Command Palette
Search for a command to run...
Code World Models for General Game Playing
Code World Models for General Game Playing
Abstract
Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach—involving prompting for direct move generation—has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model—comprising functions for state transition, legal move enumeration, and termination checks—serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in incomplete information games). We evaluate our approach across a diverse set of 20 games, including cooperative, imperfect information, and asymmetric games, and demonstrate that our method substantially outperforms direct LLM move generation and a generic reasoning baseline, achieving an 85% win rate compared to 30% and 45% for the baselines, respectively. Our code and data are available at https://sites.google.com/view/code-world-models.
One-sentence Summary
Code World Models uses large language models to translate natural language game rules into executable Python world models, and to generate heuristic value functions and inference functions for hidden states, enabling Monte Carlo tree search to achieve an 85% win rate across 20 diverse games, substantially exceeding the 30% and 45% win rates of direct LLM move generation and a generic reasoning baseline, respectively.
Key Contributions
- A method is introduced that translates natural language game rules and trajectories into executable Python code, producing a formal world model with state transition, legal move enumeration, and termination check functions to serve as a simulation engine for planning algorithms.
- The generated world model is extended by prompting the LLM to produce heuristic value functions for more efficient Monte Carlo tree search and inference functions to estimate hidden states in imperfect information games.
- Evaluated across 20 diverse games including cooperative, imperfect information, and asymmetric settings, the approach achieves an 85% win rate, substantially outperforming direct LLM move generation (30%) and a generic reasoning baseline (45%).
Introduction
Modern game-playing agents built on large language models typically treat the model as an end-to-end policy, prompting it to select moves directly from observed trajectories. While this leverages vast pattern-recognition capabilities, it struggles with strategic depth requiring multi-step lookahead and often fails on novel games outside the model’s training distribution. Prior work on LLM-based world models either assumes fully observed deterministic environments or post-hoc observability, sidestepping the harder challenge of partial observability and stochasticity.
The authors introduce Code World Models, an approach that uses LLMs as induction engines to synthesize executable Python models of game dynamics—including state transitions, legal moves, rewards, and termination conditions—from textual descriptions and limited gameplay data. For partially observable settings, they extend this to a regularized autoencoder paradigm where the LLM jointly generates an inference function that maps observations to latent histories and a decoder that reconstructs observations, with the game rules serving as structural regularizers. They further synthesize heuristic value functions to accelerate search, and demonstrate that planning with these learned models via MCTS or Information Set MCTS outperforms strong “thinking” LLM baselines on both classic and out-of-distribution two-player games.
Dataset
The authors construct a synthetic dataset of game implementations, inference problems, and unit tests to train models that can reason about hidden state and opponent intentions.
-
Dataset composition and sources
- The dataset draws on rule descriptions and code snippets from multiple two-player imperfect-information games: Tic-Tac-Toe, a 6x6 Connect-Four variant, Leduc poker, Quadranto, Hand of War, and a bargaining game with items X, Y, Z.
- It also includes generic board-game explanations (backgammon setup) and fixed sets of chance outcomes used for deterministic testing.
- Type aliases and game constants (
Action,State,PlayerObservation, winning lines, item sets) are defined in dedicated sections and reused across examples.
-
Key details for each subset
- Hidden history inference function synthesis (open deck): Provides a function signature that reconstructs a single player’s observations from an observation-action history. The accompanying unit test prints intermediate states and observations, and the last ten lines of standard output are given to the LLM together with the error message.
- Hidden state inference function synthesis: Defines
resample_state, which stochastically samples a reachable state consistent with the given observation-action history. The unit test verifies that the last observation matches the observation at the resampled state. - Bargaining game constants and opponent sampling: Defines item sets (
X, Y, Z), turn limits, and value ranges. Opponent private values are sampled randomly, and known offers are collected from theprevious_offerfield in the observation history. - Heuristic evaluation for non-terminal states: Extracts player-specific values, the pool, and offer history from the state dictionary to compute a value estimate.
-
How the paper uses the data
- The authors use the inference function definitions as target outputs for model training. Each example pairs a function signature with a unit test that exercises the inference.
- The training split mixes open-deck history reconstruction and hidden-state resampling, with the model learning to produce correct implementations from the given signatures and test code.
- Mixture ratios are not specified numerically, but the examples cover both fully observable history replay and partially observable state resampling.
-
Cropping, metadata, and other processing
- No explicit cropping strategy is described. The unit tests include print statements whose output is captured and appended to error feedback.
- Metadata such as
INITIAL_STATE, player IDs, and observation-action histories are provided as template variables inside the test code. - Opponent values are synthesized by random sampling, and offer histories are reconstructed by scanning the observation-action sequence for unique turn entries.
Method
The authors propose a general game-playing agent that shifts the burden on the LLM from producing a direct policy to producing a good world model. When confronted with a new game, the agent first plays a few games using a random policy to collect trajectories. It then uses the textual rules and these trajectories to synthesize a Code World Model.
Synthesizing the Code World Model The Code World Model is a playable, approximate copy of the target game implemented in Python. It contains deterministic functions for state transitions, legal move enumeration, observation generation, and reward calculation. To ensure correctness, the authors subject the initial LLM-generated model to iterative refinement. Unit tests are automatically generated from the offline trajectories to check the correctness of the model predictions. The authors employ two refinement strategies: a sequential chat mode where failed unit test stack traces are appended to the prompt, and a tree search approach using Thompson sampling to maintain and refine multiple model candidates.
Synthesizing Inference Functions for Imperfect Information Games For imperfect information games, the agent requires inference functions to estimate hidden states during planning. The authors prompt the LLM to generate code that approximately samples from the posterior belief state. They explore two approaches: hidden history inference, where the LLM samples a full action history including chance actions to recreate the hidden state, and hidden state inference, where the LLM directly samples the hidden state. The hidden history approach guarantees that the sampled state belongs to the support of the posterior and is a valid model state, whereas the direct state inference is simpler but lacks these guarantees.
Synthesizing Value Functions To accelerate planning, the authors also synthesize heuristic value functions. Unlike the world model, these functions cannot be refined against ground truth. Instead, the LLM generates multiple value function candidates, and the best one is selected through a tournament evaluation.
Planning with MCTS and ISMCTS During gameplay, the agent uses the synthesized world model as a simulation engine for planning. For perfect information games, standard Monte Carlo Tree Search is employed. For imperfect information games, the agent utilizes Information Set Monte Carlo Tree Search. In this method, simulations start from a distribution of possible ground truth states sampled by the inference function. Statistics such as value estimates and visit counts are maintained and aggregated at the level of information states, grouping histories that appear identical to the player.
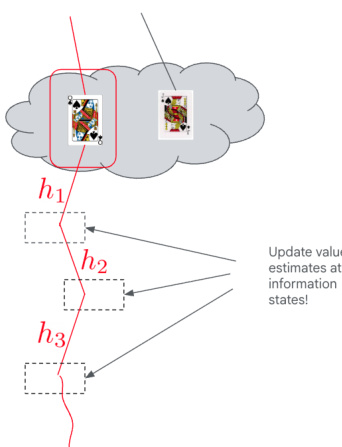
As shown in the figure above, the search tree is built over possible ground truth histories such as h1, h2, and h3. Because the player cannot distinguish between certain histories due to hidden information, represented by the cards in the cloud, value estimates and visit counts are aggregated at the information state level, indicated by the dotted boxes.
Amortizing Planning with PPO As an alternative to slow online planning, the authors investigate amortizing the planning computation into a reactive policy trained with Proximal Policy Optimization. The agent is trained entirely within the learned world model environment. For perfect information games, the actor-critic network uses shared fully connected layers. For imperfect information games, a recurrent neural network is added to process historical information. Observations in JSON format are mapped to 1D tensors using a programmatic mapping generated by the LLM.
Experiment
The experiments evaluate an agent that synthesizes a computational world model (CWM) from text rules and a few offline trajectories, then plans using Monte Carlo tree search. Synthesis accuracy is validated across both perfect and imperfect information games, including novel out-of-distribution games, with tree-search-based refinement proving more effective than conversational refinement. In gameplay, the CWM agent matches or outperforms a ground-truth planning agent and consistently beats a direct LLM policy, though synthesis struggles with procedurally complex games like Gin rummy. The closed-deck setting, where hidden information is never revealed, degrades synthesis quality but does not significantly harm final playing performance.
The authors evaluate the playing performance of their CWM-ISMCTS agent in imperfect information games against an LLM policy, a ground-truth ISMCTS agent, and a random agent. Results indicate that the synthesized agent generally achieves higher payoffs than the LLM-based policy and the random agent, while performing competitively against the ground-truth baseline. The CWM-ISMCTS agent consistently achieves positive payoffs against the random agent across all tested imperfect information games. When playing against the LLM policy, the agent secures higher average payoffs in Bargaining and Gin rummy, though performance varies in Leduc poker. Against the ground-truth ISMCTS baseline, the agent demonstrates competitive performance, with payoffs remaining relatively close in games like Leduc poker and Gin rummy.
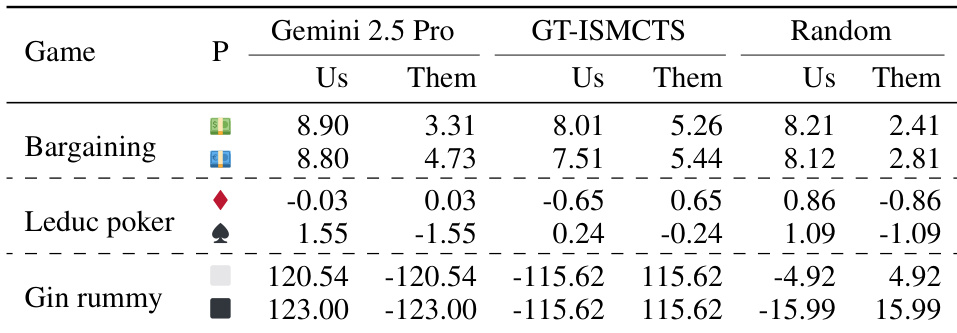
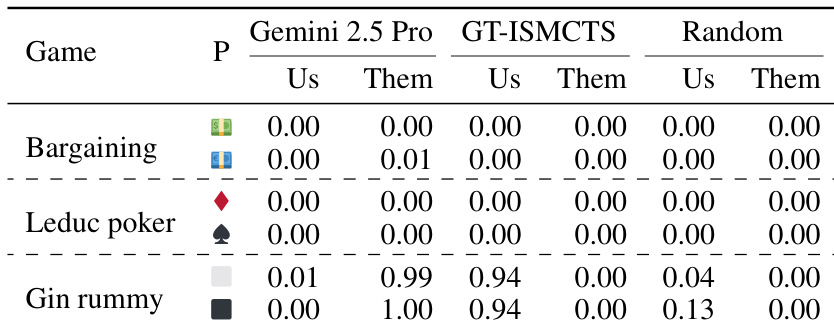
The authors evaluate their CWM-ISMCTS agent on imperfect information games including Bargaining, Leduc poker, and Gin rummy against an LLM policy, a ground-truth ISMCTS baseline, and a random agent. Results indicate that the synthesized agent performs comparably to the ground-truth baseline in Bargaining and Leduc poker, while achieving high payoffs against both the random agent and the ground-truth baseline in Gin rummy. The LLM policy struggles notably in Gin rummy, likely due to the game's complex procedural rules and high forfeit rates. The CWM-ISMCTS agent matches the performance of the ground-truth ISMCTS baseline in Bargaining and Leduc poker. The agent achieves substantially higher payoffs than the LLM policy in Gin rummy, highlighting the LLM's difficulty with complex game rules. Payoffs against the random agent are balanced in Bargaining and Leduc poker but clearly favor the CWM-ISMCTS agent in Gin rummy.
The authors evaluate the playing performance of their agent in imperfect information games against an LLM policy, a ground truth search agent, and a random agent. Results show the agent generally outperforms the LLM policy, achieving dominant win rates in Quadranto and competitive outcomes in Hand of war. Against the ground truth agent, the agent frequently draws in Quadranto, while matches against the random agent result in predominantly wins or draws. The agent achieves high win rates against the LLM policy in Quadranto, significantly outperforming its loss rates. Matches against the ground truth agent in Quadranto result in high draw rates, indicating competitive parity. The agent consistently secures wins or draws against the random agent across both tested games.

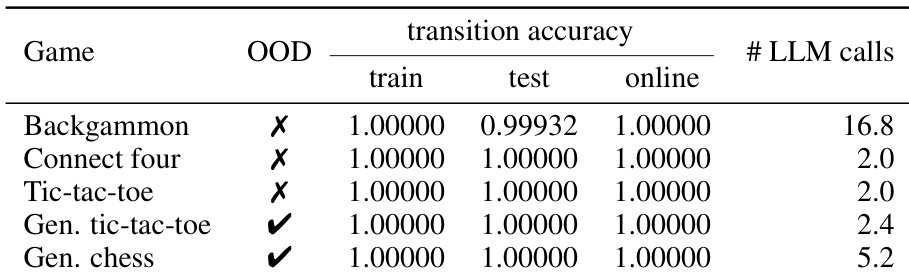
The authors evaluate the transition accuracy of synthesized Causal World Models for perfect information games using tree search refinement. The results demonstrate that the learned models achieve near-perfect accuracy across training, testing, and online phases for all evaluated games, including out-of-distribution ones. Furthermore, the synthesis process converges quickly, requiring a relatively small number of LLM calls to reach high performance. The synthesized models achieve perfect or near-perfect transition accuracy across train, test, and online evaluations for all perfect information games. Out-of-distribution games also reach maximum transition accuracy, demonstrating strong generalization capabilities. Tree search refinement enables rapid convergence, requiring very few LLM calls to synthesize accurate models for standard games.
The authors evaluate the synthesis accuracy of their agent on imperfect information games using open deck learning and hidden history inference. Results show that transition accuracy is generally very high across most games, though Gin rummy exhibits notably lower performance in both transition and inference accuracy due to its procedural complexity. While inference accuracy is near perfect for several games, it drops for Hand of war and significantly for Gin rummy, indicating that inferring hidden history is more challenging than learning transition dynamics. Transition accuracy is near perfect for most games, but Gin rummy shows lower accuracy and requires the maximum budget of LLM calls. Inference accuracy remains high for Bargaining, Leduc poker, and Quadranto, but degrades for Hand of war and is poorest for Gin rummy. The number of LLM calls varies widely across games, with Leduc poker converging quickly and Gin rummy exhausting the refinement budget.
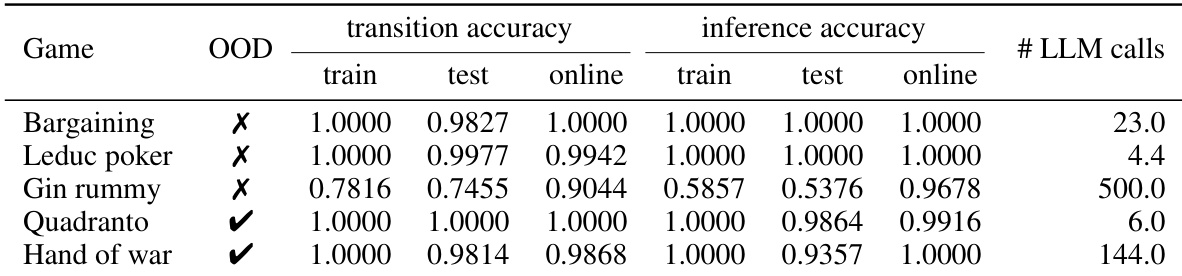
The evaluation covers both perfect and imperfect information games, testing the CWM-ISMCTS agent's playing performance against LLM, ground-truth search, and random baselines, as well as its model synthesis accuracy. In gameplay, the agent consistently outperforms the LLM policy and random agent, while achieving competitive parity with the ground-truth ISMCTS baseline, though the LLM struggles notably with procedurally complex games like Gin rummy. The synthesis process yields near-perfect transition accuracy for perfect information games and high accuracy for most imperfect information ones, with rapid convergence requiring few LLM calls, though inferring hidden history and modeling complex games like Gin rummy remain more challenging. Overall, the agent demonstrates strong generalization and competitive performance, with synthesis accuracy and gameplay success only degrading under high procedural complexity.