Command Palette
Search for a command to run...
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Peiqing Yang Shangchen Zhou Kai Hao Qingyi Tao
Abstract
Video matting remains limited by the scale and realism of existing datasets. While leveraging segmentation data can enhance semantic stability, the lack of effective boundary supervision often leads to segmentation-like mattes lacking fine details. To this end, we introduce a learned Matting Quality Evaluator (MQE) that assesses semantic and boundary quality of alpha mattes without ground truth. It produces a pixel-wise evaluation map that identifies reliable and erroneous regions, enabling fine-grained quality assessment. The MQE scales up video matting in two ways: (1) as an online matting-quality feedback during training to suppress erroneous regions, providing comprehensive supervision, and (2) as an offline selection module for data curation, improving annotation quality by combining the strengths of leading video and image matting models. This process allows us to build a large-scale real-world video matting dataset, VMReal, containing 28K clips and 2.4M frames. To handle large appearance variations in long videos, we introduce a reference-frame training strategy that incorporates long-range frames beyond the local window for effective training. Our MatAnyone 2 achieves stateof-the-art performance on both synthetic and real-world benchmarks, surpassing prior methods across all metrics.
One-sentence Summary
MatAnyone 2, a video matting framework proposed by a team from Nanyang Technological University and SenseTime Research, leverages a learned Matting Quality Evaluator (MQE) that provides pixel-wise quality feedback during training and curates the large-scale real-world dataset VMReal, and incorporates a reference-frame training strategy to achieve state-of-the-art performance on both synthetic and real-world benchmarks.
Key Contributions
- A learned Matting Quality Evaluator (MQE) generates pixel-wise quality maps for alpha mattes without ground truth, jointly assessing semantic accuracy and boundary detail.
- Leveraging the MQE as an offline curation tool constructs VMReal, the first large-scale real-world video matting dataset containing 28K clips and 2.4M frames with diverse, high-quality annotations.
- A reference-frame training strategy incorporating long-range frames beyond the local window is introduced to handle large appearance variations, and the resulting MatAnyone 2 model achieves state-of-the-art performance on synthetic and real-world benchmarks, surpassing prior methods across all metrics.
Introduction
Video matting is essential for visual effects and video editing but remains challenging due to blurry boundaries, missing regions, and tracking instability. A core bottleneck is the limited scale and realism of existing matting datasets: the largest current collection contains only around 800 synthetic sequences, far smaller than segmentation datasets, and composite-based augmentation introduces lighting inconsistencies and unnatural edges that create a domain gap from real footage. Prior attempts to incorporate segmentation priors via pretraining or joint training struggle to transfer fine boundary detail; pretrained features degrade during finetuning on scarce matting data, while joint training with mask supervision often produces segmentation-like outputs with weak boundary quality. The authors address these issues by introducing a learned Matting Quality Evaluator (MQE) that assesses both semantic accuracy and boundary fidelity without requiring ground-truth alpha mattes. Using this evaluator as an online guidance signal and an offline curation module, they construct VMReal, a large-scale real-world video matting dataset with roughly 28,000 clips, and propose a reference-frame training strategy to handle long-duration appearance changes. These contributions form MatAnyone 2, which significantly improves semantic stability, edge sharpness, and real-world generalization.

Dataset
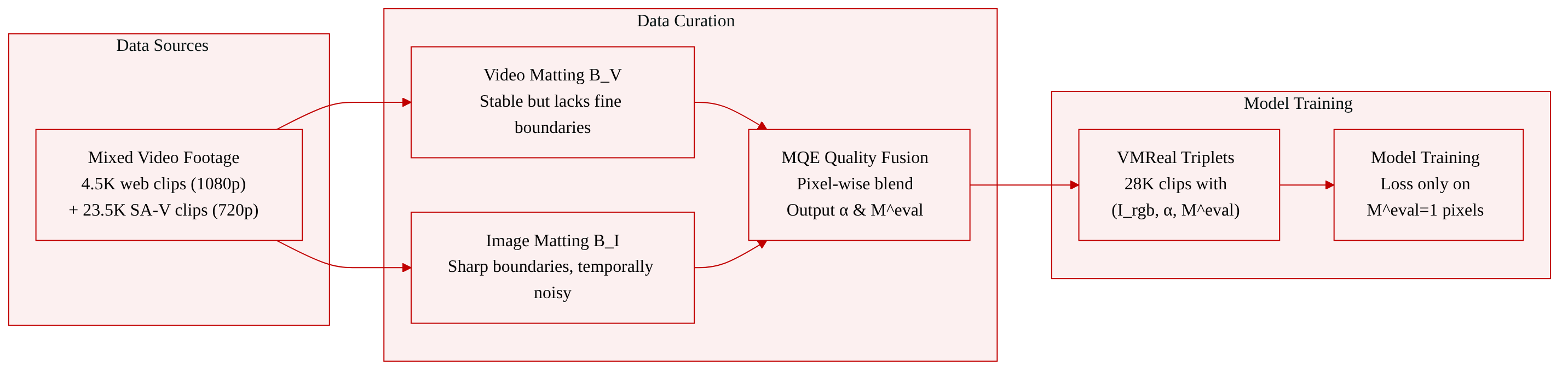
The authors construct VMReal, a large-scale, real-world video matting dataset automatically annotated through a dual-branch pipeline guided by the learned MQE (matting quality evaluator). The dataset contains about 28,000 clips (2.4 million frames), roughly 35× larger than prior video matting datasets.
- Composition and sources VMReal is built from two subsets:
- A high-quality subset of 4,500 clips sourced from video footage websites and YouTube, recorded at 1080p resolution, with abundant fine-grained hair details (human‑centric scenes).
- The remaining clips are drawn from the SA‑V dataset after filtering out a human‑centric subset, typically at 720p resolution; these provide diverse scenes, motions, and lighting conditions to complement the portrait‑heavy subset.
- Automated annotation pipeline For each video, two branches generate complementary alpha predictions:
- Branch B_V (video matting model, e.g., MatAnyone) delivers temporally stable mattes but sometimes misses fine boundary details.
- Branch B_I (image matting model, e.g., MattePro, guided by SAM2 per‑frame masks) produces sharp boundaries but lacks temporal consistency.
- The pre‑trained MQE acts as a quality arbiter, producing per‑pixel evaluation maps M_V^eval and M_I^eval that indicate reliable regions. A fusion mask M^fuse = M_I^eval ⊙ (1 − M_V^eval) identifies pixels where B_V is unreliable and B_I is confident. After Gaussian smoothing, the final alpha is blended: α = α_V ⊙ (1 − M^fuse) + α_I ⊙ M^fuse. The fused evaluation map M^eval = M_V^eval ∪ M_I^eval marks all trustworthy pixels.
- Every frame is stored as a triplet (I_rgb, α, M^eval).
-
How the data is used The authors train exclusively on VMReal, avoiding joint training with segmentation data. Losses are computed only on pixels where M^eval = 1, so supervision concentrates on high‑confidence regions and ignores uncertain or low‑quality areas. This strategy preserves fine boundary details and prevents segmentation‑like artifacts.
-
Additional processing details No cropping or resolution changes are applied beyond the native source formats. The per‑frame evaluation map serves as built‑in metadata for pixel‑wise loss masking and does not require manual cleanup.
Method
The authors propose MatAnyone 2 to address the limitations of previous video matting approaches, specifically the trade-off between semantic accuracy and boundary fidelity. Previous work, MatAnyone, improved matting by jointly training with segmentation data. However, segmentation data only provides reliable supervision for non-boundary regions, leading to weak boundary constraints and segmentation-like mattes. To overcome this, the authors introduce a novel Matting Quality Evaluator (MQE) that provides effective supervision for both regions without requiring matting ground truth.
Refer to the framework diagram below for a comparison of the training pipelines:
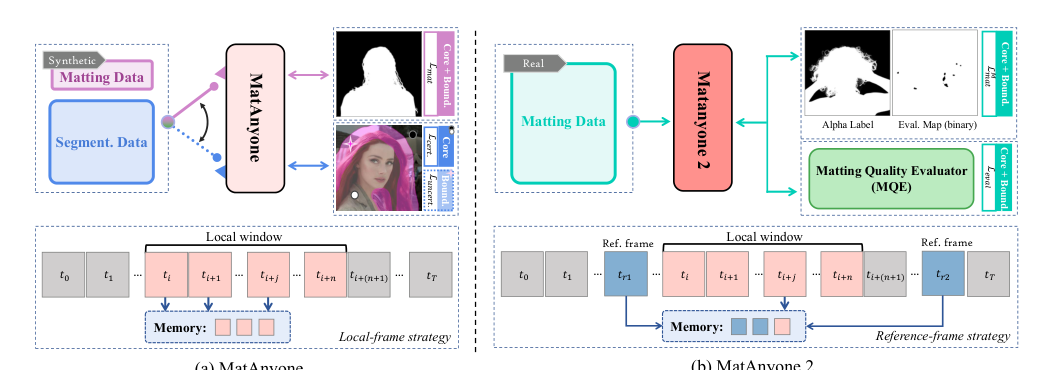
The proposed architecture shifts from synthetic matting and segmentation data to real matting data guided by the MQE. This approach allows the model to achieve higher semantic accuracy while preserving fine boundary details. As shown in the visual comparison below, MatAnyone 2 significantly outperforms prior methods in preserving fine details like hair strands and avoiding segmentation-like boundaries, while also showing enhanced robustness under challenging lighting conditions.
Online Matting-quality Guidance The authors leverage the learned MQE model as a dynamic feedback signal during training. For each input frame, the MQE produces a probability map Peval(0) indicating the pixel-wise likelihood of error in the alpha prediction. This map serves as a penalty mask to guide the network in suppressing erroneous regions. The online guidance loss is defined as:
Leval=∥Peval(0)∥1
This loss encourages lower error probabilities, providing a more effective and stable learning signal for boundary regions compared to the weak unsupervised loss used in previous methods.
Offline Pixel-wise Selection and Data Curation Beyond online guidance, the authors employ the MQE to construct a large-scale real-world video matting dataset, VMReal, through an automated dual-branch annotation pipeline. Manual annotation is prohibitively expensive, so the pipeline combines two complementary branches. The first branch (BV) uses a video matting model to ensure stable temporal consistency and robust structure. The second branch (BI) uses an image matting model guided by segmentation masks to produce sharper boundary details.
As shown in the figure below, the MQE acts as a quality arbiter to fuse these predictions:
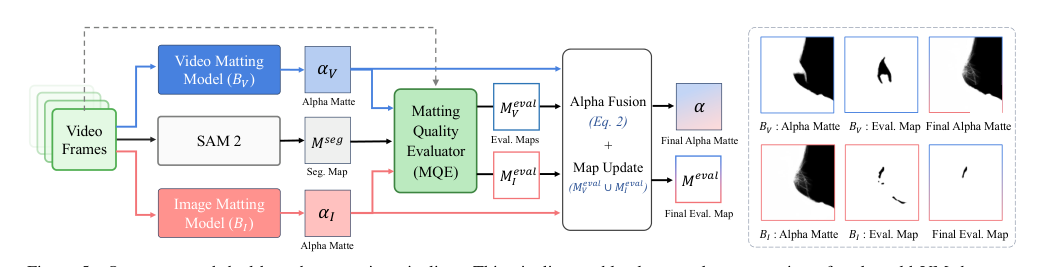
The system generates evaluation maps MVeval and MIeval for both branches. It takes the stable predictions from BV as the base and selectively integrates boundary details from BI where BV is unreliable (MVeval=0) but BI is reliable (MIeval=1). A fusion mask Mfuse=MIeval⊙(1−MVeval) is computed and smoothed with a Gaussian blur to avoid artifacts. The final fused alpha matte is obtained by:
α=αV⊙(1−Mfuse)+αI⊙Mfuse
This unified training scheme uses triplets ⟨Irgb,α,Meval⟩, where the matting loss is computed only over reliable regions (Meval=1).
Reference-Frame Strategy for Long Videos In long videos, subject appearance can vary significantly. Previous methods relying on memory propagation often fail to matte newly appearing parts because training is restricted to short sequences (local windows). Simply extending the window increases memory consumption. To solve this, the authors propose a reference-frame strategy that introduces long-range reference frames into memory beyond the local training window. This extends the temporal context without additional memory overhead. To further strengthen this, a random dropout augmentation masks patches in RGB and alpha maps, mitigating over-reliance on historical memory. This strategy effectively handles large appearance variations, allowing the model to robustly identify newly appearing subject regions, as demonstrated in the figure below.

Experiment
To improve video matting, the paper introduce a pixel-wise Matting Quality Evaluator (MQE) that reliably identifies erroneous regions in predicted alpha mattes, leveraging segmentation guidance and DINOv3 features. This MQE enables online training supervision and the construction of a large-scale real-world video matting dataset (VMReal), leading to the MatAnyone 2 model. MatAnyone 2 achieves state-of-the-art performance on both synthetic and real-world benchmarks, delivering superior semantic robustness, fine boundary details, and temporal consistency. Ablation studies confirm that both the online MQE guidance and training on VMReal significantly improve matting quality, particularly under challenging conditions like complex lighting and wind-blown hair.
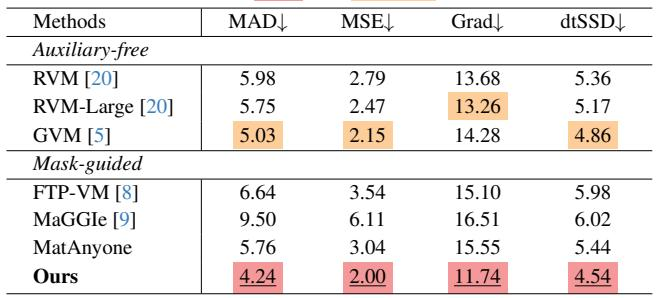
On the VideoMatte benchmark, the proposed purely CNN-based method outperforms all previous approaches across every metric, despite using only a first-frame mask and no diffusion prior. It reduces the gradient and connectivity errors by over 20% relative to the prior best mask-guided model, and it achieves better temporal coherence and semantic accuracy than methods that rely on per-frame instance masks or diffusion-based priors. Achieves the lowest MAD, MSE, Grad, dtSSD, and Conn on VideoMatte, marking the best overall performance among all compared methods. Reduces Grad and Conn errors by 27.1% and 22.4% respectively compared to the leading mask-guided MatAnyone model. Outperforms the diffusion-based GVM and the per-frame mask-guided MaGGIe while using only a standard CNN and a first-frame instance mask.
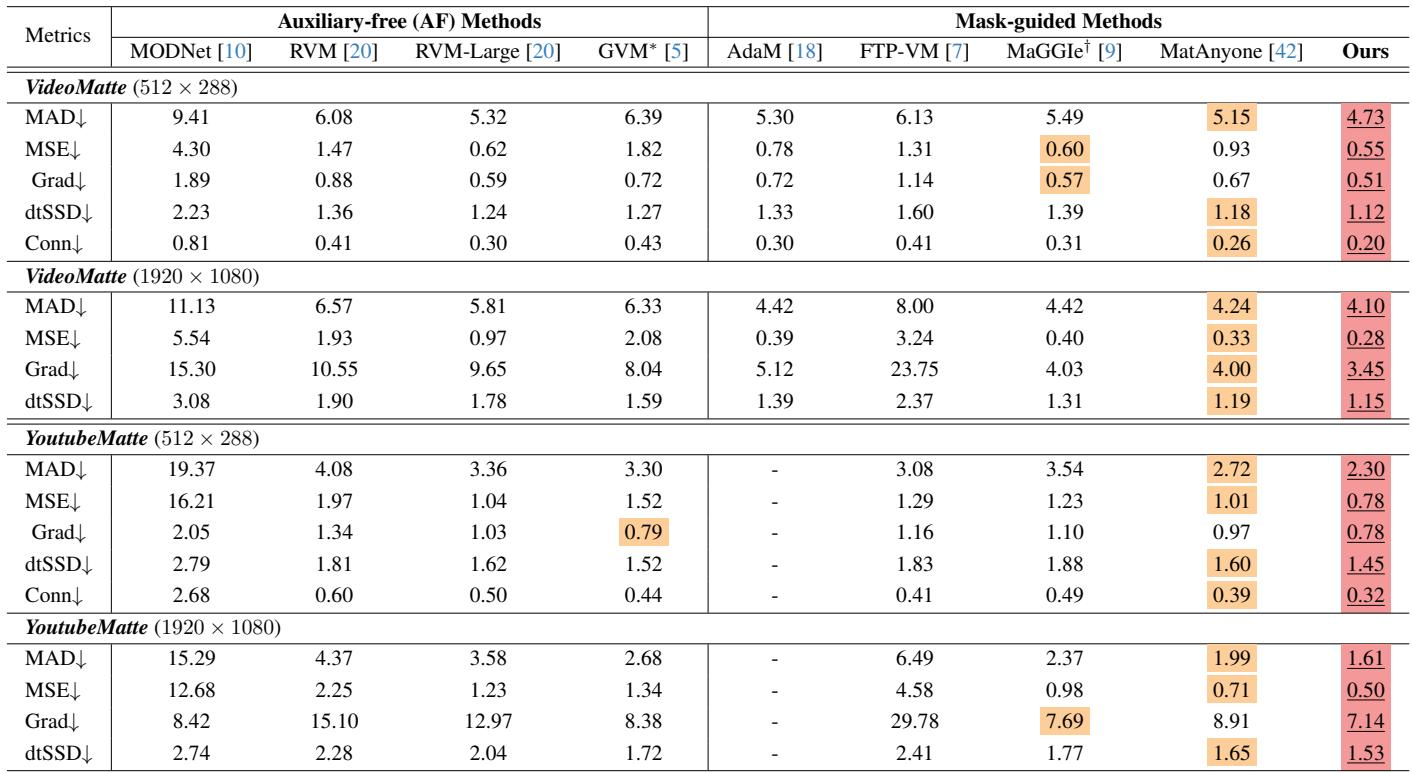
On the real-world CRGNN dataset, the proposed MatAnyone 2 achieves the best performance across all four metrics, substantially improving semantic accuracy, fine details, and temporal consistency over the previous MatAnyone. GVM's diffusion prior yields competitive results, but MatAnyone 2 still outperforms it in every measure. Auxiliary-free methods trail the mask-guided approaches. MatAnyone 2 attains the top scores in MAD, MSE, Grad, and dtSSD, surpassing all compared methods on this real-world benchmark. GVM exhibits strong performance due to its diffusion prior, yet MatAnyone 2 exceeds it on all metrics, including detail fidelity (Grad) and temporal coherence (dtSSD). Relative to MatAnyone, the new model shows marked improvements, confirming enhanced semantic accuracy and finer matting details under challenging real-world conditions like wind-blown hair and complex lighting.
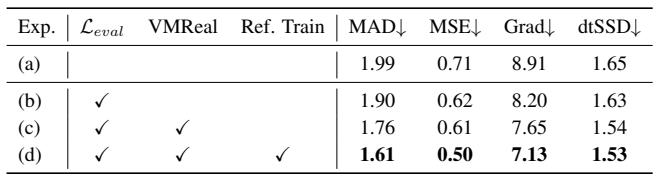
Adding online matting-quality guidance reduces semantic and boundary errors over the baseline. Incorporating the VMReal dataset brings further gains in temporal consistency and detail fidelity, while the reference-frame training strategy yields additional semantic robustness without increasing memory cost. Online guidance alone lowers MAD, MSE, and gradient error, showing improved semantic accuracy and edge detail fidelity. Training with VMReal and the reference-frame strategy together leads to the lowest MAD and MSE, indicating strong robustness to appearance changes and stable temporal quality.
MatAnyone 2, a purely CNN-based model that uses only a first-frame instance mask, is evaluated on the synthetic VideoMatte and real-world CRGNN benchmarks. It surpasses all prior methods, including diffusion-based and per-frame mask-guided approaches, delivering better semantic accuracy, fine-detail fidelity, and temporal consistency. Ablation studies show that online matting-quality guidance, the VMReal dataset, and a reference-frame training strategy each reduce semantic and boundary errors while improving robustness, and combining them yields the strongest temporal quality and appearance stability.