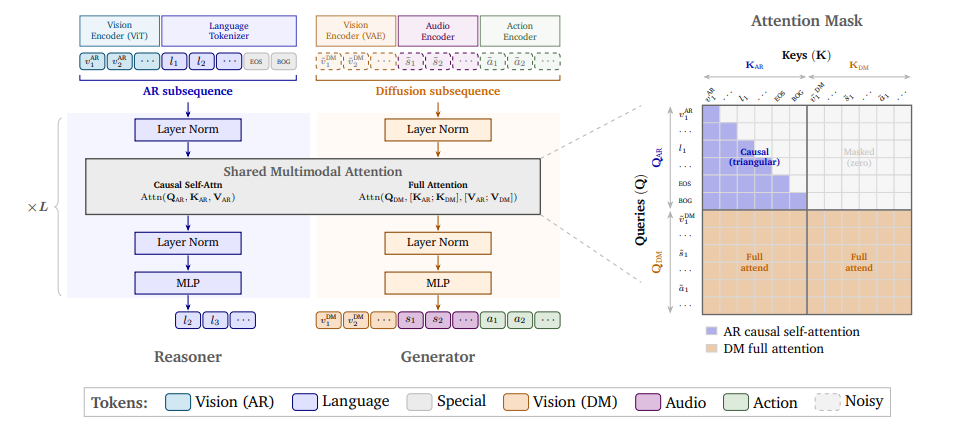
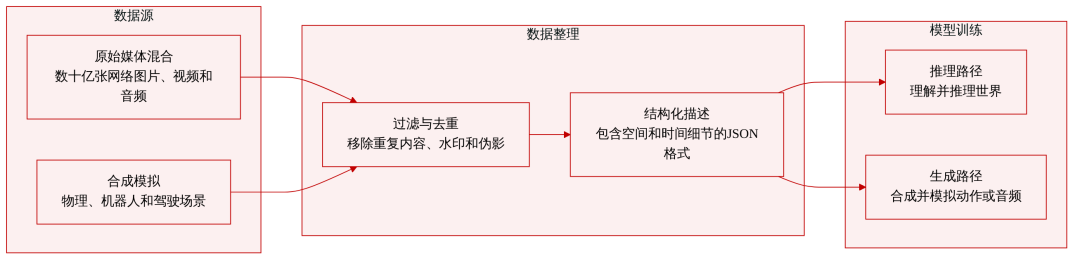
Cosmos 3: Omnimodal World Models for Physical AI
NVIDIA has released Cosmos 3, a suite of multimodal world models that process and generate language, images, video, audio, and action sequences within a unified hybrid Transformer architecture. Cosmos 3 supports highly flexible input/output configurations, integrating visual language models, video generators, world simulators, and action models into a single framework. Evaluations show it achieves state-of-the-art results in diverse understanding and generation tasks, validating multimodal world models as general backbone networks for embodied agents. Post-trained models were rated as best open-source text-to-image/image-to-video models and best policy models.
Paper and detailed interpretation:https://go.hyper.ai/RoY2u
The above is all the content of this week’s paper recommendation. For more cutting-edge AI research papers, please visit the “Latest Papers” section of hyper.ai’s official website.
We also welcome research teams to submit high-quality results and papers to us. Those interested can add the NeuroStar WeChat (WeChat ID: Hyperai01).
See you next week!








