Command Palette
Search for a command to run...
PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
Yuqian Yuan Wenqiao Zhang Xin Li Shihao Wang Kehan Li Wentong Li Jun Xiao Lei Zhang Beng Chin Ooi
Abstract
Multimodal large language models (MLLMs) have demonstrated strong general-purpose capabilities in open-world visual comprehension. However, most existing MLLMs primarily focus on holistic, scenelevel understanding, often overlooking the need for fine-grained, object-centric reasoning. In this paper, we present PixelRefer, a unified region-level MLLM framework that enables advanced fine-grained understanding over user-specified regions across both images and videos. Motivated by the observation that LLM attention predominantly focuses on object-level tokens, we propose a Scale-Adaptive Object Tokenizer (SAOT) to generate compact and semantically rich object representations from free-form regions. Our analysis reveals that global visual tokens contribute mainly in early LLM layers, inspiring the design of PixelRefer-Lite, an efficient variant that employs an Object-Centric Infusion module to pre-fuse global context into object tokens. This yields a lightweight Object-Only Framework that substantially reduces computational cost while maintaining high semantic fidelity. To facilitate fine-grained instruction tuning, we curate PixelRefer-2.2M, a high-quality object-centric instruction dataset. Extensive experiments across a range of benchmarks validate that PixelRefer achieves leading performance with fewer training samples, while PixelRefer-Lite offers competitive accuracy with notable gains in efficiency.
One-sentence Summary
Zhejiang University, DAMO Academy, Alibaba Group, et al. propose PixelRefer, a unified multimodal framework that enables fine-grained spatio-temporal object referring in both images and videos by using a Scale-Adaptive Object Tokenizer (SAOT) to generate compact, semantically rich object representations and an Object-Centric Infusion module in PixelRefer-Lite for efficient global context pre-fusion, surpassing previous methods with fewer training samples on the curated PixelRefer-2.2M dataset.
Key Contributions
- PixelRefer, a unified region-level multimodal large language model, uses a Scale-Adaptive Object Tokenizer (SAOT) to generate compact, semantically rich object representations from free-form regions, enabling fine-grained spatiotemporal object-centric understanding across images and videos.
- An efficient variant, PixelRefer-Lite, incorporates an Object-Centric Infusion module that pre-fuses global visual context into object tokens, forming an Object-Only Framework that substantially reduces computational cost while maintaining high semantic fidelity.
- A curated object-centric instruction dataset, PixelRefer-2.2M, supports training. Experiments demonstrate PixelRefer achieves leading performance on tasks from captioning to complex reasoning with fewer training samples, while PixelRefer-Lite offers competitive accuracy with notable efficiency gains.
Introduction
Multi-modal large language models (MLLMs) achieve strong holistic visual comprehension but often overlook fine-grained, object-centric understanding, which is essential for applications such as embodied AI and medical diagnostics. Prior methods for region-level reasoning are hampered by ambiguous visual markers, computational inefficiency from repeated encoding, or a narrow focus on captioning that sacrifices the general-purpose versatility of MLLMs. The authors propose PixelRefer, a unified framework that injects compact, semantically rich region representations into a general-purpose MLLM backbone to support a broad range of object-centric referring tasks across images and videos. Central to their approach is a Scale-Adaptive Object Tokenizer that produces precise object tokens from free-form regions. An empirical analysis of attention patterns motivates PixelRefer-Lite, an efficient Object-Only variant that pre-fuses global visual context into object tokens, dramatically lowering computational cost. They further introduce a curated instruction dataset, PixelRefer-2.2M, and demonstrate state-of-the-art performance with greater data efficiency.
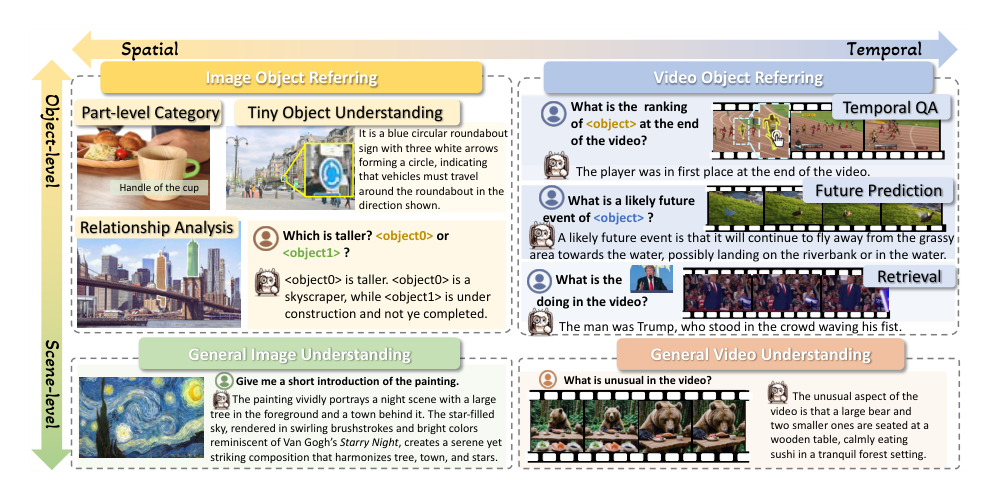
Dataset
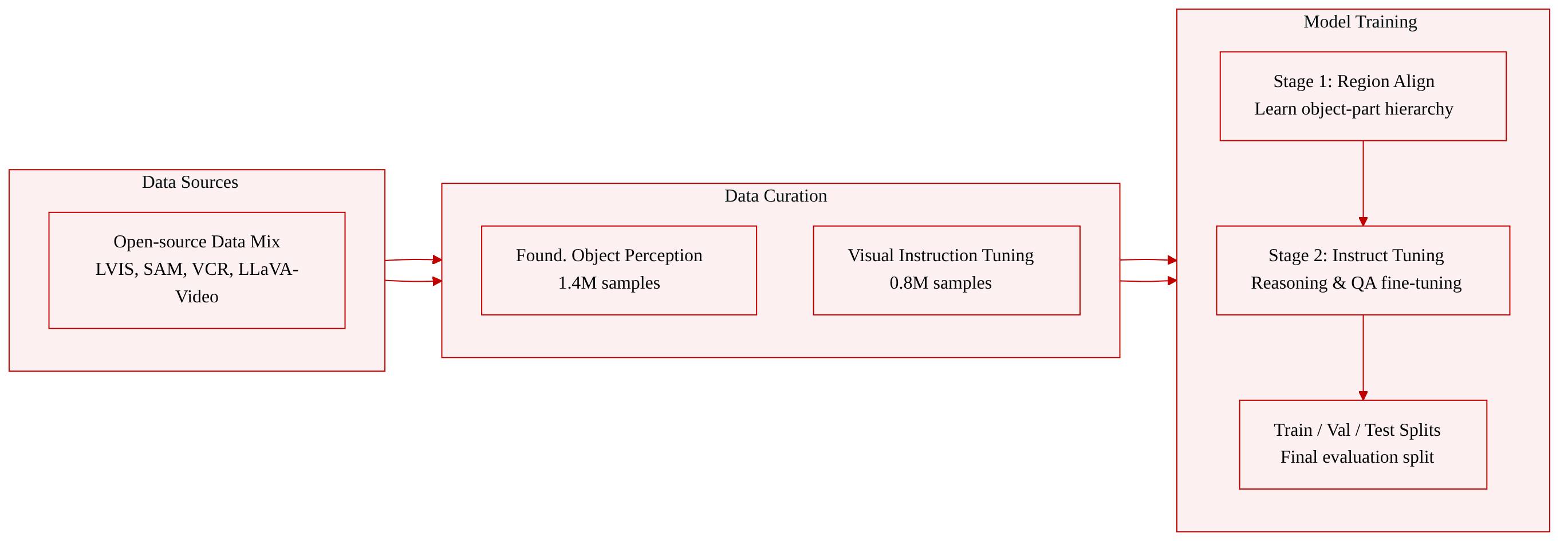
The authors curate a diverse collection of open-source datasets and organize them into two complementary stages for model training:
Foundational Object Perception (1.4M samples) Used to strengthen fine-grained regional alignment before instruction tuning. It contains three subsets:
- Region Recognition – Combines object-level annotations from LVIS, Visual Genome, RefCOCO/RefCOCO+ with part-level datasets (PACO, Pascal-Part, PartImageNet) to enable hierarchical learning from whole objects to parts, plus temporal cues from VideoRefer-Short captions and MEVIS for dynamic scenes.
- Regional Image Detailed Caption – Aggregates dense caption samples built from SAM, OpenImages, LVIS, COCO-Stuff, Mapillary, PACO, along with richer narratives from Osprey-caption and MDVP-Data.
- Regional Video Detailed Caption – Leverages self-constructed VideoRefer-Detailed captions, DAM-SAV, and HC-STVG to supply temporal and contextual supervision in videos.
Visual Instruction Tuning (0.8M samples) Designed to teach the model instruction-following and reasoning grounded in visual inputs. Subsets:
- Image Region QA – Osprey-QA, MDVP-LVIS, MDVP-PACO (all annotated with GPT-4/GPT-4o), plus VCR for commonsense and causal reasoning over visual contexts.
- Video Object QA – 75K VideoRefer-QA samples constructed via a multi-agent pipeline, providing object-centric question-answer pairs that require reasoning about object identity, attributes, and interactions across time.
- Region Caption – 250K regional captions sampled from Foundational Object Perception data, bridging perceptual pretraining and instruction tuning.
- General QA – Open-ended queries sampled from LLaVA-Video and LLaVA-OV to broaden instruction-following to non-regional tasks.
The data is used for the visual instruction tuning phase (Stage 2) of model training, with the foundational perception data applied first to instill robust regional understanding, followed by the instruction tuning data to equip the model with diverse reasoning and captioning capabilities.
Method
The authors conduct an empirical analysis of attention distributions across LLM layers to understand how object tokens are utilized. As shown in the figure below, answer tokens consistently exhibit stronger attention toward object tokens than global visual tokens across all layers, indicating that object tokens serve as the primary semantic anchor for question answering.
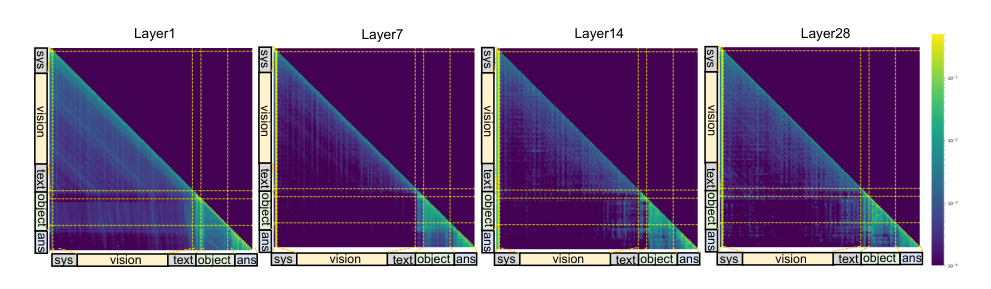
Furthermore, answer tokens exhibit sparse attention to global image tokens. To assess the interpretability of this selection, the authors visualize answer-to-image attention distributions across different queried regions, revealing that the model adaptively highlights semantically aligned object areas while occasionally incorporating contextual cues from broader spatial contexts.
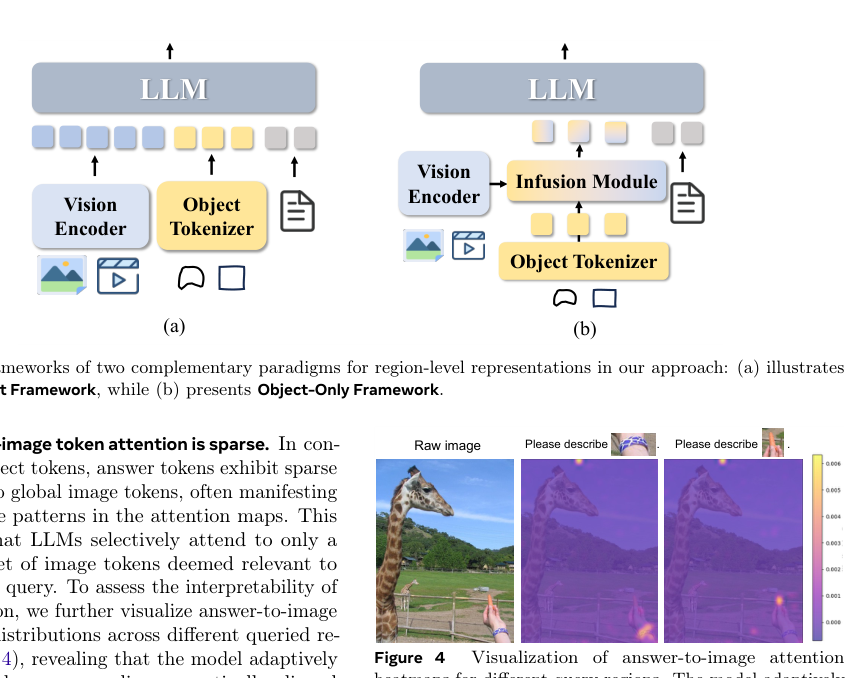
Motivated by these insights, the authors propose two complementary paradigms: PixelRefer, based on the Vision-Object Framework, and PixelRefer-Lite, based on the Object-Only Framework. The Vision-Object Framework comprises a vision encoder, an object tokenizer, a text tokenizer, and an instruction-following LLM. Given a video V∈RN×H×W×C, the vision encoder Ev extracts a feature map Z, encoding spatial-temporal scene-level information as visual tokens TZ. For a set of user-specified regions R={R1,R2,…,Rn}, the object tokenizer ER generates object tokens TR=ER(R,Z). These are jointly fed into the LLM: Y=Φ(TZ,TR,TX).
To generate accurate object tokens across different scales, the authors introduce a Scale-Adaptive Object Tokenizer (SAOT). Unlike naive pooling strategies, SAOT dynamically adjusts region scale to handle scale variations and preserve spatial context.
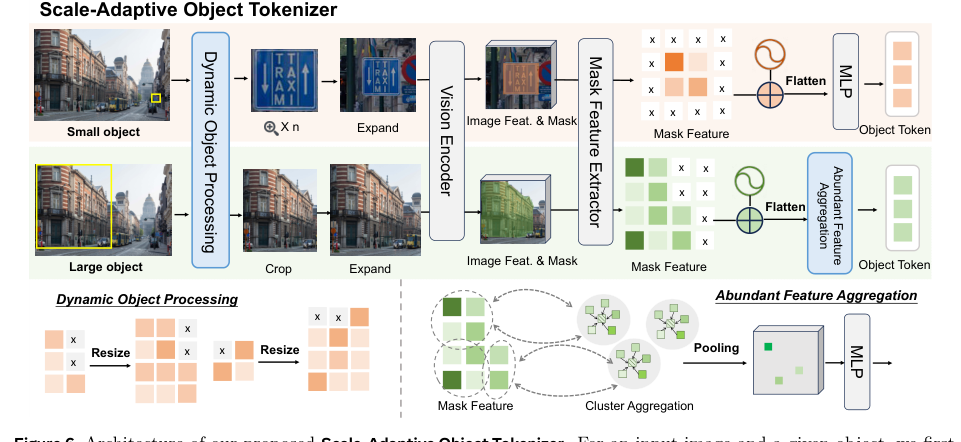
Given an input image I∈R3×HI×WI and a binary mask M, the method computes a scaling ratio s: s=⎩⎨⎧∣M∣Ω⋅100,∣M∣Ω⋅n,1,if ∣M∣>100⋅Ωelseif ∣M∣<n⋅Ωotherwise where ∣M∣ is the number of foreground pixels, Ω is the patch size, and n is the number of tokens per object. Small objects are upscaled and large objects are downscaled. Contextual padding is applied, and masked spatial features FM=FR⊙M are extracted. Relative positional encoding is introduced to alleviate localization ambiguity: FMP=(FM+Linear(pi,j))[M=1] To mitigate redundancy in large or homogeneous regions, the authors employ an Abundant Feature Aggregation strategy using k-means clustering.
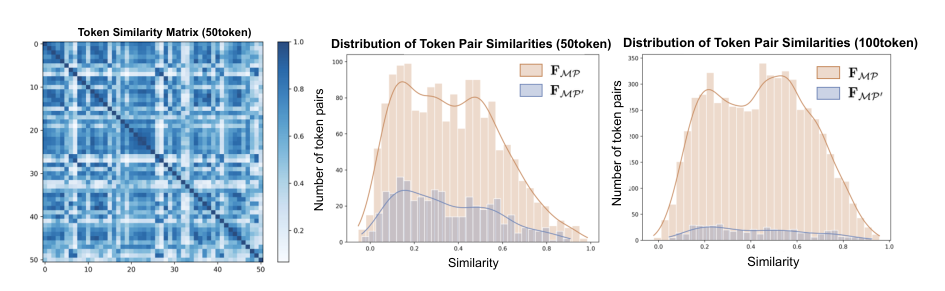
The mean embedding of each cluster Ci is preserved: FMP′=∣Ci∣1∑j∈CiFMPj. An MLP then generates the final object tokens.
Since attention to global visual tokens is concentrated in early LLM layers, the authors propose PixelRefer-Lite to reduce computational overhead. The Object-Only Framework incorporates a lightweight infusion module to integrate global visual context TZ into object tokens TR: TO=Ψ(TR,TZ). The refined tokens are decoded as Y=Φ(TO,TX). The Object-Centric Infusion (OCI) module uses a two-step cross-attention strategy. Local-to-Object Attention injects fine-grained embeddings from locally expanded regions, and Global-to-Object Attention conditions object tokens on scene-level embeddings. For videos, timestamp embeddings are prepended to object tokens.
The authors employ a two-stage training process. First, they strengthen fine-grained regional alignment using Foundational Object Perception Data, totaling 1.4M samples across region recognition, regional image detailed caption, and regional video detailed caption.
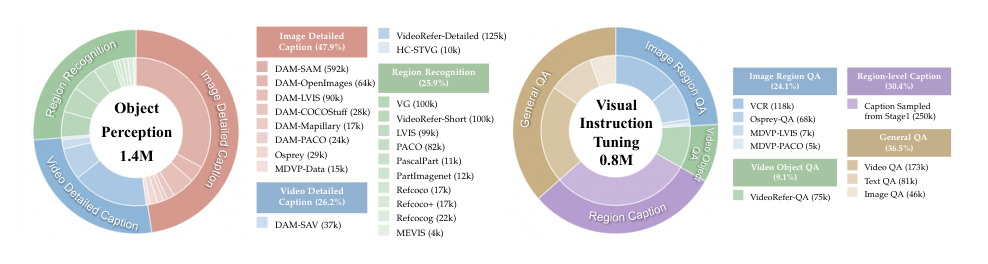
Second, they perform Visual Instruction Tuning using 0.8M samples, including Image Region QA, Video Object QA, Region Caption, and General QA, to endow the model with instruction-following and reasoning capabilities.
Experiment
The experiments evaluate PixelRefer, a model built upon VideoLLaMA 3 with a scale-adaptive object tokenizer, across image and video region understanding tasks including category recognition, captioning, and question answering. Results demonstrate state-of-the-art performance on fine-grained benchmarks, while the Object-Only framework offers substantial reductions in computational cost with minimal accuracy loss. Ablation studies validate the benefits of the tokenizer’s adaptive scaling, object-centric context infusion, and diverse training data for robust region-level perception.
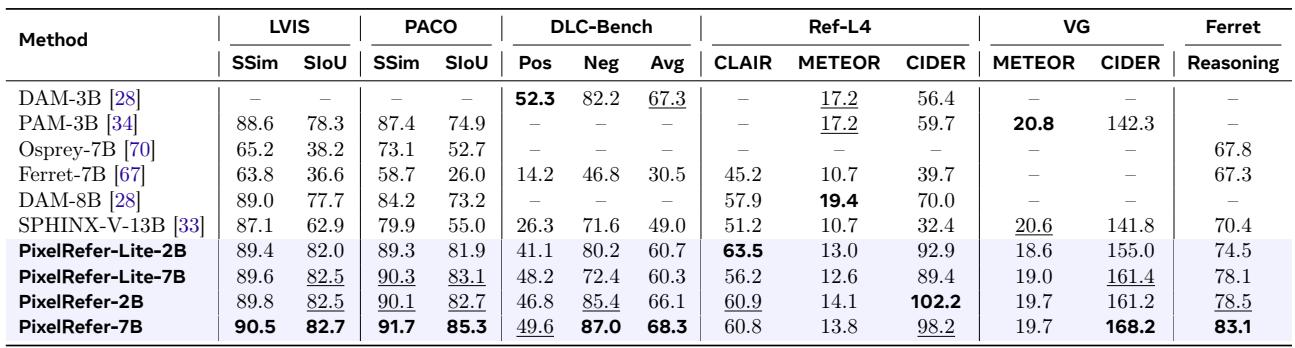
PixelRefer models achieve state-of-the-art results across diverse image-level region understanding benchmarks, excelling in part-level category recognition, detailed captioning, and phrase-level description. The largest PixelRefer-7B sets new bests on PACO and DLC-Bench, while lightweight variants surpass previous top models by significant margins, especially in semantic IoU and CIDER scores. Phrase-level captioning shows dramatic improvement on VG and Ref-L4, highlighting strong fine-grained region description capabilities. On the challenging PACO benchmark, which includes both objects and small part-level regions, PixelRefer-7B improves semantic IoU by over 10 points compared to the prior best model, and even the lightweight version outperforms the previous state of the art. PixelRefer-2B, in a zero-shot phrase captioning evaluation on Ref-L4, raises CIDER by 32% relative to the previous best, while the largest model more than doubles the VG CIDER score of earlier approaches.
Among generalist models using single-frame masks on VideoRefer-BenchD, GPT-4o achieved the highest average score, excelling in action, temporal, and holistic description. InternVL2-26B led in spatial captioning but placed second overall, while Qwen2-VL-7B, LLaVA-OV-7B, and LongVA-7B clustered closely behind. InternVL2-26B achieved the top score in spatial captioning (3.55), outperforming GPT-4o (3.34) and other generalist models. GPT-4o obtained the highest average performance (2.95) and ranked first in action description, temporal description, and holistic description among the compared generalist models.
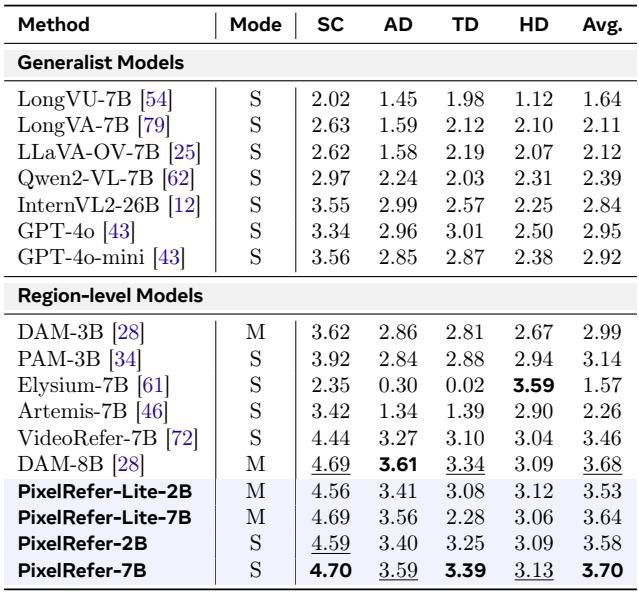
On the HC-STVG video description benchmark, PixelRefer-7B surpasses the previous best method DAM-8B across all metrics, with a particularly large 6.1-point CIDER gain. A lightweight variant, PixelRefer-Lite-7B, achieves comparable performance while being more efficient. PixelRefer-7B obtains a CIDER of 97.4, improving over DAM-8B's 91.0, alongside consistent gains in METEOR, BLEU@4, ROUGE-L, and SPICE. The 3B-parameter PAM-3B leads in METEOR (23.3) among prior methods but falls short in CIDER (70.3), revealing a metric trade-off that PixelRefer resolves.
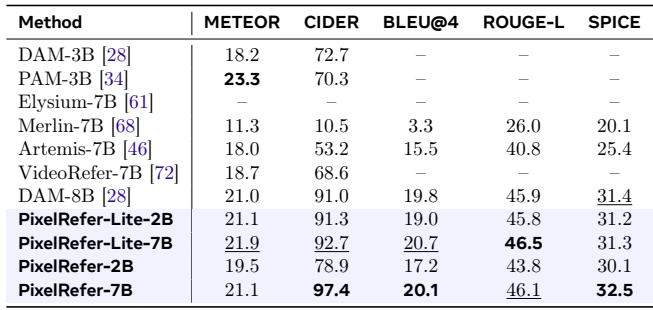
PixelRefer sets a new state of the art on the VideoRefer-BenchQ video question-answering benchmark, achieving the highest average accuracy among all models. It outperforms both open-source generalist models and proprietary systems like GPT-4o, with particularly strong results on reasoning and future prediction questions. The performance gains highlight the model's superior ability to answer dynamic, context-aware queries about referred video regions. PixelRefer exceeds the closed-source GPT-4o model by 8.1 percentage points in average accuracy on VideoRefer-BenchQ. It achieves leading scores across all question types, notably 89.5% on Reasoning Questions and 79.7% on Future Prediction.
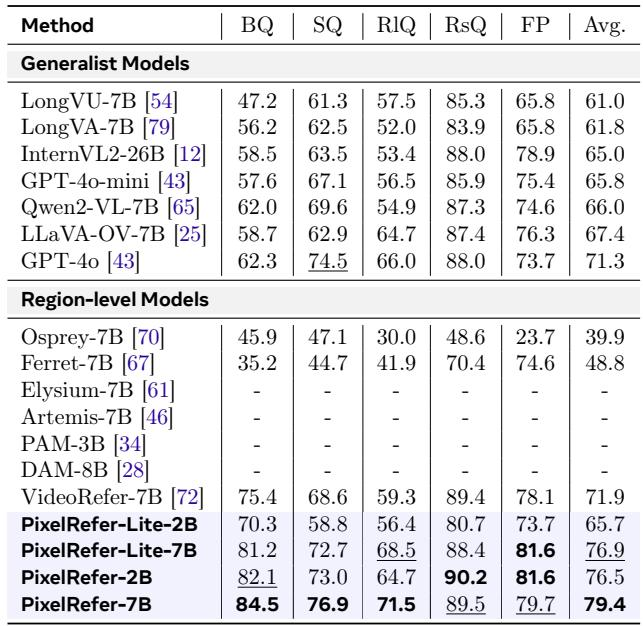
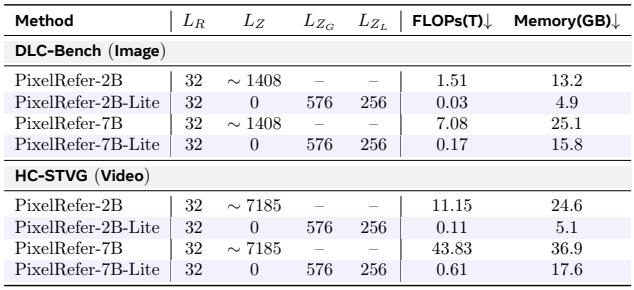
Applying the Object-Only Framework yields dramatic reductions in compute and memory, with efficiency gains consistent across model sizes and both image and video settings. Lite variants cut FLOPs by roughly two orders of magnitude, while memory usage drops to a fraction of the full model's demands, making the approach highly scalable. Video inference with PixelRefer-2B-Lite uses only 0.11T FLOPs and 5.1 GB memory, compared to 11.15T FLOPs and 24.6 GB for the standard 2B model, a roughly 99% and 79% reduction respectively. The efficiency pattern holds across scales: PixelRefer-7B-Lite achieves 0.17T FLOPs and 15.8 GB on images versus 7.08T FLOPs and 25.1 GB for the full 7B model.
PixelRefer models are evaluated across a broad set of region-level understanding tasks including image part recognition, phrase captioning, video description, and video question answering. The largest PixelRefer-7B establishes new state-of-the-art results, surpassing both open-source generalist models and proprietary systems such as GPT-4o, with notable strengths in fine-grained description and reasoning. Lightweight variants built with the Object-Only Framework maintain competitive performance while reducing computational cost by roughly two orders of magnitude, demonstrating the approach's scalability and efficiency.