Command Palette
Search for a command to run...
Extended Batch Normalization
Extended Batch Normalization
Chunjie Luo Jianfeng Zhan Lei Wang Wanling Gao
Batch Normalization
Abstract
Batch normalization (BN) has become a standard technique for training the modern deep networks. However, its effectiveness diminishes when the batch size becomes smaller, since the batch statistics estimation becomes inaccurate. That hinders batch normalizations usage for 1) training larger model which requires small batches constrained by memory consumption, 2) training on mobile or embedded devices of which the memory resource is limited. In this paper, we propose a simple but effective method, called extended batch normalization (EBN). For NCHW format feature maps, extended batch normalization computes the mean along the (N, H, W) dimensions, as the same as batch normalization, to maintain the advantage of batch normalization. To alleviate the problem caused by small batch size, extended batch normalization computes the standard deviation along the (N, C, H, W) dimensions, thus enlarges the number of samples from which the standard deviation is computed. We compare extended batch normalization with batch normalization and group normalization on the datasets of MNIST, CIFAR-10/100, STL-10, and ImageNet, respectively. The experiments show that extended batch normalization alleviates the problem of batch normalization with small batch size while achieving close performances to batch normalization with large batch size.
One-sentence Summary
The authors propose Extended Batch Normalization (EBN), a method that preserves the standard (N, H, W) mean calculation but computes the standard deviation across all (N, C, H, W) dimensions to enlarge the effective sample size, thereby mitigating small-batch performance degradation while matching large-batch accuracy across MNIST, CIFAR-10/100, STL-10, and ImageNet.
Key Contributions
- Introduces Extended Batch Normalization (EBN), a normalization method that addresses performance degradation in deep networks trained with small batch sizes due to memory constraints.
- Computes feature means along the (N, H, W) dimensions to retain standard batch normalization properties, while calculating standard deviations across the (N, C, H, W) dimensions to enlarge the sample pool for variance estimation.
- Evaluates the method on MNIST, CIFAR-10/100, STL-10, and ImageNet against batch normalization and group normalization, demonstrating that EBN alleviates small-batch limitations while matching the accuracy of large-batch training.
Introduction
Batch normalization is a foundational technique for stabilizing deep neural network training, making it essential for scaling model capacity and deploying to memory-constrained edge devices. Standard implementations struggle when batch sizes shrink, as inaccurate statistical estimates destabilize training and degrade accuracy. The authors introduce extended batch normalization (EBN), which preserves the standard mean calculation across batch and spatial dimensions but expands the standard deviation computation to include the channel dimension. This simple adjustment increases the effective sample size for variance estimation, allowing stable training with small batches while matching the performance of traditional large-batch normalization.
Method
The authors propose extended batch normalization (EBN), a method designed to address the limitations of batch normalization under small batch sizes while preserving its beneficial properties. The core idea of EBN lies in decoupling the computation of the mean and standard deviation from different subsets of pixels within the feature tensor. For a feature tensor in NCHW format, where N is the batch dimension, C is the channel dimension, and H and W are the spatial dimensions, EBN computes the mean across the (N, H, W) dimensions, similar to standard batch normalization. This choice maintains the advantage of considering multiple examples in a batch, which helps stabilize learning and provides implicit regularization through sampling noise. However, to mitigate the inaccuracy of standard deviation estimation caused by a small number of samples, EBN computes the standard deviation over the entire set of pixels in the feature tensor, i.e., along the (N, C, H, W) dimensions. This significantly enlarges the sample set used for variance calculation, leading to a more robust and accurate estimation of the standard deviation, particularly effective when the batch size is small or the spatial resolution is low.
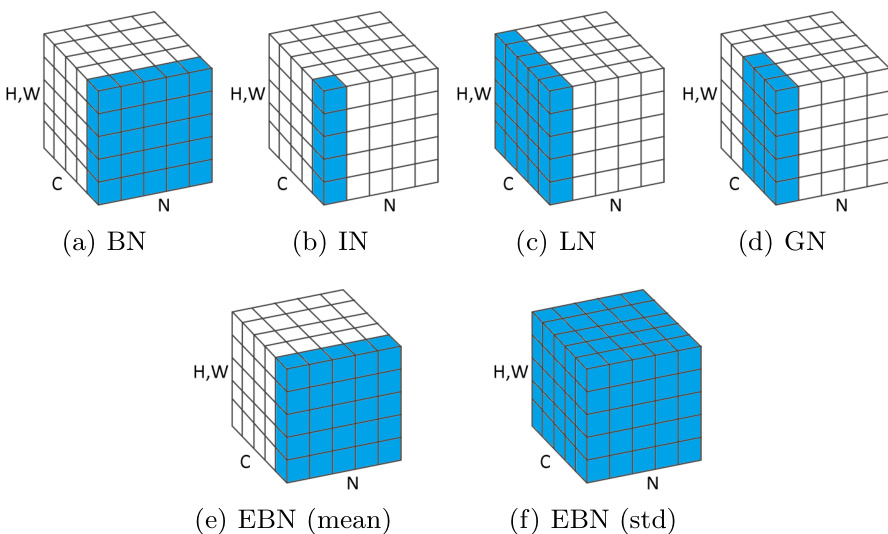
The framework for EBN is illustrated in Figure 1. As shown in the figure, the mean computation in EBN (panel e) is identical to batch normalization (BN), aggregating statistics across the batch and spatial dimensions (N, H, W). In contrast, the standard deviation computation in EBN (panel f) aggregates statistics across the entire feature set (N, C, H, W), which is visually represented by the blue volume encompassing all channels within the batch. This design contrasts with other normalization methods: instance normalization (IN) computes statistics only over the spatial dimensions (H, W), layer normalization (LN) computes them over (C, H, W), and group normalization (GN) computes them over (H, W) and a group of channels. By using different sets for mean and standard deviation computation, EBN achieves a balance between the benefits of batch-level statistics and the robustness of larger sample sets.
At inference time, EBN operates similarly to batch normalization. The mean and standard deviation are not computed from the current input but are pre-computed using a moving average of the training statistics. This process is formalized with the equations μrt=(1−ρ)μrt−1+ρμbt and σrt=(1−ρ)σrt−1+ρσbt, where μrt and σrt are the running mean and standard deviation, μbt and σbt are the batch statistics, and ρ is a momentum constant. This eliminates the need for per-sample computation during inference, a significant advantage over methods like group normalization. Furthermore, because the normalization parameters are fixed, the EBN operation can be fused directly into the preceding convolution layer, which is highly beneficial for optimizing inference speed on resource-constrained mobile or embedded devices.
Experiment
The experiments evaluate Extended Batch Normalization (EBN) against standard Batch Normalization (BN) and Group Normalization (GN) across multiple datasets and architectures to validate their stability and accuracy under varying batch regimes. Results indicate that while BN and EBN yield comparable performance with large batch sizes, EBN consistently outperforms both methods when batch sizes are reduced. By mitigating the severe instability and accuracy degradation inherent to small-batch training in BN, EBN successfully bridges the performance gap, combining the high accuracy of BN with the robust reliability of GN.
The authors compare extended batch normalization (EBN) with batch normalization (BN) and group normalization (GN) across multiple datasets and batch sizes. Results show that EBN maintains performance close to BN under large batch sizes and outperforms both BN and GN under small batch sizes, demonstrating improved stability and accuracy in low-batch settings. EBN achieves similar performance to BN with large batch sizes and outperforms BN with small batch sizes. EBN maintains higher and more stable accuracy than BN under small batch sizes, where BN performance degrades significantly. EBN consistently outperforms GN across all batch sizes and datasets, particularly in small batch scenarios.
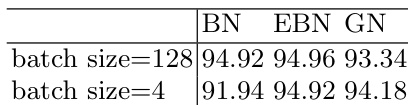
The authors compare extended batch normalization (EBN) with batch normalization (BN) and group normalization (GN) across multiple datasets and batch sizes. Results show that EBN maintains performance similar to BN under large batch sizes and outperforms both BN and GN under small batch sizes, demonstrating stability and adaptability across different conditions. EBN achieves comparable performance to BN under large batch sizes and outperforms BN under small batch sizes. EBN provides more stable results than BN when using small batch sizes, especially where BN shows significant fluctuation. EBN consistently performs better than GN across all batch sizes and datasets, with notable improvements in low batch size scenarios.
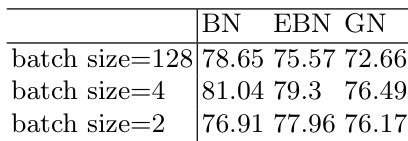
The authors compare extended batch normalization (EBN) with batch normalization (BN) and group normalization (GN) across multiple datasets and batch sizes. Results show that EBN maintains performance similar to BN under large batch sizes and outperforms both BN and GN under small batch sizes, particularly where BN struggles with instability and accuracy drops. EBN achieves performance comparable to BN under large batch sizes and outperforms BN under small batch sizes. EBN consistently outperforms GN across all batch sizes and datasets. EBN provides stable and high accuracy when BN fails due to small batch sizes, especially in MNIST and CIFAR experiments.
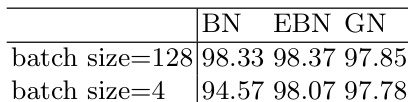
The authors compare extended batch normalization (EBN) with batch normalization (BN) and group normalization (GN) across multiple datasets and batch sizes. Results show that EBN maintains stable performance across different batch sizes, outperforming GN in small batch scenarios and achieving comparable results to BN in large batch settings. BN shows significant performance degradation with small batch sizes, while GN performs inconsistently across datasets and batch conditions. EBN achieves stable and superior performance compared to GN under small batch sizes. EBN maintains performance close to BN in large batch settings while avoiding the instability of BN with small batches. BN exhibits large fluctuations and performance drops with small batch sizes, whereas EBN and GN show more consistent results.
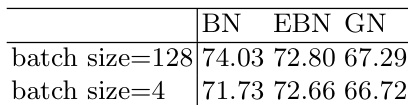
The authors compare extended batch normalization (EBN) with batch normalization (BN) and group normalization (GN) across multiple datasets and network architectures. Results show that EBN maintains performance similar to BN under large batch sizes and outperforms both BN and GN under small batch sizes, particularly in scenarios where BN's performance degrades significantly. EBN demonstrates stable and superior accuracy in low batch size conditions while preserving BN's advantages at larger scales. EBN maintains performance comparable to BN at large batch sizes and outperforms BN at small batch sizes. EBN achieves more stable and higher accuracy than BN and GN under small batch size conditions. EBN outperforms both BN and GN when batch size is reduced, especially in cases where BN's performance deteriorates significantly.
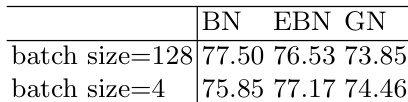
The authors evaluate extended batch normalization against standard batch and group normalization across multiple datasets, architectures, and batch sizes to assess training stability and accuracy under varying computational constraints. These experiments validate that extended batch normalization preserves the high performance of standard batch normalization at large batch sizes while effectively eliminating its characteristic accuracy drops and fluctuations in small batch settings. The method also consistently surpasses group normalization across all tested configurations, demonstrating robust adaptability and reliable convergence regardless of batch size. Ultimately, the findings establish extended batch normalization as a stable, versatile alternative that maintains large-scale efficiency while overcoming the limitations of traditional normalization techniques in low-batch scenarios.